NeurIPS 2021评分曝光!现华中科大助理教授和清华校友8.5分并列第2!MIT稳居第1

新智元报道
新智元报道
编辑:David 好困
【新智元导读】近日,NeurIPS 2021被接收论文的详细得分公布。最高分为MIT的8.75分,现华中科大助理教授和清华校友8.5分并列第2!澳华人团队遭遇Consistency Experiment低分。
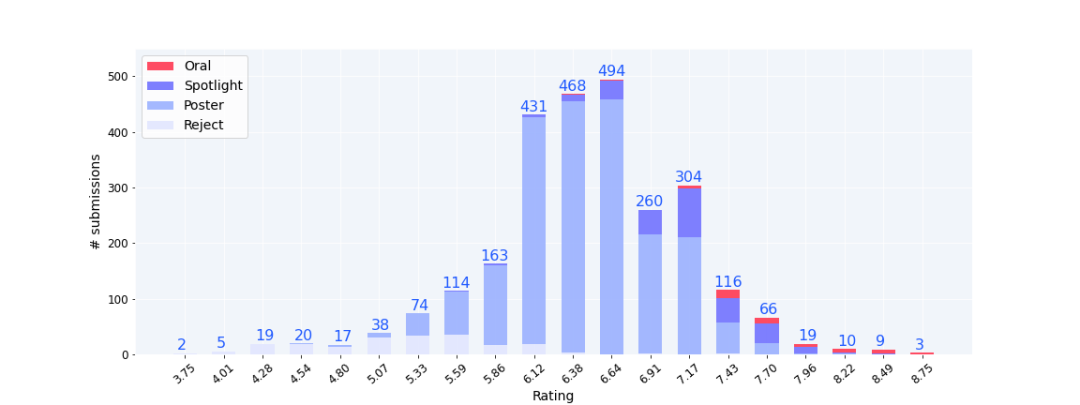
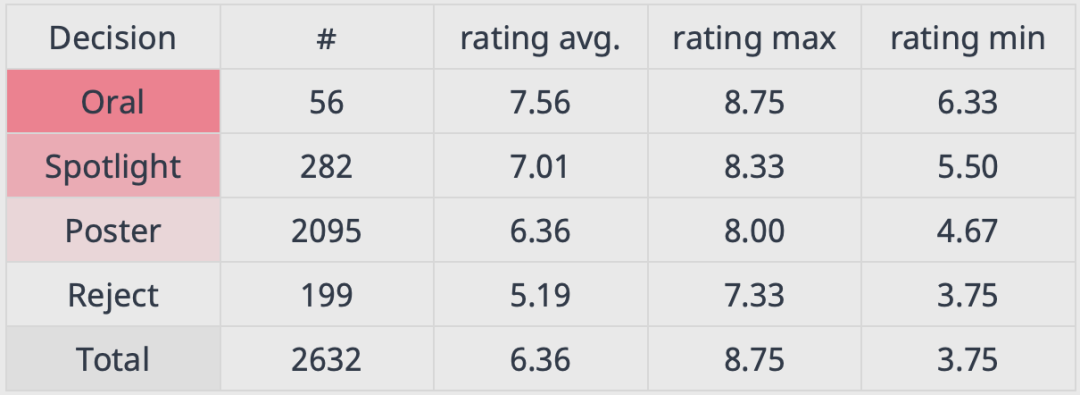
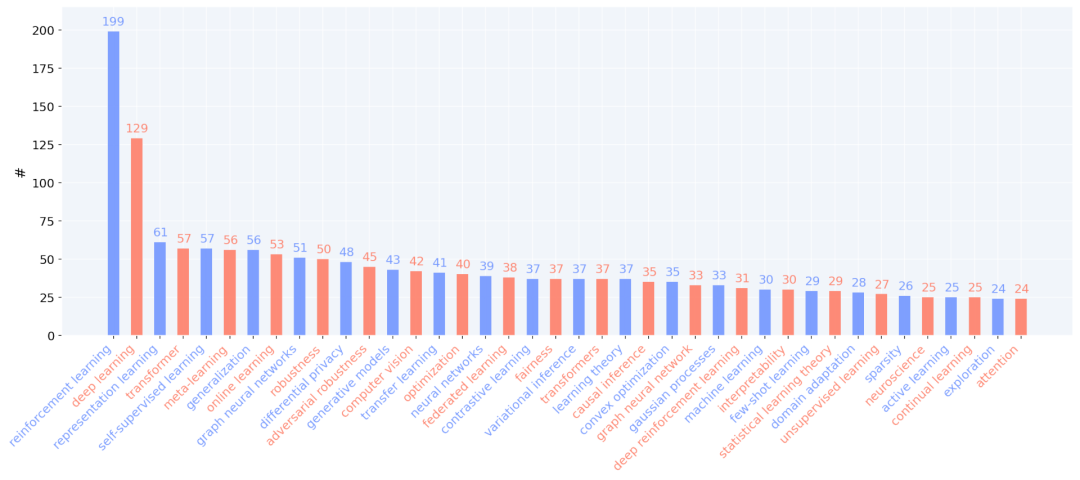
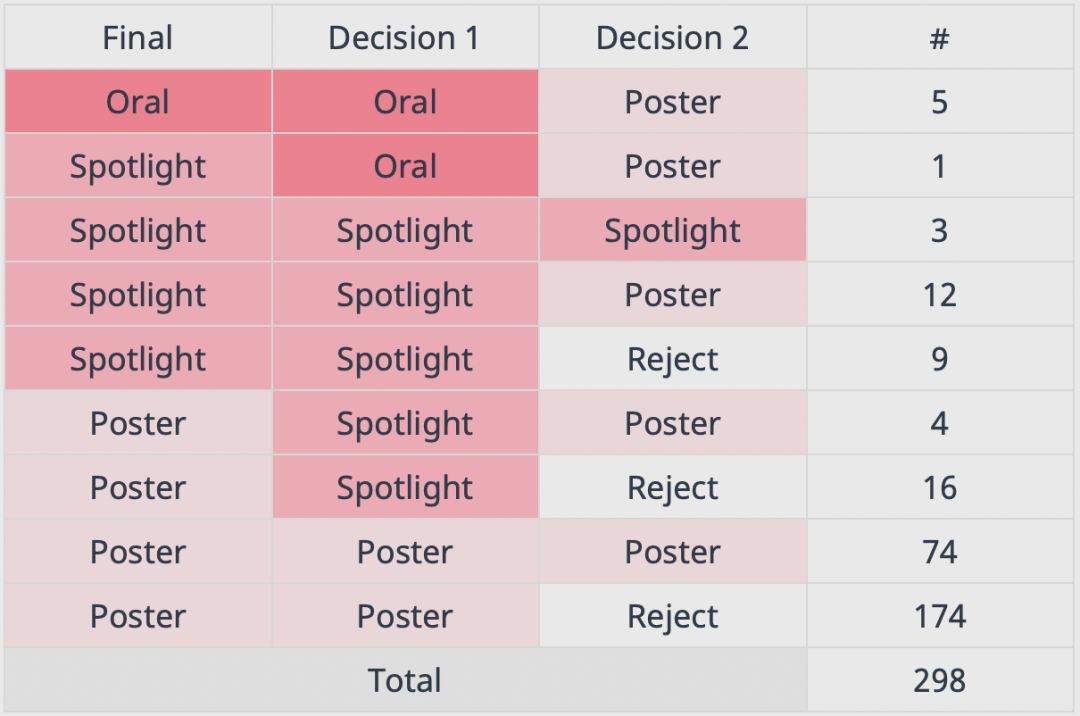
最高分和最低分

