今日 Paper | 不确定性量化;边缘感知深度预测;双目深度估计;自适应深度立体匹配等

目录
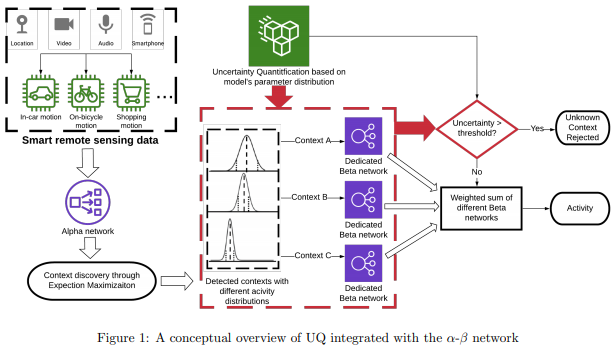
深度上下文感知移动活动识别和未知上下文发现的不确定性量化
StereoNet:基于引导分层优化的实时边缘感知深度预测
移动设备上的任意时间双目深度估计
实时自适应深度立体匹配
CNN合成的图片现在能轻松鉴别了
深度上下文感知移动活动识别和未知上下文发现的不确定性量化
论文名称:Uncertainty Quantification for Deep Context-Aware Mobile Activity Recognition and Unknown Context Discovery
作者:Huo Zepeng /PakBin Arash /Chen Xiaohan /Hurley Nathan /Yuan Ye /Qian Xiaoning /Wang Zhangyang /Huang Shuai /Mortazavi Bobak
发表时间:2020/3/3
论文链接:https://arxiv.org/abs/2003.01753
推荐原因
这篇论文被AISTATS 2020接收,考虑的是可穿戴计算中的活动识别问题。
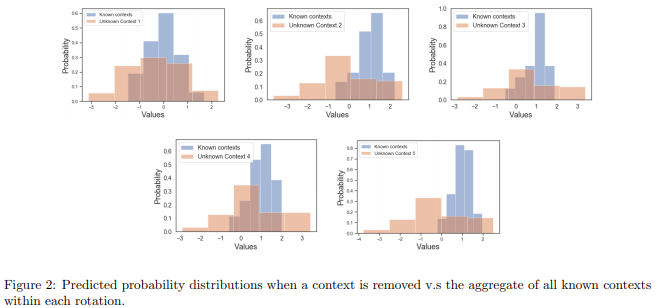
在这个问题中,活动特征可能取决于上下文,而且未知上下文和活动可能会不时发生,这需要算法具有灵活性和适应性。这篇论文提出了一种上下文感知混合模型,称为深度模型α-β网络,结合了基于最大熵的不确定性量化以增强人类活动识别的性能。通过以数据驱动的方式识别高层级上下文来指导模型开发,新模型将准确率和F值提高了10%。为确保训练稳定性,这篇论文在公共和内部数据集中都使用了基于聚类的预训练,以证明通过未知上下文发现可以提高准确率。
StereoNet:基于引导分层优化的实时边缘感知深度预测
论文名称:StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
作者:Khamis Sameh /Fanello Sean /Rhemann Christoph /Kowdle Adarsh /Valentin Julien /Izadi Shahram
发表时间:2018/7/24
论文链接:https://arxiv.org/abs/1807.08865v1
推荐原因
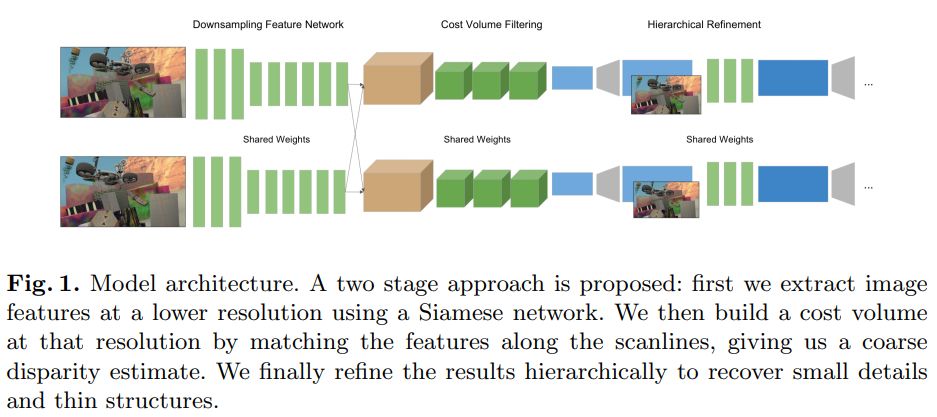
这篇论文提出了第一个实时的双目深度估计网络StereoNet,能够在英伟达Titan X上达到60FPS。论文的亮点主要在网络结构的设计上,StereoNet属于基于3D卷积的立体匹配,cost volume的大小决定了网络的参数量和推理速度。作者发现可以把cost volume设计的比较小,但是它仍然包含了较多的特征信息,只会有较少的精度损失。这样网络可以先得到一个粗糙的视差图。之后作者设计了一种层次化的,边缘敏感的精修网络,实际上是利用卷积网络估计残差,利用残差和粗糙的视差图分层优化,得到更加细致的,保留边缘的视差图。该论文收录在ECCV 2018上,是首次实现实时的双目深度估计。

移动设备上的任意时间双目深度估计
论文名称:Anytime Stereo Image Depth Estimation on Mobile Devices
作者:Wang Yan /Lai Zihang /Huang Gao /Wang Brian H. /van der Maaten Laurens /Campbell Mark /Weinberger Kilian Q.
