ACL 2018 | 利用Lattice LSTM的最优中文命名实体识别方法
选自arXiv
作者:Yue Zhang、Jie Yang
机器之心编译
参与:路、王淑婷
| 本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
近日,来自新加坡科技设计大学的研究者在 arXiv 上发布了一篇论文,介绍了一种新型中文命名实体识别方法,该方法利用 Lattice LSTM,性能优于基于字符和词的方法。与基于字符的方法相比,该模型显性地利用词和词序信息;与基于词的方法相比,lattice LSTM 不会出现分词错误。这篇论文已被 ACL 2018 接收。
作为信息抽取的一项基本任务,命名实体识别(NER)近年来一直受到研究人员的关注。该任务一直被作为序列标注问题来解决,其中实体边界和类别标签被联合预测。英文 NER 目前的最高水准是使用 LSTM-CRF 模型实现的(Lample et al., 2016; Ma and Hovy, 2016; Chiu and Nichols, 2016; Liu et al., 2018),其中字符信息被整合到词表征中。
中文 NER 与分词相关。命名实体边界也是词边界。执行中文 NER 的一种直观方式是先执行分词,然后再应用词序列标注。然而,分割 → NER 流程可能会遇到误差传播的潜在问题,因为 NE 是分割中 OOV 的重要来源,并且分割错误的实体边界会导致 NER 错误。这个问题在开放领域可能会很严重,因为跨领域分词仍然是一个未解决的难题(Liu and Zhang, 2012; Jiang et al., 2013; Liu et al., 2014; Qiu and Zhang, 2015; Chen et al., 2017; Huang et al., 2017)。已有研究表明,中文 NER 中,基于字符的方法表现要优于基于词的方法(He and Wang, 2008; Liu et al., 2010; Li et al., 2014)。
