学界 | ACL论文精彩论文演讲:simGAN+domain tag训练出表现优异的半监督问答模型(图文全文)
AI 科技评论按:虽然ACL 2017已经落下帷幕,但对精彩论文的解读还在继续。下面是 AI 科技评论在ACL现场记录的Zhilin Yang的报告。Zhilin Yang 是卡耐基·梅隆大学计算机学院语言技术研究院的一名博士生,William W. Cohen和Ruslan Salakutdinov两位大牛的高徒。
目前,QA对数据集的获取需要人工标注,这往往代价比较大。Z Yang他们提出了一种半监督的Generative Domain-Adaptive Nets模型,通过引入GAN和domain tag,同时利用标注的数据和未标注数据训练模型,能够得到很好的效果。
图文分享总结

大家好,我是Zhilin Yang,下面我将要讲的是半监督问答。这项工作是我与Junjie Hu,Ruslan Salakhutdinov 和William W. Cohen共同完成的。
动机及问题

近来在QA方面出现了很多神经网络模型。这些模型一般面临一个问题,即要想训练好就需要大量的训练数据。目前有一些这样的数据库,例如SQuAD等,他们通过人工来生成问答对。这种数据库收集是非常耗时耗力的。也有一些无监督模型来做这种自动问答对生成,它们会使用多层RNN、关注、匹配等技术,但这种模型一般较为庞大。

一边是比较耗时耗力的人工问答对,一边是可以从Wikipedia上大量下载的未标记文本。那么我们就自然想到“半监督问答”。

所谓“半监督问答”就是,用少量标记的问答对和大量未标记的文本来训练问答模型,由未标记文本来提升问答的表现。

但我们会遇到几个困难。首先,标准的半监督学习(semi-supervised learning)方法在这里并不适用。我们比较一下半监督学习的问答设置和标准设置,我们可以看到数据格式是不一样的,例如标记数据中,标准设置只有(x, y)两项,而问答设置则有段落、问题和答案三项。所以我们不能使用标准的半监督学习算法,只能自己另开发出一种新的方法了。

第二个困难是,我们只有少量的标记数据可用,我们该如何利用未标记的文本来提升问答模型的表现呢?
半监督问答模型

针对前面两个问题,我们采用一种修改版的生成对抗网络的方法来构建一个半监督问答模型。首先,我们从未标记的文本出发,我们使用NLP标记以及一些规则从文本中生成可能的“答案”(answers)。我们应该注意这里的标记方式和规则是固定的。随后我们会通过一个问题生成器利用“段落”和“答案”来自动生成“问题”。于是“段落”、“问题”和“答案”就可以视为一个“标记”的数据组了。我们利用这个数据组来训练问答模型中的判别器。不过有几个问题需要解决。首先我们注意到模型生成的数据组和人类注解数据组其分布是不一样的。其次,我们该如何将生成器和判别器连接起来?

针对第一个问题,我们采用域标记的方式来把模型生成的数据和人类生成的数据区分开来。我们用“true”标签来表示人类标记数据,用“fake”标签来表示未标记数据(或模型生成数据)。

如何将生成器和判别器连接起来呢?我们使用自动编码器将“段落”自动编码成一个“01”序列,选为“答案”的部分则为“1”,否则为“0”。通过生成器生成“问题”,随后产生的“答案”也将是“段落”中的“1”。通过比较前后两次“答案”的序列的重合度将得到损失函数。

这张图显示了我们如何通过生成对抗网络来训练半监督问答模型的。首先我们未标记的“段落”和用生成器生成的“问题”来训练辨别器,注意这里用的域标签是“fake”。在右侧的图中,我们训练生成器,不过这里用“true”标签来替代“fake”标签,也即用人类标记的“段落”和“问题”。这种结果对抗训练的结果可以用辨别器对问题答案判别的概率来测量。

这是生成域对抗网络(GDAN)模型的数学公式。模型中,我们选用gated-attention reader来作为辨别器,用seq2seq模型来作为生成器。
模型训练

