DeepType:用神经分类系统自动实现实体消歧
编者按:在线百科、知识库以及含有相关标签和类别层次的图片和视频数据集的丰富,使得在人工智能系统中,符号表示嵌入分布式和神经表征中越来越容易。目前有几种方法能将大量符号结构嵌入神经网络的行为中,但它们都面临几处困难:
难以根据目标任务的信息增加选择正确的符号信息;
难以为符号信息设计表示(层次结构、语法、限制条件);
需要手工标记大量数据。
针对这些问题,OpenAI提出了DeepType,能将符号信息整合到神经网络的推理过程中,无需人类帮助自动设计分类系统。以下是论智对博文的编译。
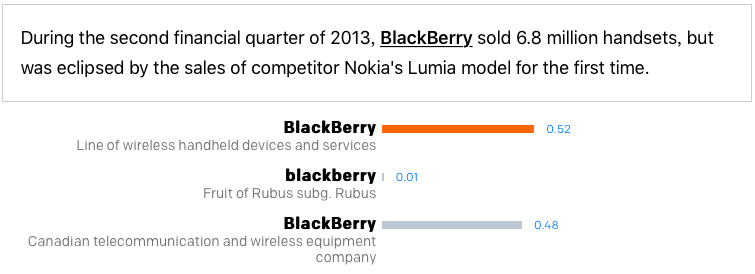
具体来说,这一系统通过神经网络判断单词类别,能够自动“读懂”某个单词指的是什么。例如,在“the prey saw the jaguar cross the jungle”这句话中,系统不是直接推断“jaguar”代表美洲豹还是汽车品牌还是别的什么东西,而是在预先选择的类别集里回答20个“问题”。这种方法增强了目前先进的实体消歧数据集。
在我们的训练数据中,70%的时间里jaguar都指的是汽车品牌“捷豹”,29%指的是美洲豹这种动物,只有1%的可能指代“美洲豹战斗机”。

利用DeepType技术,我们又做了两个实验,如下图所示,在第一个例子中,对词义判断的变化并不显著。但是在第二个例子中,jaguar意为“美洲豹”的比例占到将近90%。

最终,我们的方法在CoNNL(YAGO)数据集上的准确率达到94.88%(此前最好成绩是91.50%和91.70%);在TAC KBP 2010挑战赛上准确率为90.85%(此前最佳为87.20%和87.70%)。我们的分类方法几乎适用于所有任务,准确率最高可达98.6%—99%。
总体概述
我们的系统实现过程如下:
1.提取每个维基百科中的内链,构成所有相关的实体集合。比如,当我们在维基百科的页面中看到jaguar这个词的连接时,就可以确定这一页面https://en.wikipedia.org/wiki/Jaguar是jaguar的一个意思。
2.浏览维基百科的类别集合(用维基数据知识图谱)确定每个实体的每种意思都属于哪些类别。例如,在维基百科https://en.wikipedia.org/wiki/Jaguar_Cars页面的最下方,会显示这些类别:

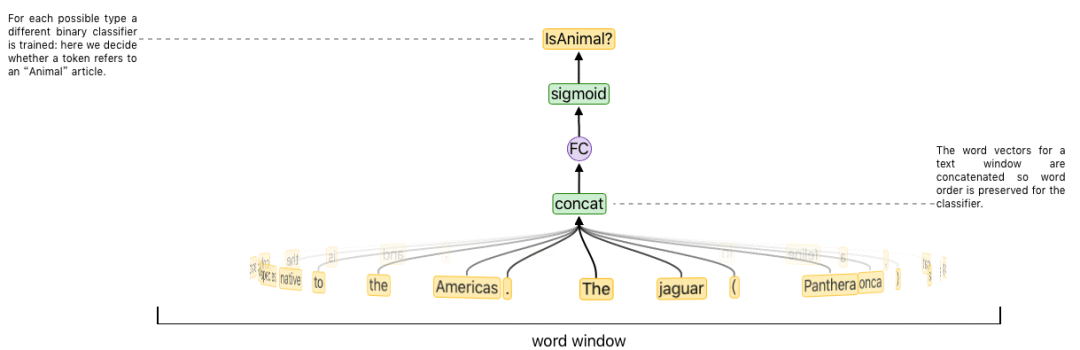
3.挑选大约100个类别组成你的“type”系统,并对其进行优化,使其能准确地定义每个实体。我们知道了实体到类别的映射,所以给定一个类别系统,我们可以将每个实体用大约100维的二元分类向量表示,确定属于哪个类别。
4.利用每个维基百科中的内链和其周围的语境,生成训练数据,数据中将每个词和其周围的文本映射到对应实体约100维的分类表示上,然后训练一个神经网络预测这一映射。这一串过程与上一步连在一起:用维基百科将单词连接映射到实体,在第2步中我们获得了每一实体的类别,在第3步中我们在我们的类别系统(type system)中确定了类别。
5.测试时,给定一个单词及相关语境,我们的神经网络会输出改词所属每个类别的概率。如果我们知道确切的概率,我们就能进一步判断,最终确定一个实体词义。但事实上,我们必须完成概率有关的20个问题:利用贝叶斯定理来计算每个可能实体对应的词义消歧的几率。
更多例子
下面是利用我们方法测试的更多例子:



更多例子可至文末点击原文地址查看。
清除数据
维基数据的知识图谱可以用作训练数据的来源,让实体更精确地映射到类别中。我们循环应用instance of关系,来决定特定实体的类型集。例如,在“human”这一节点下的子节点都有“人类”这个类别。维基百科还能通过它的category link提供实体到类别的映射。
维基百科的内链数据能很好地估计特定短语对应的某个实体。不过,有的时候这一过程会受到干扰,因为维基百科经常链接到一个特定的事例,而非一个通用的概念(例如会把“king”这个词链到英国的查理一世)。这就导致会出现大量相关的实体(“king”就有974个相关实体),另外这也会导致链接频率的混乱(例如“queen”链接到“皇后乐队”有4920次,链接到“伊丽莎白二世”1430次,链接到“君主”只有32次)。
最简单的方法就是删除少见的链接,但这样会丢失信息。于是我们改用维基数据的属性图将链接转化为它们通用的含义,如下图所示:

经过处理后,“king”的相关实体从974个减少到了14个,而“queen”所对应的“君主”的链接从32个上涨到了3553个。
学习好的类型系统
我们必须选择最好的类别系统和参数,从而提高词义消歧的准确度。类别的数量很多,想准确找出解决方案很难。于是,我们选用启发式搜索或随机优化(进化算法)来选择一个类别系统,然后用梯度下降训练一个类别分类器,预测类别系统的行为。

我们需要选择可区分的类别,同时要易于学习(周围的上下文有助于神经网络推断出适合的类别)。通过这一方法我们收获了两个要素:可学性(用来预测类别概率的分类器的曲线下面积的平均值)和预测准确度(如果我们预测出了所有类型,将如何消除实体歧义)。
类别系统进化
我们用数据库中最常见的15万种类别训练用于预测词义的二元分类器。分类器的曲线下面积(AUC)成为某类型的“学习性分数”。高AUC分值意味着容易从上下文预测词语的类型;糟糕的表现可能意味着培训数据的缺失,或者词语窗口并没什么用。我们完整的模型需要用几天的时间来训练,所以我们改用一个更小的模型来评估学习性分数,只需要2.5秒。
现在,我们可以用这些学习性分数和统计数据来估计给定类型集的表现情况,作为我们的类别系统。你可以在下面运行交叉熵方法来发现浏览器中的类型。注意,变换样本大小和惩罚会影响解决方案。