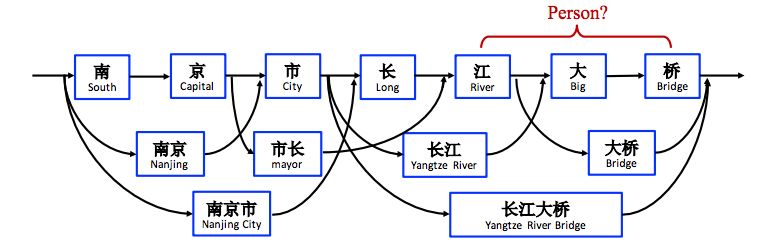
图 1:词-字符网格。
基于字符的 NER 的一个缺陷在于无法充分利用显性的词和词序信息,而它们是很有用的。为了解决这一问题,本论文研究者利用 lattice LSTM 来表征句子中的 lexicon word,从而将潜在词信息整合到基于字符的 LSTM-CRF 中。如图 1 所示,研究者使用一个大型自动获取的词典来匹配句子,进而构建基于词的 lattice。因此,词序如「长江大桥」、「长江」和「大桥」可用于语境中的潜在相关命名实体消歧,如人名「江大桥」。
由于在网格中存在指数级数量的词-字符路径,因此研究者利用 lattice LSTM 结构自动控制从句子开头到结尾的信息流。如图 2 所示,门控单元用于将来自不同路径的信息动态传送到每个字符。在 NER 数据上训练后,lattice LSTM 能够学会从语境中自动找到更有用的词,以取得更好的 NER 性能。与基于字符和基于词的 NER 方法相比,本论文提出的模型的优势在于利用利用显性的词信息而不是字符序列标注,且不会出现分词误差。
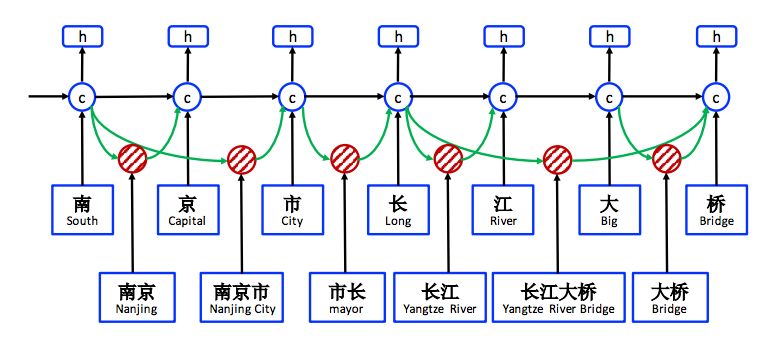
图 2:Lattice LSTM 结构。
结果显示该模型显著优于基于字符的序列标注模型和使用 LSTMCRF 的基于词的序列标注模型,在不同领域的多个中文 NER 数据集上均获得最优结果。
模型
研究者遵循最好的英文 NER 模型(Huang et al., 2015; Ma and Hovy, 2016; Lample et al., 2016),使用 LSTM-CRF 作为主要网络结构。形式上,指定输入句子为 s = c_1, c_2, . . . , c_m,其中 c_j 指第 j 个字符。s 还可以作为词序列 s = w_1, w_2, . . . , w_n,其中 w_i 指句子中的第 i 个词,使用中文分词器获得。研究者使用 t(i, k) 来指句子第 i 个词中第 k 个字符的索引 j。以图 1 中的句子为例。如果分词是「南京市 长江大桥」,索引从 1 开始,则 t(2, 1) = 4 (长),t(1, 3) = 3 (市)。研究者使用 BIOES 标记规则(Ratinov and Roth, 2009)进行基于词和基于字符的 NER 标记。
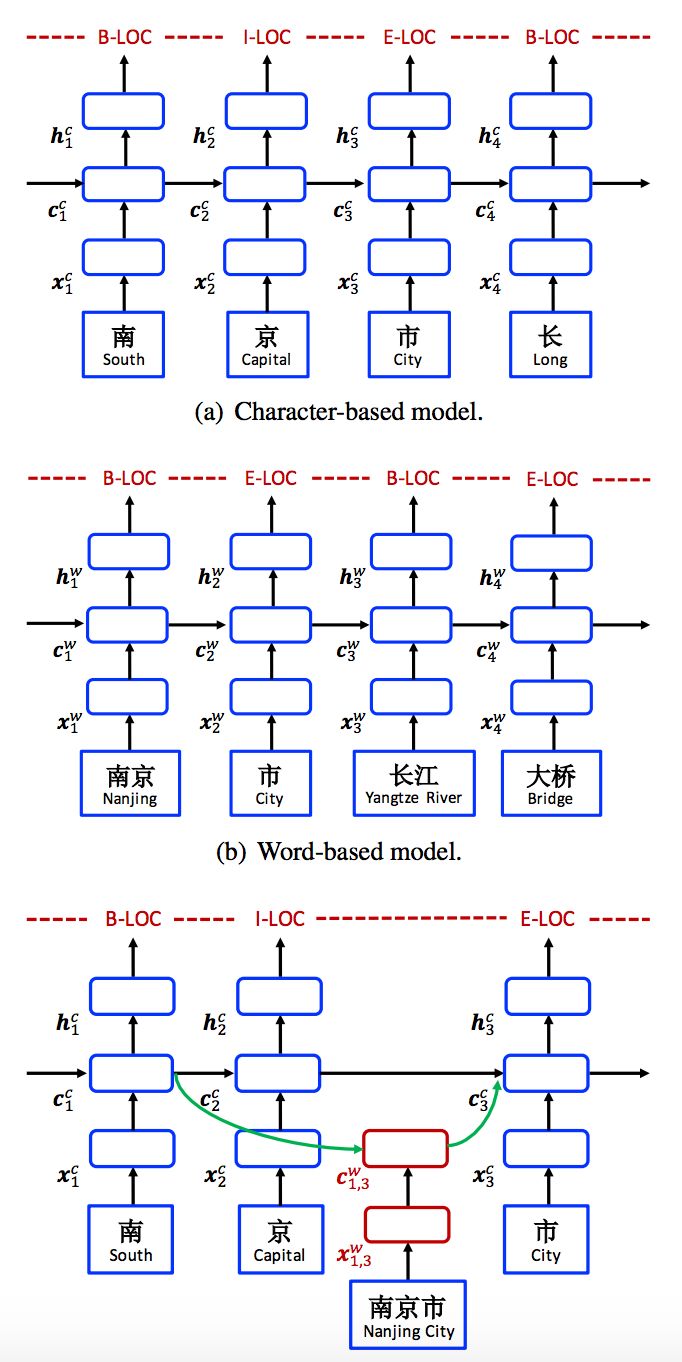
图 3:模型。
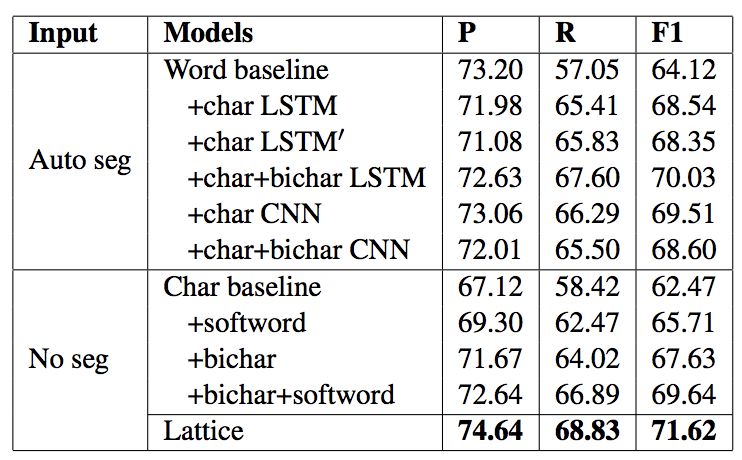
表 4:在开发集上的结果。
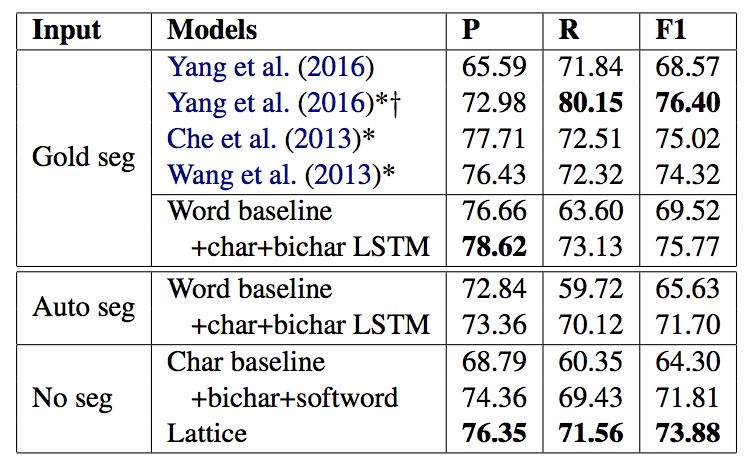
表 5:在 OntoNotes 上的主要结果。
论文:Chinese NER Using Lattice LSTM

论文链接:https://arxiv.org/abs/1805.02023
项目链接:https://github.com/jiesutd/LatticeLSTM
摘要:我们研究了用于中文命名实体识别(NER)的 lattice LSTM 模型,该模型对输入字符序列和所有匹配词典的潜在词汇进行编码。与基于字符的方法相比,该模型显性地利用词和词序信息。与基于词的方法相比,lattice LSTM 不会出现分词错误。门控循环单元使得我们的模型能够从句子中选择最相关的字符和词,以生成更好的 NER 结果。在多个数据集上的实验证明 lattice LSTM 优于基于词和基于字符的 LSTM 基线模型,达到了最优的结果。



推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
 欢迎关注交流
欢迎关注交流