在我们的GDAN模型中,如果训练没有停止,那么首先我们固定生成器,通过域标签为“fake”的数据,用最陡梯度下降法(SGD)来更新辨别器。另一方面,我们固定辨别器,通过域标签为“true”的数据,用用增强学习法(Reinforce)和最陡梯度下降法来更新生成器。
实验及结果分析

接下来,让我们看一下试验。
我们选取SQuAD的数据作为标记数据,取10%作为测试集。未标记数据则来自Wikipedia,我们从Wikipedia上采集一百万个“段落”,并生成五百万的“答案”,这个量大概是SQuAD的50倍。我们选取四种模型作为对比,分别为SL(监督学习)、Context(使用附近单词作为问题)、GAN(用GAN生成器训练)、AE(用自动编码目标训练)。
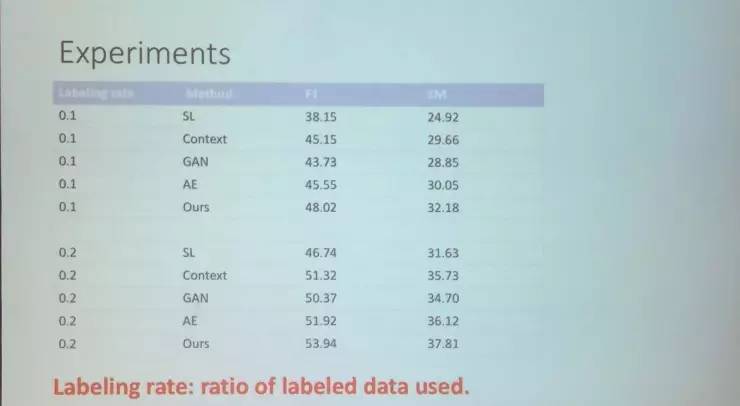
这是我们试验的结果。第一列Labeling rate是我们标记数据使用率。这里0.1,是使用了8000条标记样本。从中可以看到我们的模型无论是F1-score(测试精确度的一种测量)还是EM(Exact matching)上都优于其他几个模型。
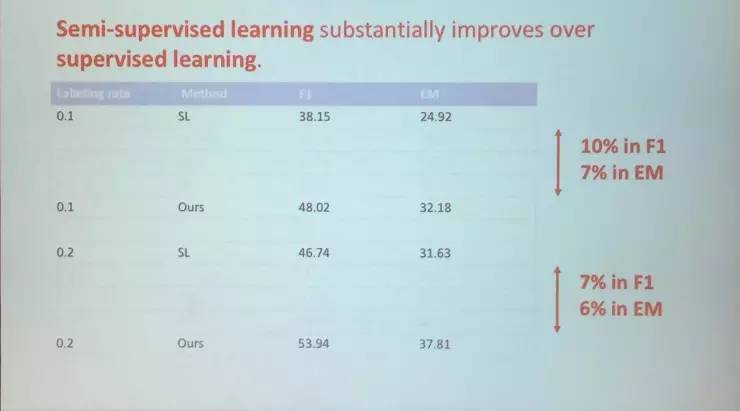
我们先来看与SL模型的对比。我们看到当标记数据使用率为0.1时,我们的模型F1-score要比SL模型高出10%,EM高出7%。当数据使用率为0.2时,仍然能够F1仍然高出7%,EM高出6%。所以我们的模型要远远优于监督学习模型。
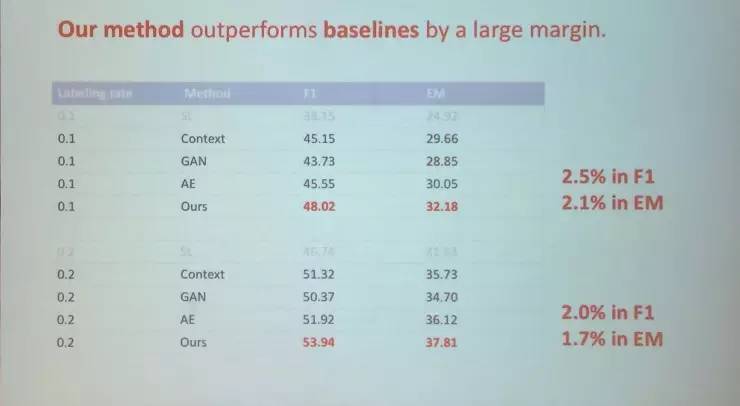
与其他几种模型相比,精确度方面也有很大的提升。
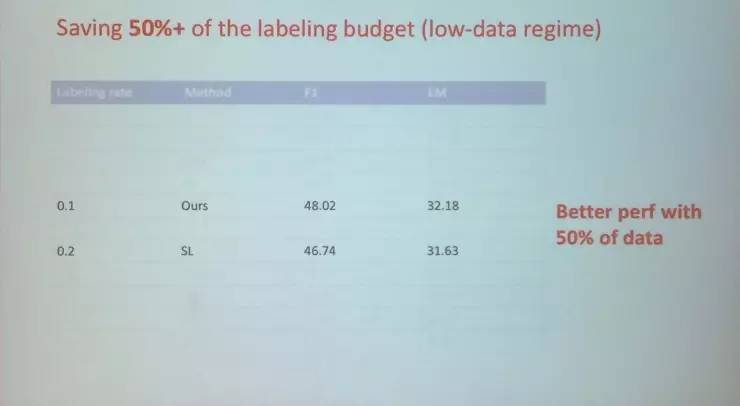
甚至,我们看,当SL模型使用了0.2的数据时,其模型精度也没有我们使用0.1数据时的精度高。所以我们的模型即使只使用一半的数据,仍然比SL模型好。