发表时间:2018/10/26
论文链接:https://arxiv.org/abs/1810.11408v2
推荐原因
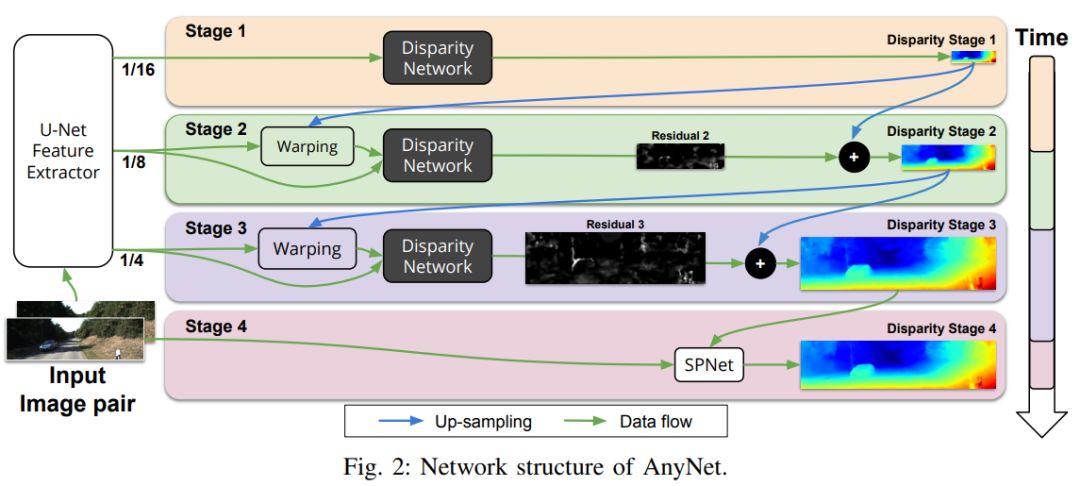
这篇论文提出了一个可以在移动设备上实时运行的双目深度估计网络。作者观察发现深度网络中图像的分辨率大小和需要考虑的最大视差值是影响双目深度估计网络推理速度的两个因素。以此为依据,作者设计了一个多阶段的视差估计网络AnyNet,可以在不同的时间限制下达到不同程度的精度。使用的阶段越少,推理速度越快,相应的准确率就越低。AnyNet只在第一个阶段估计视差,之后的阶段仅估计残差,这样能够提高推理速度。作者还发现最后一个阶段使用SPNet能够获得更加精细的视差图。论文收录在ICRA 2019上,比StereoNet速度更快,精度更高,能够应用于移动设备上,可以为工业界提供较好的学术基础。
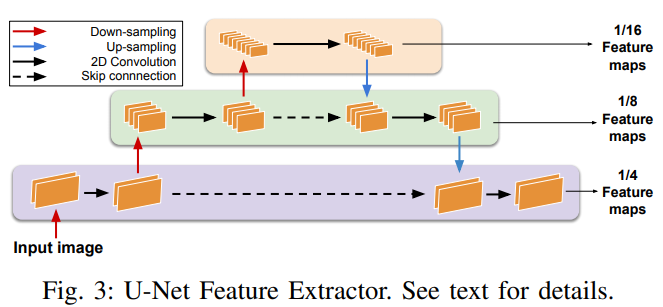
实时自适应深度立体匹配
论文名称:Real-time self-adaptive deep stereo
作者:Tonioni Alessio /Tosi Fabio /Poggi Matteo /Mattoccia Stefano /Di Stefano Luigi
发表时间:2018/10/12
论文链接:https://arxiv.org/abs/1810.05424v2
推荐原因
论文提出了第一个实时的自适应的深度立体匹配网络MADNet。作者设计了一个编码-解码网络作为视差估计网络,编码部分是一个自上而下的金字塔结构,而解码部分是一个自下而上的金字塔结构,每个部分共6层,每层输出不同分辨率的预测视差。传统的完全自适应是采用无监督损失函数直接反向传播,但是这种训练方法在要求实时环境下计算量太大。