前沿 | BAIR展示新型模仿学习,学会「像人」那样执行任务
选自BAIR
作者:Tianhe Yu、Chelsea Finn
机器之心编译
参与:乾树、思源
很多机器人都是通过物理控制以及大量演示才能学习一个任务,而最近 UC 伯克利的 BAIR 实验室发表文章介绍了一种单例模仿学习的方法。这种方法结合了模仿学习与元学习,并可以在观察人类的动作后学习像人那样操作物体。
通过观察另一个人来学习新技能的模仿能力,是体现人类和动物智能的关键部分。我们是否可以让一个机器人做同样的事情?通过观察人类操作物体进而学会操作一个新的物体,就像下面视频中一样。


机器人在观摩人类动作后学会将桃放入红碗中。
这种能力会使我们更容易将新目标与知识传达给机器人,我们可以简单地向机器人展示我们希望它们做什么,而不是遥控操作机器人或设计激励函数(这是一种困难的方法,因为它需要一个完整的感知系统)。
以前许多的工作已经研究了机器人如何从人类专家那里学习(即通过遥控操作或运动知觉教学),这通常被称为模仿学习。然而,基于视觉技能的模仿学习通常需要大量的专家级技巧演示。例如,根据此前的研究,根据原始像素输入实现抓取单个固定对象的任务,大概需要 200 次演示才能实现良好的性能。因此,如果只给出一个演示,机器人将会很难学习。
而且,当机器人需要模仿人类展示的特定操作技能时,问题会变得更具挑战性。首先,机械臂看起来与人体手臂明显不同。其次,不幸的是,设计一套人类演示和机器人演示之间正确的通讯系统十分困难。这不仅仅是追踪和重新映射动作:该任务更依赖于这个动作如何影响现实存在的物体,而且我们需要一个以交互为中心的通讯系统。
为了让机器人能够模仿人类视频中的技巧,我们可以让它结合先验知识,而不是从头开始学习每项技能。通过结合先验知识,机器人还应该能够快速学习在领域间迁移不变地操作新物体,比如不同的示范者、不同的背景场景或不同的视角。
我们的目标是通过从演示数据中学习来实现这两种能力,少量样例模仿和领域不变性。该技术也被称为元学习,并在之前的博客中讨论过,这是使机器人通过观察人类来学习模仿能力的关键。
单例模仿学习
所以我们如何使用元学习来使机器人快速适应许多不同的物体?我们的方法是将元学习和模仿学习结合起来,实现单例(one-shot)模仿学习。其核心思想是提供一个特定任务的单个演示,即操纵某个特定对象,机器人可以快速识别该任务并在不同环境下成功解决它。
之前的一项关于单例模仿学习的研究在模拟任务上取得了令人印象深刻的结果,例如通过学习成千上万个演示来进行块堆叠。如果我们希望机器人能够模仿人类并操作不同的新物体,我们需要开发一个新的系统,它通过使用现实世界中实际收集的数据集,并从视频演示中学习。首先,我们将讨论如何对遥控操作收集的单个演示进行视觉模仿。然后,我们将展示如何将它扩展到从人类视频中学习。
单例视觉模仿学习
为了使机器人能够从视频中学习,我们将模仿学习、高效的元学习算法与未知模型元学习(MAML)相结合。在这种方法中,我们使用标准卷积神经网络,参数 θ 是我们的策略表示,它将时间步 t 从机器人捕获的图像 o_t 和机器人配置 x_t(例如关节角度和关节速度)映射到机器人动作(例如,机械手的线速度和角速度)。
该算法主要包含三步。
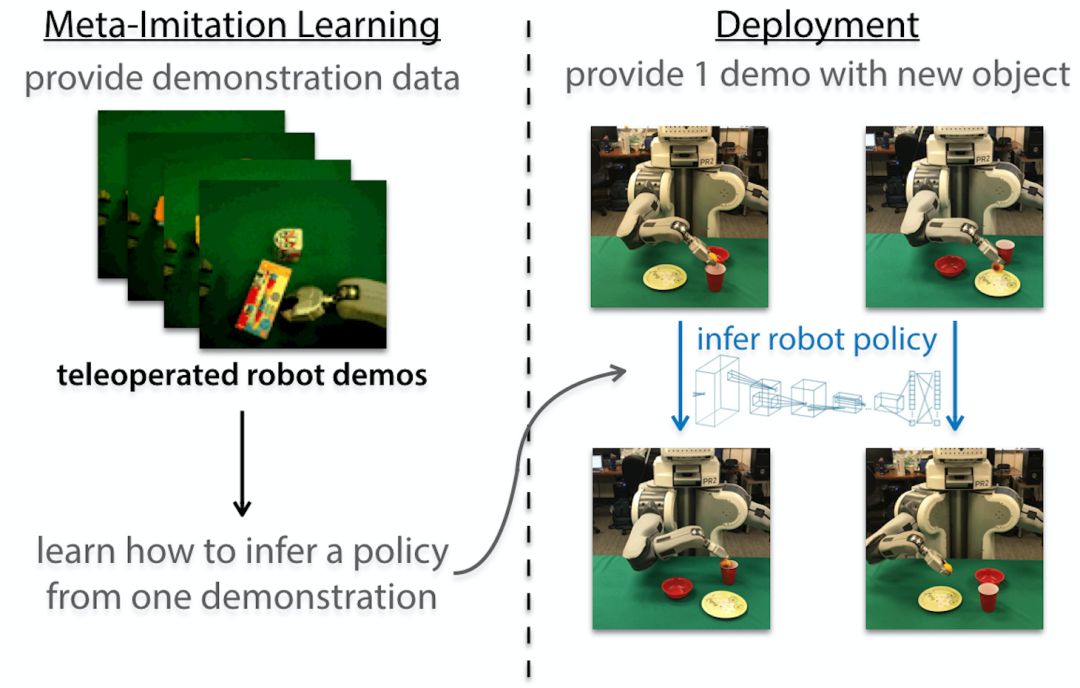
我们元学习算法的三大步骤。
首先,我们收集了一个包含大量遥控机器人执行不同任务的演示数据集,在我们的例子中,这对应于操纵不同的对象。然后,我们运用 MAML 来学习一组初始策略参数 θ,以便在为某个对象提供演示之后,我们可以对演示进行梯度下降,以找到一个针对该对象参数 θ' 的可泛化策略。在使用遥控演示时,可以通过比较策略的预测行动 π_θ(o_t)和演示行动 a*_t 来计算更新策略:
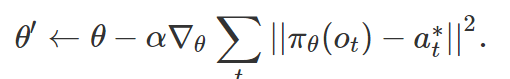
然后,我们通过迫使更新的策略 π_θ' 与另一演示中同一对象的动作相匹配来优化初始参数 θ。在元训练之后,我们可以让机器人通过使用该任务的单个演示计算梯度步来操作完全不可见的物体。这一步被称为元测试。
由于该方法不会为元学习和优化引入额外的参数,因此数据效率非常高。因此它可以仅通过观看遥控操作的机器人演示来执行各种控制任务,例如推动和放置:


