论文导读 | OpenAI的实体消歧新发现

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
论文原文地址:
https://arxiv.org/abs/1802.01021
Github 项目地址:
https://github.com/openai/deeptype
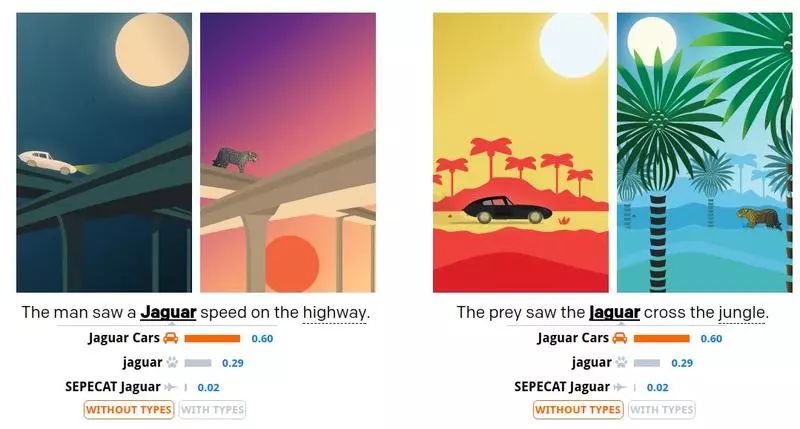
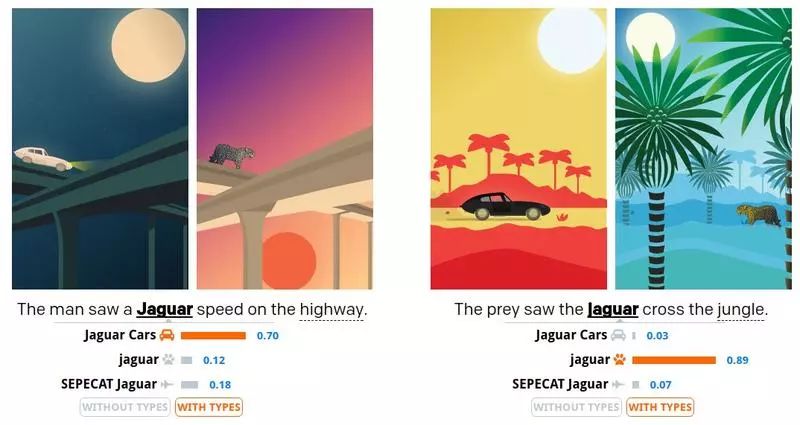
上图是对该类型系统的一个简单说明。在训练数据中 jaguar 被认为是捷豹汽车的概率是 70%,被认为是美洲豹的概率是 29%,被认为是豹式飞机的概率是 1%。使用我们的“类型”方法进行判断,对第一个例子中的消岐效果影响不大,因为模型认为美洲豹沿着高速公路奔跑的情况是可能存在的,但是在第二个例子中,模型认为捷豹汽车穿越丛林这件事显然是不太可能出现的。
我们在 CoNLL(YAGO) 取得了 94.88% 的准确率,之前最好的准确率是 91.50% 和 91.70%。并在 TAC KBP 2010 挑战赛上取得了 90.85% 的准确率,而之前的最好的准确率是 87.20% 和 87.70%。之前的方法均使用了词向量的方法,但是对于实体消歧这类任务,基于类型的方法往往能够更好的胜出,因为完美的“类型”预测可以得到 98.6% 至 99% 的准确率。
我们的系统分为下面几个步骤:
提取每个单词的维基百科内部链接, 以确定每个单词可供参考的实体集合。例如,当我们在维基百科的页面遇到链接 jaguar 时, 我们就认为链接可能是 jaguar 的一个含义。
https://en.wikipedia.org/wiki/Jaguar
通过对维基百科类别树的遍历 (使用 Wikidata 知识图) 来决定每个实体所属的类别集合。比如说,在页面的底部,是下表中的这些类 (它们都有其专属类别,比如 Automobiles):Categories: [British barnds] [Car brands] [Jaguar Car] [Jaguar vechicles]
https://en.wikipedia.org/wiki/Jaguar_Cars’s
选择一个含有 100 种类别的列表当作你的类型系统,然后优化该系统,使选取的类别可以更紧凑的表示任何实体。这样我们就知道了实体到类别的映射关系,所以对于我们的类型系统,可以将每个类别中的每个实体表示为约 100 维的唯一的二值向量,这个向量表示了该实体与每个类别的从属关系。
