运用多源分词信息助力中文NER 邱震宇

作者:邱震宇(华泰证券股份有限公司 算法工程师)
知乎专栏:我的ai之路
最近两年,做中文的NER任务一般都会对字符级的数据进行处理,同时使用BERT模型,这通常会取得不错的效果。然而这种方式并没有充分利用好词汇级别的信息,因此最近一段时间有很多工作都尝试将词汇信息融入到字符级的中文NER建模中,例如Lattice-LSTM以及ACL2020上提出的Simple lexicon方法,这些方法的总结均可以在JayLou的文章中看到,链接如下:JayLou娄杰:中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT)
那么问题来了,为何那么多研究致力于使用各种方法将词汇信息通过不同媒介与字符编码信息进行整合呢?直接将词汇信息编码按照其组成字符个数复制N个,然后直接与字符编码进行融合,这种方法不是更简单直接?事实上,我之前还真实验过这种操作,从结果上来说这种方法只能在很小的程度上提升效果,几乎可以忽略不计(详见我的中文NER相关文章),有时候还会有反效果。从原理上看,这种方法有两个弊端:
1、使用的是现成的分词工具,对于当前语料来说,会有一定的误差,这种误差会在模型的学习过程中被不断传递,导致模型的学习被影响。
2、词汇信息与字符信息的整合太简单,字符信息无法充分理解分词中的边界信息。
目前大部分的词汇增强方法基本上都是以解决上述问题为目标,角度各不相同。然而,还未有方法试图对多个不同的分词工具源进行整合,以降低分词工具的误差传递影响。俗话说得好,三个臭皮匠,顶个诸葛亮,与模型融合的思想类似,如果能将多个成熟的分词工具的能力进行整合,应当是能得到比单分词工具更好的效果。
本文要介绍的论文就是基于这个思想。论文名为Enhancing Pre-trained Chinese Character Representation with Word-aligned Attention,也是ACL2020上的一篇文章。
方法原理
假设我们当前有M个分词工具,每个分词工具均得到一个分词结果。论文里选用了thulac、ictclas、hanlp。我在实验的时候选择的百度的LAC2.0、thulac以及LTP3。不同的分词工具会对同一个文本产生不同粒度的分词结果,实例如下:
"baidu": ["我们", "变而以书会友", ",", "以", "书", "结缘", ",", "把", "欧美", "、", "港台", "流行", "的", "食品类", "图谱", "、", "画册", "、", "工具书", "汇集", "一堂", "。"]
"thu": ["我们", "变", "而", "以", "书", "会", "友", ",", "以", "书", "结缘", ",", "把", "欧", "美", "、", "港", "台", "流行", "的", "食品类", "图谱", "、", "画册", "、", "工具书", "汇集", "一", "堂", "。"]
"ltp": ["我们", "变", "而", "以", "书", "会", "友", ",", "以", "书", "结缘", ",", "把", "欧", "美", "、", "港", "台", "流行", "的", "食品类", "图谱", "、", "画册", "、", "工具书", "汇集", "一", "堂", "。"]
"ner_label":我 们 变 而 以 书 会 友 , 以 书 结 缘 , 把 欧 美 、 港 台 流 行 的 食 品 类 图 谱 、 画 册 、 工 具 书 汇 集 一 堂 。
O O O O O O O O O O O O O O O B-LOC B-LOC O B-LOC B-LOC O O O O O O O O O O O O O O O O O O O O
与NER的标签进行对比可以发现,对于这个例子来说,thu和ltp的分词粒度更加合适,因为NER把欧、美、港、台分开抽取了。然而,其他一些例子中,就不一定是这种情况。从这个角度来看,整合多个分词工具信息确实是有必要的。
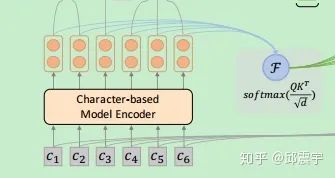
本文的方法大致分为两个核心模块,第一个是如何将分词边界信息与字符编码信息进行整合;第二个是如何将不同分词工具信息进行整合。
首先讲一下第二部分。假设第一部分,每个分词工具得到的词汇+字符整合编码表示为 