不过有一个问题是,当标记数据较为丰富时,想要通过增大未标记数据的量很难提升模型的表现。我希望我们以后能解决这个问题。

这张图中展示的是生成的“问题”样本,其中,“Ground truth question”是人工标记的“问题”,“MLE”表示通过最大似然估计方法生成的“问题”,“RL”表示通过增强学习方法生成的“问题”。我们看到,相比于MLE方法生成的“问题”,RL方法生成的“问题”包含更多的信息,更少的“UNK”(unknown)标识。

在这里我们也会看到在生成的“问题”中包含着一些语法错误。不过我们要强调,只要它能够在QA模型中提升模型的表现,出现这些语法错误并没有关系。
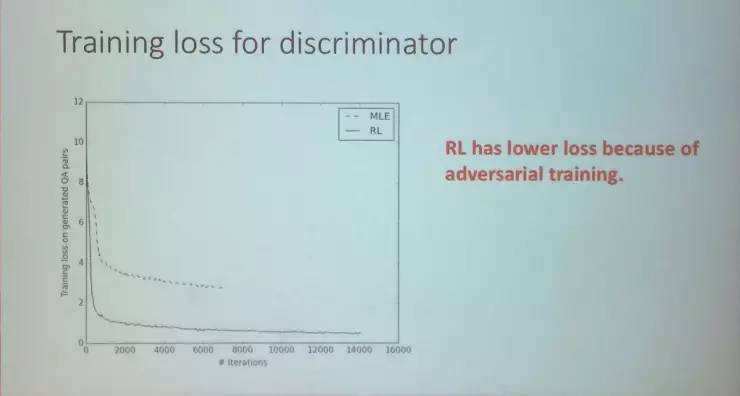
在这张图上我们能更好地看到,随着未标记数据量的增加,生成问答对的训练损失函数将会迅速减下。当数据量达到一定值后,损失函数下降就不怎么明显了。另外,我们还可以看到RL方法要比MLE方法更优,这主要就是对抗训练的结果。
结论

我们在此做一个总结。我们使用少量标记问答数据和大量未标记文本数据设计一个半监督问答模型,这个模型使用了生成对抗模型,不同的是我们增加了域条件来进行对抗增强训练。我们使用Wikipedia文本和SQuAD标记数据来训练模型,我们的结果显示在标记数据较少的时候可以有高达10%的增益。

最后一张,这个网址里有我们所使用的数据。感兴趣的话可以下载下来使用。谢谢大家!
<完>
AI 科技评论整理。
论文下载:https://arxiv.org/pdf/1702.02206.pdf
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————