|
|
|
|
|
|
|
|

本文解决了一个自Syrgkanis等人2015年的工作以来一直都没有被解决的问题。尽管Chen & Peng, 2020的最新进展显示了T^{1/6}的遗憾,但为了实现polylog(T)的遗憾,本文提出了一个显著的新观点,我们认为这对社区非常有益。所有审稿人都对这一结果感到兴奋。

|
|
|
|
|
|
|
|

本文在随机矩阵理论中提出了新的数学结果,描述了高维系统中广义线性模型(G-GLMs)对应的Hessian矩阵的极限谱分布。其结果是对极限谱的渐进式精确表征,表现出实践中经常出现的结构类型,包括孤立的离群特征值、多模态密度等。因此,本文为NeurIPS社区提供了一个理解高维模型频谱的新的和强大的视角,并有可能为二阶优化和其他领域的新发展铺平道路。
本文标题中的「更现实」描述了结果的范围和通用性:这里的重点实际上并没有触及现实模型、NN等,但G-GLM设置和一般分布假设使指针明显朝向「现实」方向。虽然本文确实观察到了一些确实倾向于出现在实际配置中的现象(比如大的离群值),但仍然不清楚这里提供的解释实际上是否是更普遍的现象所依据的那些解释。本文的扩展版本肯定会受益于对这个问题的一些详细(经验)分析。不过,如果没有这些补充,本文中的技术和见解还是会引起社区的兴趣,而且本文将成为NeurIPS的一个重要补充。

|
|
|
|
|
|
|
|

这篇论文介绍了一个及时而重要的贡献,将SDF表征与神经体积渲染相结合。四个审稿人中的三个强烈建议接受。作者应该努力解决审稿人所关注的问题。这包括加入反驳期的消融研究,纳入L3KT建议的讨论等。

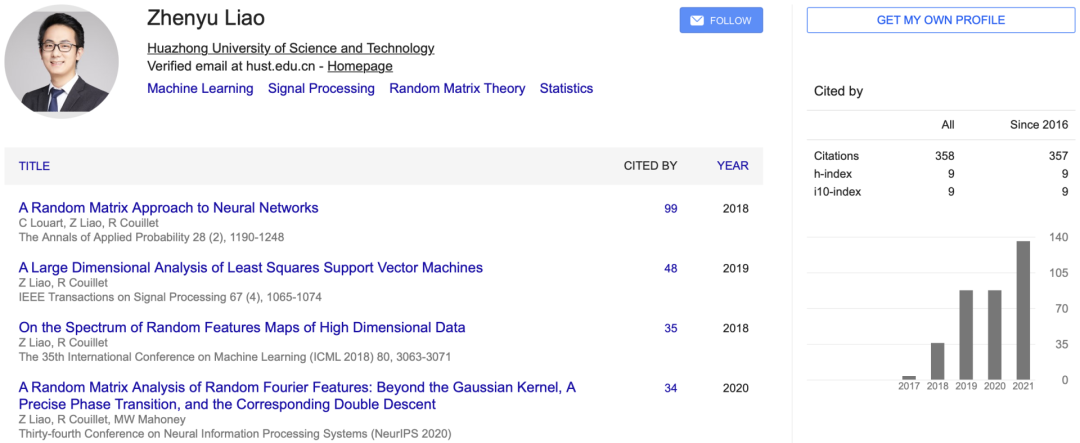

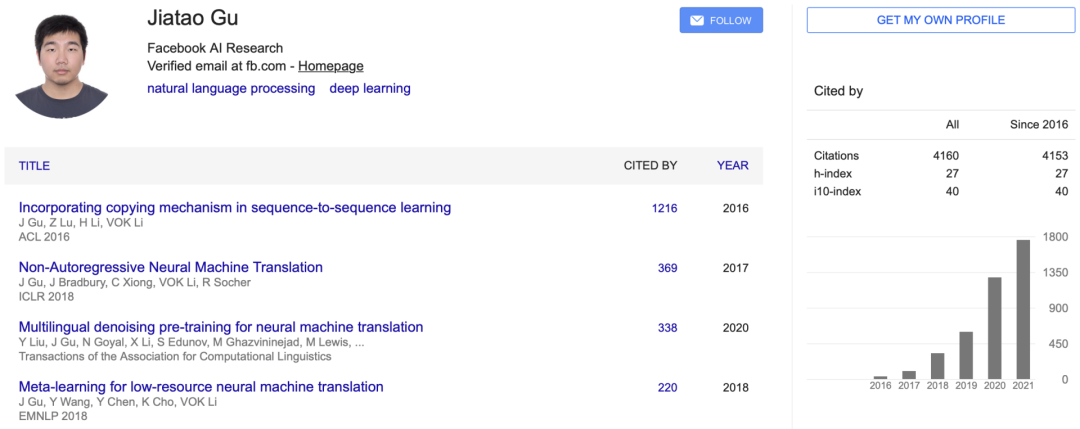
华人团队一文「最低分滑过」
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



这篇论文提出了一个有趣的想法,审稿人一致认为它有潜力。不幸的是,所有审稿人都认为论文的写作不够清晰,与基线的比较也需要改进。我建议作者解决这些问题并重新提交。
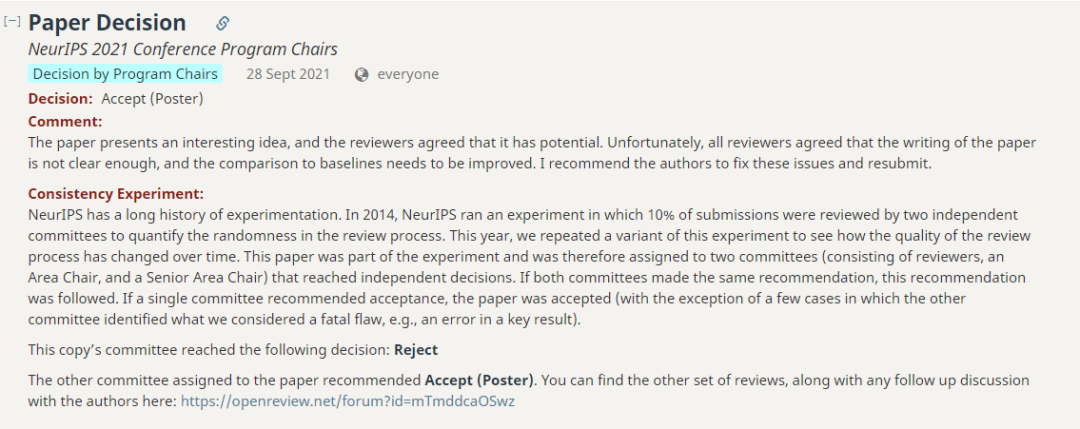
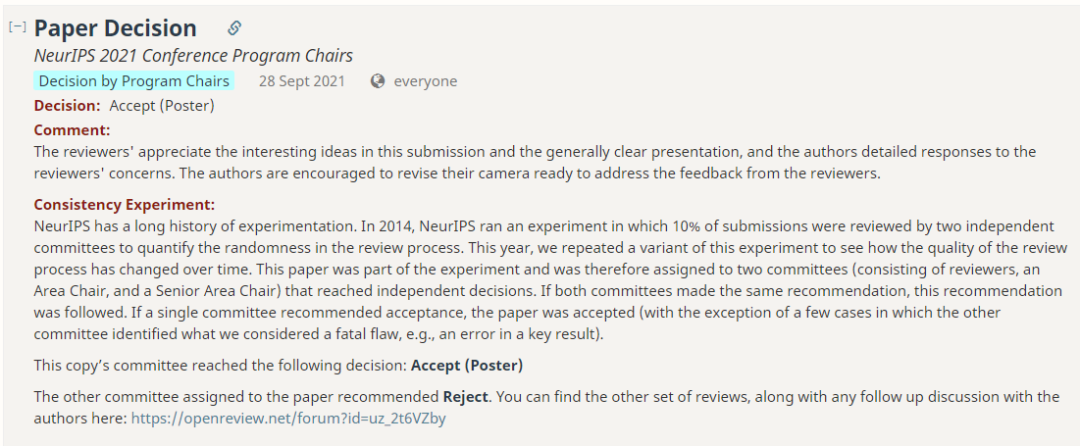
参考资料:
https://guoqiangwei.xyz/htmls/neurips2021/neurips2021_submissions.html

登录查看更多
相关内容
Arxiv
1+阅读 · 2022年4月18日
Arxiv
11+阅读 · 2018年5月9日




相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2022年4月18日
Arxiv
11+阅读 · 2018年5月9日