使用每个维基百科的内部链接以及其上下文来产生训练数据,我们需要使用神经网络来学习一种映射关系,即单词到 100 维的二值向量之间的映射。这一步将之前的步骤联系起来:维基百科的链接将单词与实体相连,通过第二步我们知道了每一个实体的类别,而第三步则在我们的类型系统中选择了实体所属的类别。
在测试阶段,给定一个词语以及其上下文,我们的神经网络将输出该词语属于其类型系统中每一个类别的概率。如果我们知道了类别成员的准确集合,我们可以将结果缩小到一个实体 (假设分类结果是完美的)。但实际上,我们必须计算大概 20 个概率问题:对于该单词的每一个可能对应的实体,都需要使用贝叶斯理论来计算其概率。
下面是类型系统的一些实例,更多内容请点击原文查看:
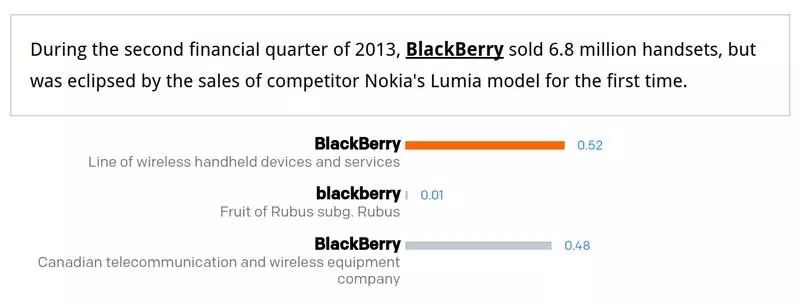

Wikidata 的知识图可以转化为训练数据源,完成细粒度实体到类型的映射。对于给定的实体,我们使用它的实体 (instance of ) 递归关系来决定其类型集,比如说,huamn 节点的子节点中有 human 这个类型。维基百科通过其类别链接也会提供一种实体到类别的映射。
对于一些实体,维基百科内部链接的统计可以提供一个比较好的相关短语。然而,有些时候链接到的是具体的实例而不是类别本身,这样就会产生信息上的噪声 (anaphora-- 例如,国王 (king) 这个词就会被链接到英格兰查理一世 (Charles I of England))。这种情况会导致相关实例的数量的爆炸增长与链接有效性的下降 (例如,queen 被链接到了乐队 Queen(皇后乐队)4920 次,Elizabeth II(伊丽莎白二世)1430 次,monarch(君主) 只有 32 次)。
最简单的方法是删除少见的链接,但是这会造成有效信息的丢失。而我们使用 Wikidata 属性图启发式地将链接转化为更加“通用”的含义,详细说明可以看下图。
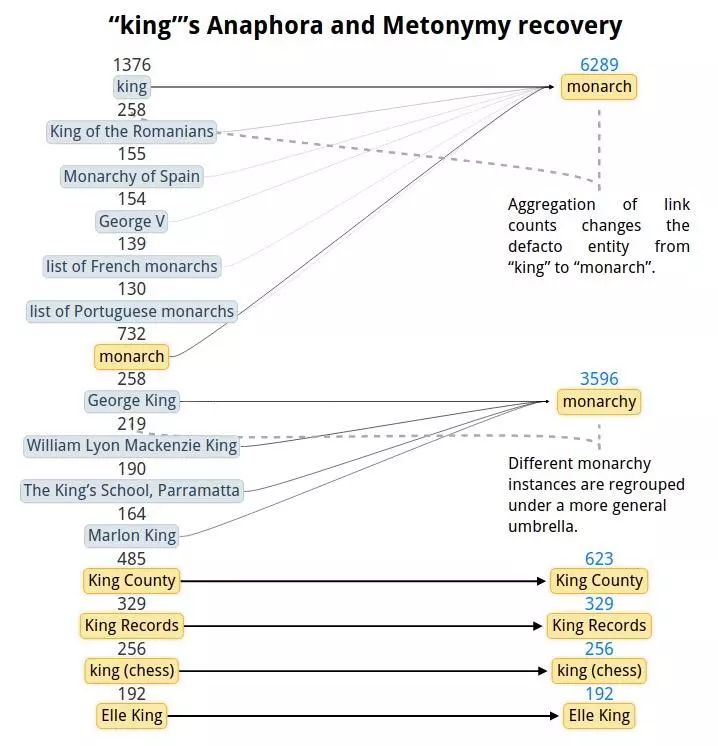
经过这一步的处理,king 这个单词的相关实体从 974 降到 14 个,并且 queen 到 monarch 的连接数从 32 增加到 3553。