通过单个演示将物品放入新的容器中。左:演示。右:学习到的策略。
通过领域自适应元学习观察人类的单例模仿
上述方法仍然依靠遥控机器人而非人类的示范。为此,我们设计了一个基于上述算法的领域自适应单例模仿算法。我们收集了许多不同任务的遥控操作机器人和人类操作演示视频。
然后,我们为计算策略更新提供人类演示,并使用执行相同任务的机器人演示评估更新后的策略。该算法的说明图如下:
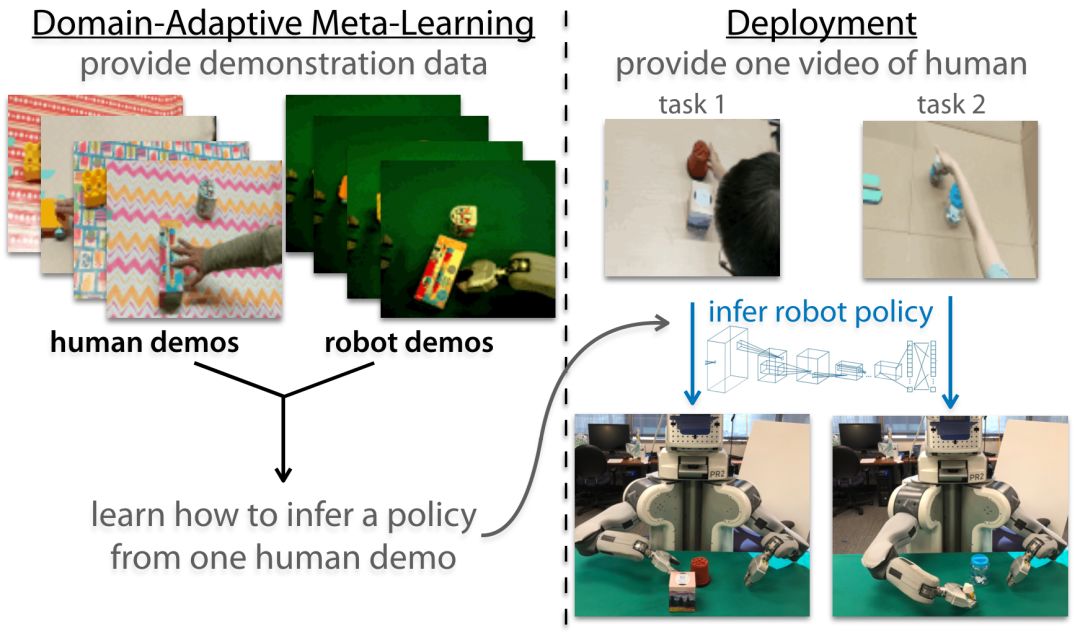
领域适应性元学习概述
不幸的是,由于人类演示仅仅是人类执行任务的视频,其中不包含专家动作 a*_t,我们无法计算上面定义的策略更新。相反,我们建议学习一个不需要动作标签的损失函数以更新策略。学习损失函数的直觉在于,我们可以构建一个仅使用已有输入、且未标记的视频函数,同时仍然产生梯度以适合更新策略参数。
虽然这看起来像是一个不可能完成的任务,但请记住,元训练过程在梯度步之后仍然通过真正的机器人动作来监督策略。因此学习损失的作用可能被解释为简单地引导参数更新来修改策略以拾取场景中正确的视觉线索,使得元训练的输出为正确的动作。我们使用时间卷积来学习损失函数,它可以在视频演示中提取时间信息:
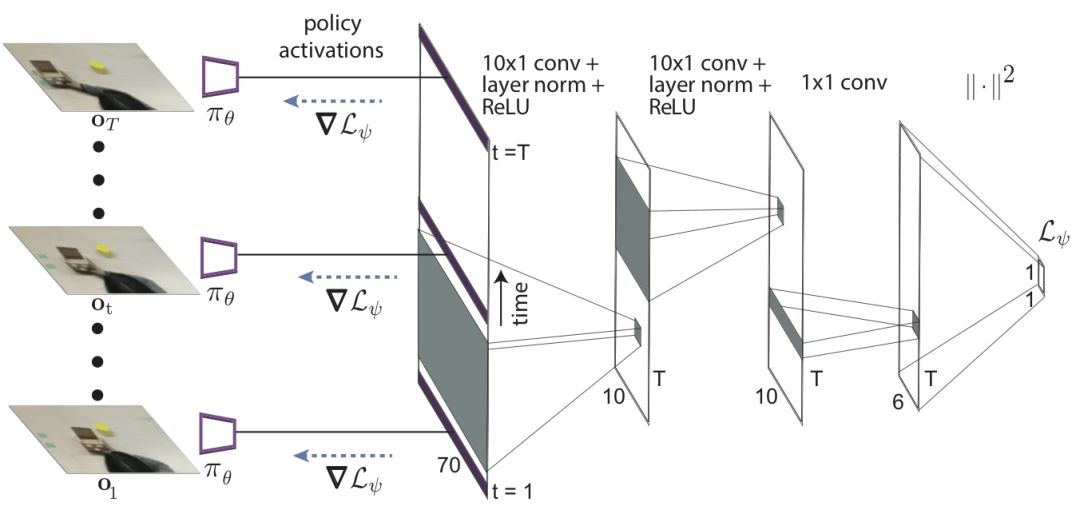
我们将这种方法称为领域自适应元学习算法,因为它从不同领域的数据(例如人类演示视频)中学习,并将这些领域作为机器人执行策略的领域。我们的方法使得 PR2 机器人能够有效地学习将很多训练期间未观察的不同的物体推向目标位置:


通过观看人类演示来学习推动新的物体。
通过观察人类操作每个物体的演示来拿起物体并将它们放置在目标容器上:


学习拿起一个新物体并将其放入以前没观察过的碗中。
我们还评估了使用不同视角在不同房间收集人类演示视频的方法。机器人仍可以很好地完成这些任务:


学习通过在不同视角环境中观看人类演示来推动新物体。
接下来是什么?
既然我们已经教会机器人通过观看单个视频(我们在 NIPS 2017 演示过)来学习操作新物体,下一步自然是进一步将这些方法扩展到对应于完全不同动作和目标的任务设置中,例如使用各种各样的工具或做各种各样的运动。通过考虑潜在任务分布的多样性,我们希望这些模型能够实现更好的泛化,使机器人能够快速制定适用于新环境的策略。
此外,我们在这里开发的技术并不局限于机器人操作甚至控制。例如,模仿学习和元学习都被用在自然语言处理中。在语言和其它序列决策环境中,通过少数演示来学习模仿是未来研究的一个有趣的方向。
我们十分感谢 Sergey Levine 和 Pieter Abbeel 对发表本篇博文提供的宝贵的反馈意见。这篇文章基于以下论文:
One-Shot Visual Imitation Learning via Meta-Learning
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
原文链接:http://bair.berkeley.edu/blog/2018/06/28/daml/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