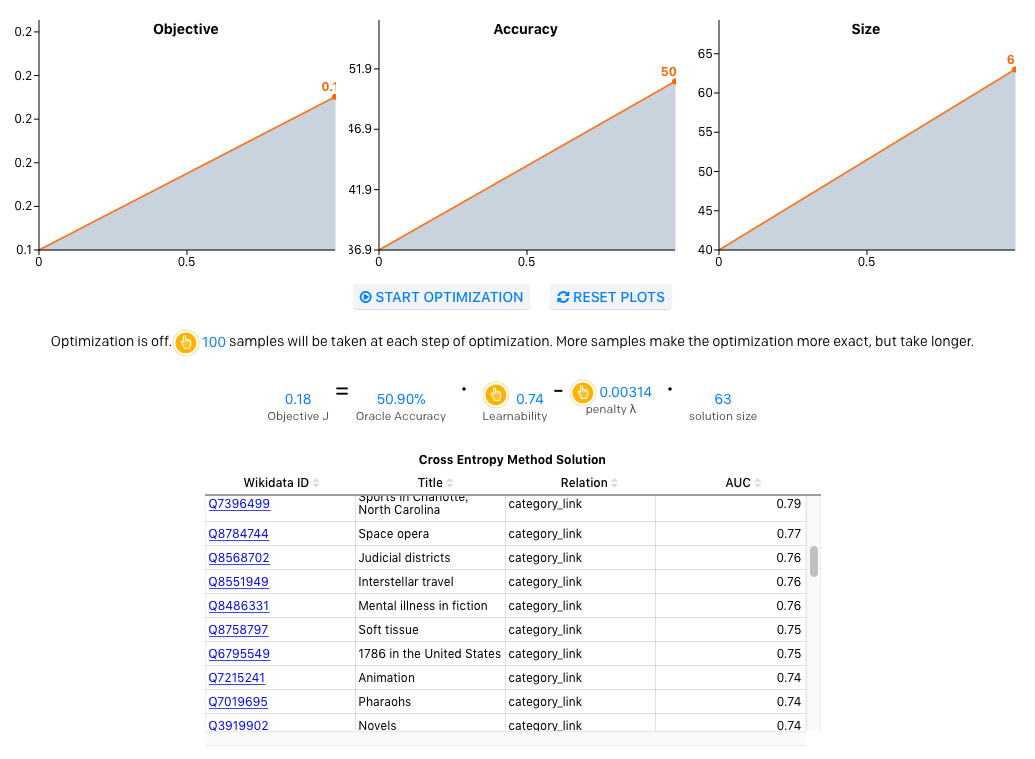
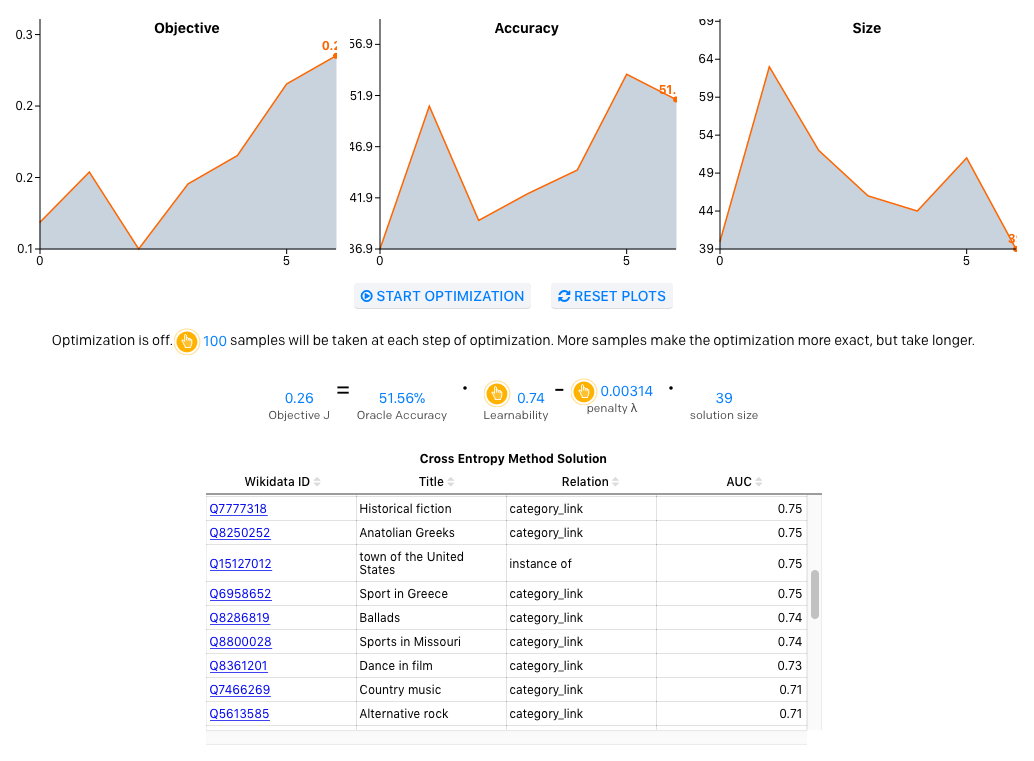
为了更好地了解设计类型系统哪里更简单,哪里更困难,OpenAI的原网站可以让用户自己进行设计。下面共有六个大类,你可以选择一种,之后,就能开始查看某一单词所对应的实体。

例如选择“Culture”后,给出了“Achilles”的例子:
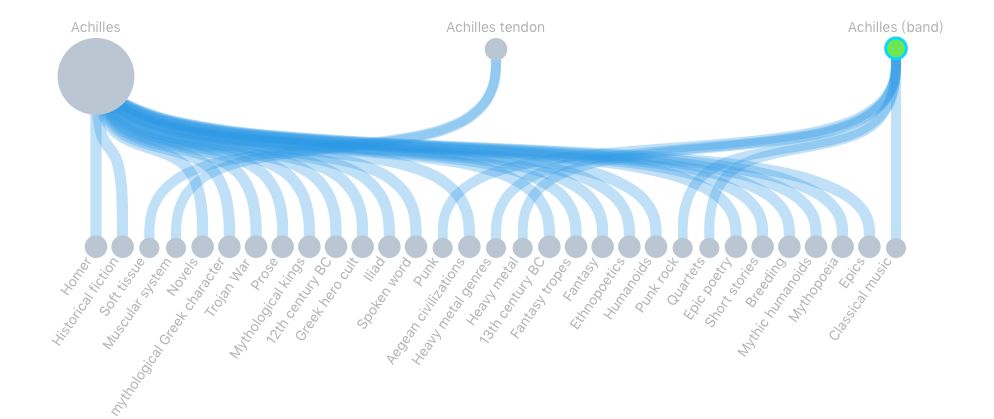
顶行显示的圆圈是所有可能的答案(阿喀琉斯、阿克琉斯之踵、阿克琉斯乐队),正确的那个用绿色标注了出来(乐队)。底下一行是你可用的词语类别。连接上下行的线表示从属关系。当你能将无用的线删除后,就能消除歧义了。
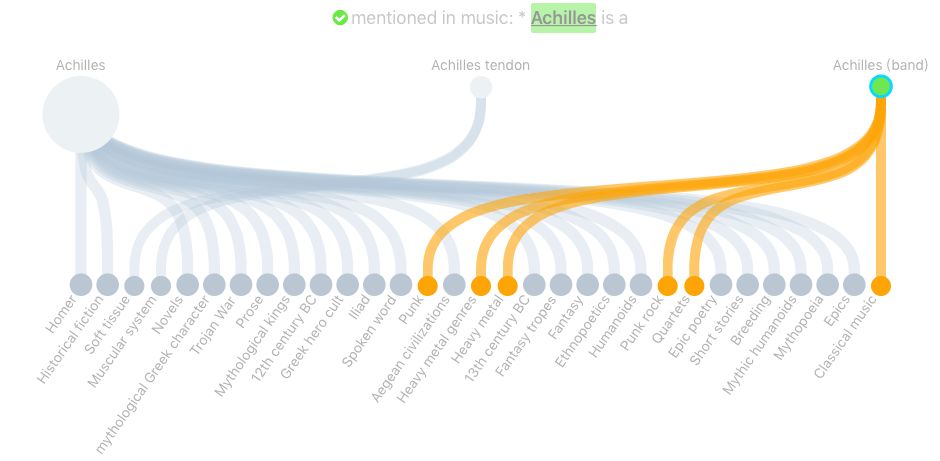
神经类型系统
利用我们的类型系统优化生成的最佳解决方法,我们可以用生成的标签给维基百科里的数据打标。利用这些数据(在我们的实验中,总共英文和法文各有400Mtokens),我们现在可以训练一个双向LSTM,独立预测每个单词所有的可能类别。在维基百科的源文本上,我们只监督维基的内链。不过我们完全可以训练一个深度神经网络来预测类别分数,最终可以达到的F1分数超过0.91。
推理
预测一个文档中的实体通常依赖于不同实体之间的“一致性”。例如,测量各个实体互相之间的匹配程度,即文档中O(N^2)的长度。相反,我们的运行时间是0(N),因为我们只需要在字典树中查找每个短语,将短语映射到其可能的意义中。我们根据在维基百科中看到的链接频率对每个可能的实体进行排名,通过比较其在类别分类器下可能的权重进行优化。只要确定某实体在某类别的可能性,就能将其添加进去。
下一步做什么
我们的解决方案与此前的方法有很大的不同,我们关注的是,分布式表征端到端的学习与我们开发的基于类别的推理有何不同。我们在这里用的类别系统是通过维基百科的一个小子集发现的,然后把它扩展到用于发现所有类别系统。我们希望能帮助到你!
原文地址:https://blog.openai.com/discovering-types-for-entity-disambiguation/
代码地址:https://github.com/openai/deeptype