我们需要选择一个最好的类型系统和参数使得消岐准确率最大化。由于存在大量的可能类型集,找到一个精确解是十分困难的。因此我们使用了启发式的搜索和随机优化 (进化算法) 来选择类型系统,并使用梯度下降训练类型分类器来预测类型系统的表现。
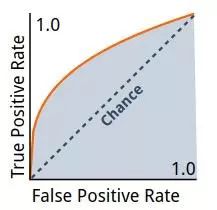
ROC 曲线绘制了真阳性率 (true positive) 随假阳性率 (false positive) 增加时的变化情况,上图是一个 AUC 为 0.76 时的 ROC 曲线。一个随机的分类器将会得到一条直线作为其 ROC 曲线 (图中的虚线)。
我们需要选择易于区分的类型 (这样可以快速地减少可能的实体集合),同时易于学习 (即上下文可以为神经网络的类型推断提供有效的信息)。我们使用两种启发式的准则对搜索方法进行了评估与优化:可学习性与准确性。可学习性的判定准则是使用 ROC 曲线下的面积 (AUC) 的平均值,使用 AUC 训练分类器来预测类型成员。而类型预测准确率的提高可以从另一个方面说明歧义的消除。
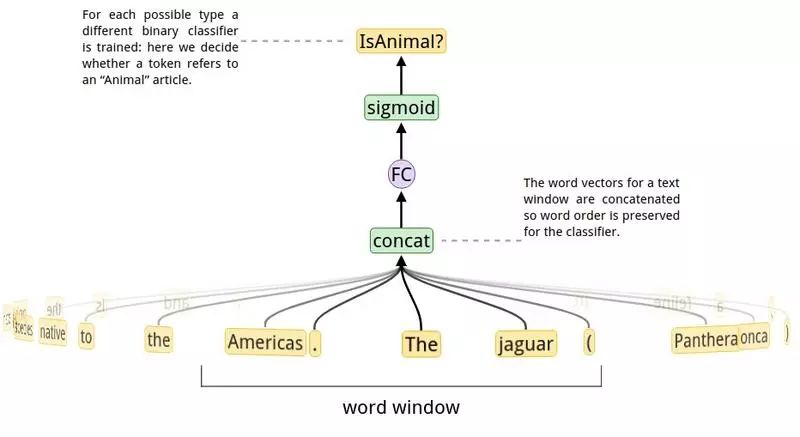
在给定的单词范围中,我们使用二分类器在数据的 150,000 个公共类型中对其成员做可能性预测。某个类型的分类器的 AUC 成为了“可学习性分数”的标志。高的 AUC 意味着从上下文中可以很轻松的对这一类型做预测,性能不好的分类器可能是由于对于这一类对应的训练数据不够或者因为给定的单词范围不理想 (这一现象常发生在一些非自然的类中,如 ISBNs)。完整模型的训练需要耗费几天的时间,所以我们使用更小的模型作为评估“可学习性分数”的一个示例,这样只需要 2.5 秒就可以完成训练。
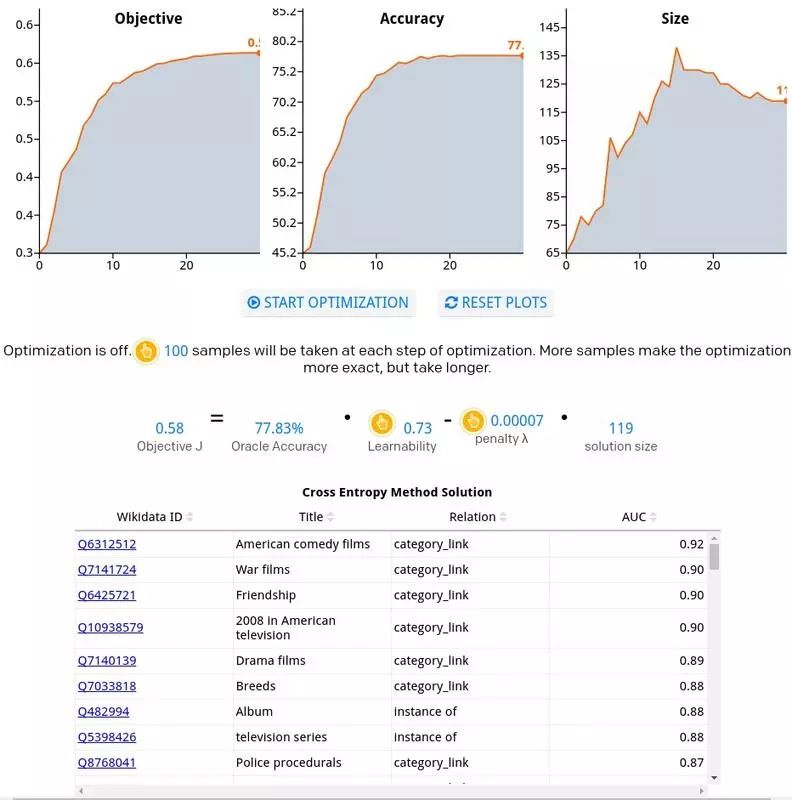
现在我们可以使用这些学习能力分数和统计数据来评估我们的类型系统中的一些子集的性能。下图是使用交叉熵进行优化的效果,点击原文可以查看动态优化过程。
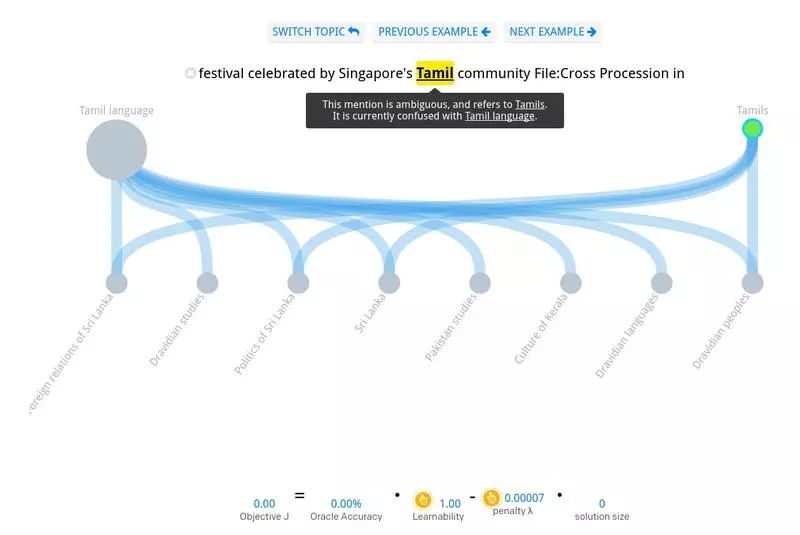
为了更好的了解在设计一个类型系统时,哪些部分比较容易哪些部分比较困难,原文提供了一个交互式的系统让用户可以手动训练自己的类型系统,通过选择你认为正确的连接关系,可以达到消歧的目的。在这个系统中,你可以选择一个大类,比如下图中的 Politics&Business, 然后对其中有歧义的词语开始进行训练。

每个大类中的选项如下图所示,对于例句中的词语有可能的答案显示在顶端,正确的答案是有颜色的那个,底部的是一些可用的类型。连线表示的是顶部的节点与底部节点之间的继承关系,通过选择你想使用的继承关系可以对分类器进行训练。直到你所选择的继承关系数量足够将正确答案与其它选项划分出来,这时就达到了消歧的目的。
现在我们可以使用训练好的类型系统对维基百科的数据进行标注。用这个数据 (在我们的试验中,每个英文和法文都有 40 亿个标注样本),我们可以训练一个双向 LSTM 网络来独立预测每个单词的所有类型成员。在维基百科源文本上,我们只有内部链接的监督信息,然而这些足以训练一个在 F1 上预测精度超过 0.91 的网络。
这里有一个有趣的事情,通过定向搜索发现,基本所有的类型系统都包含了 Aviation、Clothing 和 Games 这些类 (这就像是 1754 in Canada 这个词条,这表明在这个数据库中,1754 是一个非常令人激动的一年),点击这里可以查看完整的类型列表。
预测文档中的实体通常依赖于不同实体之间的“一致性”度量。例如,测量每个实体相互之间的匹配程度,其算法时间复杂度是 O(N^2)。但是我们的方法时间复杂度是 O(N),因为我们只需要在树中查找每个短语,将短语映射到其可能的含义。我们根据维基百科中采集的链接频次对所有可能的实体进行排序,并使用每个实体在分类器下的似然概率对其进行加权。新的实体可以通过指定其类型成员 (人、动物、原国籍、时间段等) 来添加。
在实体消歧的问题上,本文的方法和之前的其他方法有许多的不同点。端到端的词向量学习方法与本文讲述的基于类型推断的方法之间的性能比较,这是作者目前非常感兴趣的一点。本文提到的类型系统仅使用了维基百科的很小的子集,当然你也可以扩展到所有的维基百科数据上,以得到更广泛的应用。
查看原文:
https://blog.openai.com/discovering-types-for-entity-disambiguation/

如果觉得内容不错,记得给我们「留言」和「点赞」,给编辑鼓励一下!
今日荐文
点击下方图片即可阅读

OpenAI与特斯拉利益冲突?开源和 AI私有化哪个才是前景?
QCon 北京 2018,我们会邀请从巨头到创业公司,从平台到垂直行业,尽可能多样性的人工智能专家来给大家分享他们所使用的人工智能技术,以及如何将人工智能技术和具体的业务实践相结合。现在报名享 8 折优惠,立减 1360 元。有任何问题欢迎咨询购票经理 Hanna,电话:15110019061,微信:qcon-0410。





