DSN:基于深度强化学习,无监督生成视频摘要
随着在线视频数量的爆炸式增长,想从茫茫网络世界中找到自己想要的视频可是要费一番功夫。于是有人就想到,何不也给视频创作一份摘要呢?就像书的简介一样,观众只需要看看摘要,就了解视频的大概内容了。
这的确是个好方法,不过面对如此庞大的视频库,如何大批量处理它们呢?在此之前,许多研究者提出了不同的方法为视频大规模创建摘要,例如循环神经网络(RNN)、长短期记忆(LSTM)、双向长短期记忆网络(bidirectional LSTM)和行列式点处理(DPP)模块结合的方式等等。但都是需要监督的总结方式,其中并没有一个针对所有视频的标准答案(ground truth)。所以仍然需要无监督的摘要生成方式。
中科院和英国伦敦大学玛丽女王学院的研究人员就生成视频摘要提出了一种新方法,采用无监督学习的方法,用深度摘要网络(Deep Summarization Network,DSN)总结视频。整个过程为连续决策过程(sequential decision-making process),DSN为编码-解码结构,其中编码器是一个能够提取视频帧特征的卷积神经网络,解码器是一个双向LSTM网络,能够基于被选中的动作生成概率。在训练过程中,研究人员设计了新颖的多样性-代表性奖励(diversity-representativeness reward)函数,可以直接判断生成视频摘要的多样化和代表化。下图是该模型学习过程的图示:
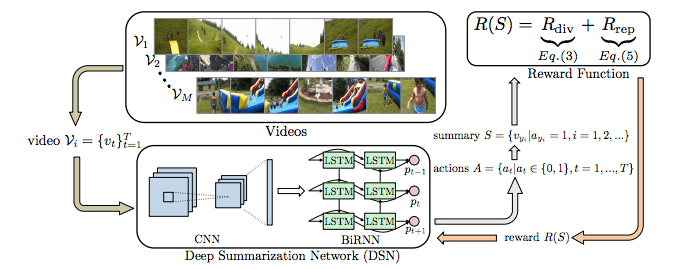
深度摘要网络(DSN)
DSN的编码器是一个卷积神经网络,它从输入的长度为T的视频框架{vt}t=1T中提取视觉特征{xt}t=1T。解码器是一个双向循环神经网络(BiRNN),最上面是完全连接层。将提取的{xt}t=1T输入到解码器后,生成相应的隐藏状态{ht}t=1T。每个ht都是前隐藏状态htf和后隐藏状态htb的连接。在实践中,研究人员采用GoogLeNet当做CNN模型,并且用LSTM训练提升RNN的性能。
多样性-代表性奖励函数
在训练时,DSN会接收到一个奖励R(S),来评估生成的摘要。而DSN的目标是不断生成高质量的视频摘要,让奖励最大化。通常,高质量的视频摘要必须既有代表性,又丰富多彩。为了达到这一目的,研究人员提出了一种新颖的奖励方式,它由多样性奖励Rdiv和代表性奖励Rrep组成。
在多样性奖励中,Rdiv可以用以下公式表示:
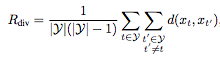
y表示已选中的帧,d(xt,xt')是多样化公式,如下表示:
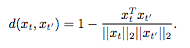
选出的视频帧越多样(越不相像),agent收到的多样性奖励越高。
而代表性奖励函数主要是测量生成的摘要是否能总结原始视频,研究人员将其看成k中心点问题,将Rrep定义为:
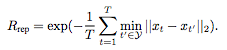
在这个奖励之下,agent能够选出最接近特征空间聚类中心的帧。
最后,Rdiv和Rrep共同工作,指导DSN学习:
R(S)=Rdiv+Rrep
实验测试
该模型在SumMe和TVSum两个数据集上进行测试。SumMe有25个用户视频,涵盖了假期和运动等多种话题。其中的视频长度约为1至6分钟,都经过了15至18人进行标注,所以每段视频都有多个标准摘要(ground truth)。TVSum中有50段视频,包括新闻、纪录片等,长度2到10分钟不等,每段都有20人标注。除此之外还有另外两个数据集,OVP和YouTube,用来测试强化后的模型。
在进行比较时,研究人员分了好几种情况进行对比:只用多样性奖励函数进行训练(用D-DSN表示)、只用代表性奖励函数进行训练(用R-DSN表示)、两种函数都有的(用DR-DSN表示)。另外,还将模型扩展到监督学习的实验中,用DR-DSNsup表示。在SumMe和TVSum上不同版本的结果如下表所示:
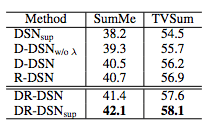
可以看到,DR-DSN的结果明显优于D-DSN和R-DSN,同时与DSNsup相比,DR-DSN的结果也非常出色。
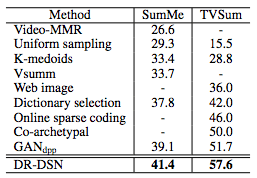
接着,研究人员将DR-DSN与其他无监督方法进行比较,可以看到,DR-DSN在两个数据集上比其它方法表现得都好,并且差距非常明显。如下图所示:
另外,在与其他监督式方法的比较中,DR-DSNsup也是完胜:
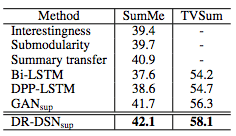
这些结果有力地证明了DSN框架的有效性。
质量评估
研究人员挑选了一段一个男人自制辣香肠三明治的视频作为质量评估的素材。
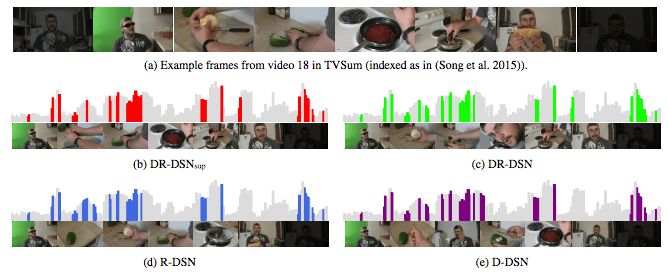
上图中可以看到,四种方法都生成了高质量的视频摘要,它们都均匀选取了视频的每一过程。不过最接近完整故事线的是DR-DSNsup,因为它展示了从准备食材到制作的全过程。
接着研究人员对原始预测(raw prediction)进行可视化,通过比较预测和原视频,我们可以更深入地了解DSN学习的情况。
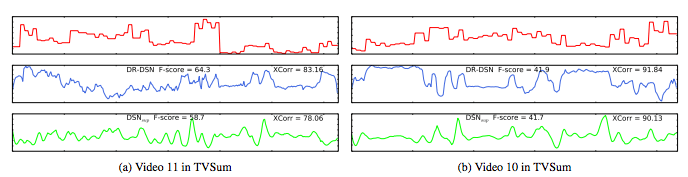
可以看到,无监督模型预测的重要性曲线与监督模型预测的有几处相似,并且这些地方与之前人们标注认为重要的地方相吻合。这充分表明,通过多样性-代表性奖励函数训练过的强化学习能很好地模仿人类学习过程,并有效地教DSN认出视频中重要的帧。
原文地址:arxiv.org/pdf/1801.00054.pdf