接下来说一下本文比较重要的分词边界信息融合模块。以上述的百度分词结果为例,使用 

表示分词后的词序列,其中 

注1:这里我本来觉得有点多余,为何不直接用BERT中最后一层的attention矩阵呢?后来我实际验证了下,发现直接用attention矩阵效果很差不少,推测应该是由于原始transformer在attention计算后还有残差计算和layernorm,保留的信息还是比attention矩阵多的。
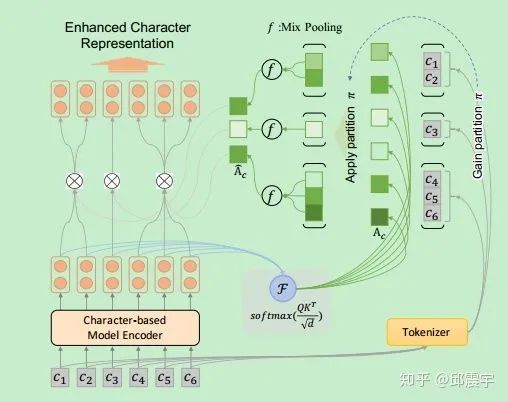
按照前文所说,因为字符在不同词中的上下文信息都会不同,因此为了能够尽可能将词汇边界信息融入到字符编码中,论文提出了一种word-aligned attention方法。我们将



然后,论文使用了一种upsampling的方式,将上述的词编码信息扩展至字符粒度的序列,这么做的原因是为了之后与BERT的字符编码信息输出进行整合,需要维度保持一致。论文专门放了个upsampling的公式,其实很简单,就是将该词包含的所有字符在原始字符串中的位置都赋予 

最后,我们将上述增强后的attention矩阵与原始字符编码信息H计算得到context分数:




注2:关于这里的多注意头机制我本身也有一些疑惑,个人认为字符编码信息本身就包含了多注意头的计算,而词汇的编码信息使用似乎使用单头就可以充分捕捉到。详细的在下一小节的实现中会细说。
实现小结
虽然论文中给出了开源的代码链接,然而工程中只有模型的定义代码。因此我自己根据模型定义代码,扩充了数据准备和训练的流程,顺便温习了一下pytorch代码。这里得重点提一下该方法的实现效率,有一说一,该方法的效率确实比较慢,根据其代码的实现方式,由于需要根据不同分词的子串对不同长度的字符向量集合进行pooling的计算,因此很难实现一个高效的并行化计算,简而言之,就是必须使用for循环来处理序列,这样的话,即使用大batch_size,也无法提升GPU的使用效率。具体代码如下所示:
def calculate_scale(self, att_weights, seg_slice, seg_length):
batch_size, head_num, seq_len_row, seq_len_col = att_weights.size()
batch_size = int(batch_size)
mask = torch.zeros(att_weights.size()).to(seg_length.device)
# iterate till encounter padding tag, for early stopping and accelerate.
stop_condition = (seg_length != 0).sum(dim=1)
for batch_idx in range(batch_size):
if att_weights[batch_idx].nelement() == 0:
continue
for s in range(int(stop_condition[batch_idx])):
token_pos = seg_slice[batch_idx][s]
token_length = seg_length[batch_idx][s]
if token_pos > stop_condition[batch_idx]:
break
if bool(token_length > 1):
att = att_weights[batch_idx, :, :, token_pos: token_pos + token_length]
if att.nelement() == 0:
continue
mean = att.mean(-1, keepdim=True) # .repeat(att.size(0))
max = att.max(-1, keepdim=True)[0]
# try to make attention more balanced
# mean = mean * (att <= mean).float() + att * (att > mean).float()
mix = max * self.mix_lambda + mean * (torch.tensor(1).to(seg_length.device) - self.mix_lambda)
mask[batch_idx, :, :, token_pos: token_pos + token_length] = mix / att
else:
mask[batch_idx, :, :, token_pos: token_pos + token_length] = \
torch.ones([head_num, seq_len_row, token_length])
return mask经过本人的亲自试验,在加入该方法后,所需的训练时间是原来模型的3倍。因此,如果要运用在实际业务中的话,性价比不是太高,但是如果用在一些比赛中的话,还算是一个提分利器。
数据准备方面,相对于原始的NER任务,多了两个输入,一个是seg_slice,另一个是seg_length。前一个是分词后,每个词首字符在原始字符串中的位置index;后一个则是每个词的长度列表。以百度的分词为例,上文例子的seg_slice为[0,2,8,9,10,11,13,14,15,17,18,20,22,23,26,28,29,31,32,35,37,39,40];seg_length为[2,6,1,1,1,2,1,1,2,1,2,2,1,3,2,1,2,1,3,2,2,1]。
当然,上述例子没有考虑[CLS]和[SEP]的情况,实际实现的时候需要考虑进去。
另外,我使用的数据集仍然是之前使用的MSRA的中文NER数据集。
多头是否适用所有场景?
我在最初实现的时候,确实是使用了多头注意力机制,然而实现出来的效果确实不佳。原始的BERT+softmax模型在test数据集上大概有0.943的f1分数(整合了实体词+实体类型的span-level f1)。使用了本文的方法,基于多头注意力机制,在几次试验中,均只能得到0.940左右的分数,基本没有提升。后来,我逐渐降低了注意力头的个数,从12减到了6,再从6减到了1。最终的效果居然是越来越好,把注意力头减到1时,能够得到0.951左右的分数,基本上能有0.8-1的提升。这个结果至少可以说明多头注意力机制并非对所有的数据集均适用,还需要多方测试。
是否适用于CRF层?
另外,我还实验了论文方法与CRF结合会产生什么样的效果。结果有点意外,在加入了CRF层后,论文方法并不能得到效果的提升,另外,训练的速度也直线下降。推测可能是我没有单独对CRF设置单独的学习率,使得CRF层的权重参数没有充分学习。不过,我对原始的BERT+CRF方法训练设置也是一样的,因此关于这块至今我还有点疑惑。欢迎对此问题有见解的朋友随时交流。
多源分词工具是否有效?
与论文一样,我也实验了使用多个分词工具是否有效。我尝试了只是用一种分词工具,与同时使用三种分词工具进行了比较,得出的结论确实如论文所说,使用单个分词工具相对于原始方法一般有0.5左右的提升,提升幅度与多源分词工具相比略少。
其他
实现方面,除了上述注意点外,我还在注意力机制计算的部分添加了dropout,另外,训练的优化方法采用了论文中的BertAdam,同时使用了线性warmup机制,学习率则采用了2e-5。
论文中的效果
最后贴一下论文中的实验效果,在很多任务上都有提升:
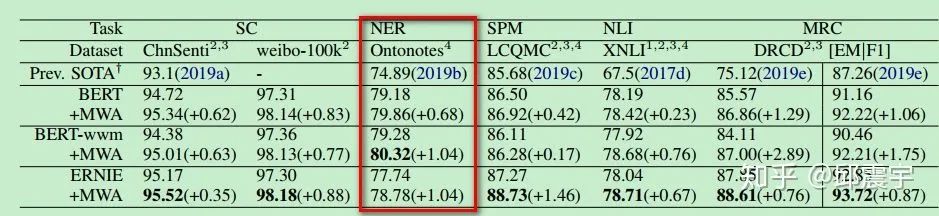
另外,论文提到该方法在MRC上的提升普遍较高,是因为MRC中需要抽取答案的边界,因此引入多源词汇信息后,效果更佳。
总结
本次解读的论文总体上来说,方法较为简单,通过分词后的边界信息与字符编码建立word-aligned的attention上下文信息,并融合多个不同的成熟分词工具,缓解了分词带来的误差传递影响。然而在实现上,该方法的效率比较慢,训练时间较长,是原始模型的3倍左右,因此在实际业务中的应用还需谨慎考虑。
最后,我对于论文的实现代码均集成到了我的ner工程中,具体链接如下:
https://github.com/qiufengyuyi/sequence_tagging
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/186223583

推荐阅读
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏




