Github 项目推荐 | 用 Keras 实现的神经网络机器翻译

本库是用 Keras 实现的神经网络机器翻译,查阅库文件请访问:
https://nmt-keras.readthedocs.io/
Github 页面:
https://github.com/lvapeab/nmt-keras
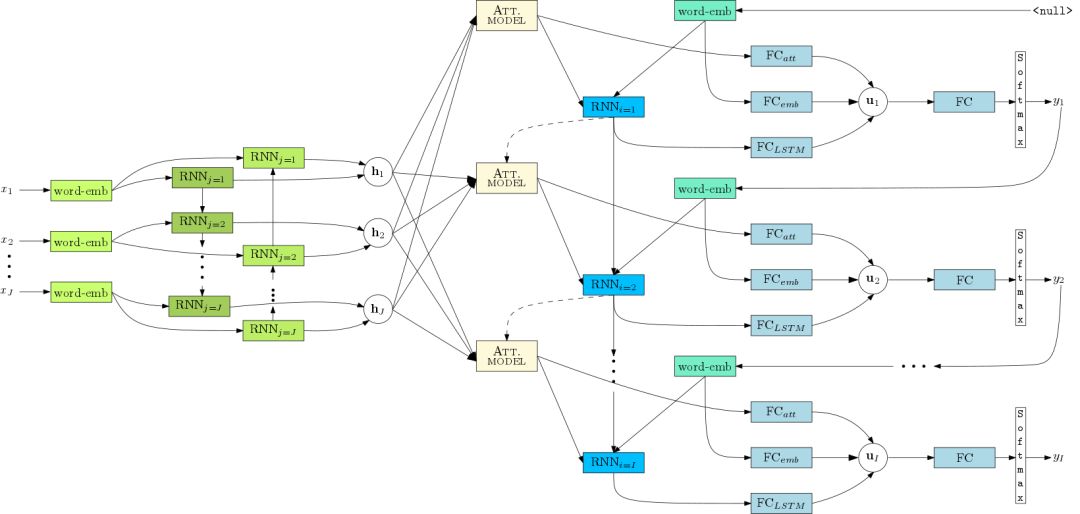
如过你需要在研究中使用本工具库,请引用以下论文:
@misc{nmt-keras2017,
author = {Peris, {\'A}lvaro},
title = {{NMT}-{K}eras},
year = {2017},
publisher = {GitHub},
note = {GitHub repository},
howpublished = {\url{https://github.com/lvapeab/nmt-keras}},
}
安装
假设已经安装 pip,请运行:
git clone https://github.com/lvapeab/nmt-keras
cd nmt-keras
pip install -r requirements.txt
获取运行该库所需要的软件包。
需求
安装 NMT-Keras 需要以下的库
我们的 Keras 版本(推荐版本 2.0.7 或更新版本)
https://github.com/MarcBS/keras
Multimodal Keras Wrapper(2.0 版或更新版本,文档和教程)
https://github.com/lvapeab/multimodal_keras_wrapper
Coco-caption 评估套件(只需执行评估)
https://github.com/lvapeab/coco-caption/tree/master/pycocoevalcap/
用法:
在 config.py 脚本中设置一个训练配置。请查阅文档(https://github.com/lvapeab/nmt-keras/blob/master/examples/documentation/config.md)获取有关每个特定超参数的详细信息。您也可以在按照语法 Key = Value 调用 main.py 脚本时指定参数。
开始训练!:
python main.py
解码
一旦我们的模型开始训练,我们就可以使用 sample_ensemble.py 脚本翻译新文本。有关此脚本的更多详细信息,请参阅 ensembling_tutorial:
https://github.com/lvapeab/nmt-keras/blob/master/examples/documentation/ensembling_tutorial.md
总之,如果我们想使用前三个 epoch 的模型来翻译 examples / EuTrans / test.en 文件,只需运行:
python sample_ensemble.py
--models trained_models/tutorial_model/epoch_1 \
trained_models/tutorial_model/epoch_2 \
--dataset datasets/Dataset_tutorial_dataset.pkl \
--text examples/EuTrans/test.en
评分
score.py(https://github.com/lvapeab/nmt-keras/blob/master/score.py)脚本可用于获取平行语料库的概率(-log)。 其语法如下:
python score.py --help
usage: Use several translation models for scoring source--target pairs
[-h] -ds DATASET [-src SOURCE] [-trg TARGET] [-s SPLITS [SPLITS ...]]
[-d DEST] [-v] [-c CONFIG] --models MODELS [MODELS ...]
optional arguments:
-h, --help show this help message and exit
-ds DATASET, --dataset DATASET
Dataset instance with data
-src SOURCE, --source SOURCE
Text file with source sentences
-trg TARGET, --target TARGET
Text file with target sentences
-s SPLITS [SPLITS ...], --splits SPLITS [SPLITS ...]
Splits to sample. Should be already includedinto the
dataset object.
-d DEST, --dest DEST File to save scores in
-v, --verbose Be verbose
-c CONFIG, --config CONFIG
Config pkl for loading the model configuration. If not
specified, hyperparameters are read from config.py
--models MODELS [MODELS ...]
path to the models

NLP 工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门 NLP
海外博士讲师,丰富项目经验
算法 + 实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
如何在 Keras 中从零开始开发一个神经机器翻译系统?
▼▼▼