作者设计了一个自适应调制模块(MAD),采用启发式的方法每次只选择一种分辨率的分支进行反向传播,这样比整个网络都进行反向传播要快很多。MADNet的视差估计速度达到40FPS,在线自适应速度达到15FPS,是在实时自适应深度网络上迈出的第一步。论文为CVPR 2019 Oral。
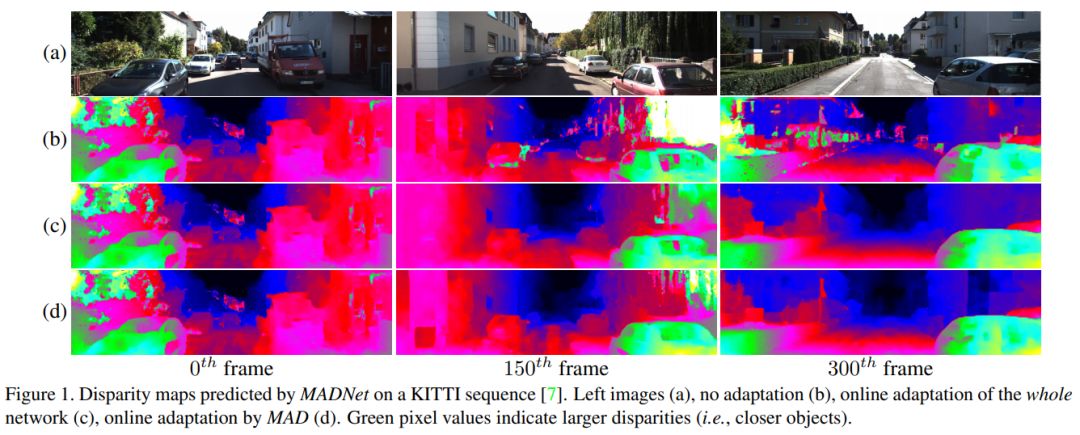
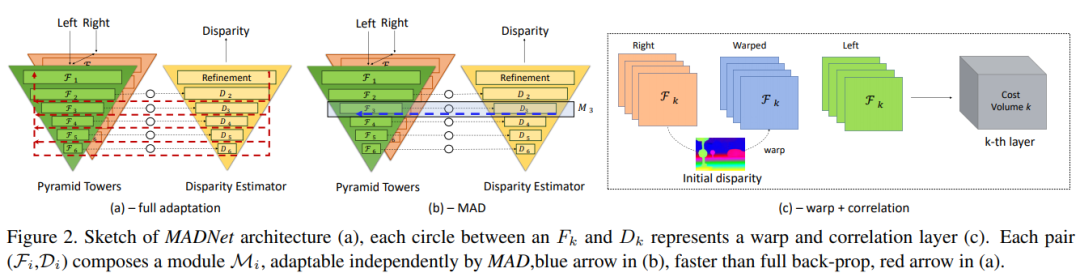
CNN合成的图片现在能轻松鉴别了
论文名称:CNN-generated images are surprisingly easy to spot... for now
作者:Wang Sheng-Yu /Wang Oliver /Zhang Richard /Owens Andrew /Efros Alexei A.
发表时间:2019/12/23
论文链接:https://arxiv.org/abs/1912.11035v1
推荐原因
这篇论文主要探索如何利用单一的GAN模型来鉴别其他各种GAN生成的图像。无论各种GAN生成的图像是何种类型,使用何种网络结构,合成的假图都用相同的缺陷。作者首先利用11种GAN模型来构造一个大规模的合成图像鉴别数据库,ForenSynths Datsets。之后仅仅利用单一的ProGAN模型来训练,就能够在ForenSynths上表现出良好的泛化性能,甚至可以打败新出的StyleGAN2和DeepFake。作者通过实验表明数据增强作为后处理方法,以及训练数据的多样性是成功的关键,尤其是数据增强使得训练一个鉴别器就有良好的泛化能力和鲁棒性。这篇论文收录在CVPR 2020,是反造假技术再进一步的标志。造假和反造假技术一直在共同进步。


