【AlphaGo Zero 核心技术-深度强化学习教程笔记05】不基于模型的控制
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第五讲 不基于模型的控制
《强化学习》第六讲 价值函数的近似表示
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践一 迭代法评估4*4方格世界下的随机策略
强化学习实践二 理解gym的建模思想
强化学习实践三 编写通用的格子世界环境类
强化学习实践四 Agent类和SARSA算法实现
强化学习实践五 SARSA(λ)算法实现
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天《强化学习》第五讲 不基于模型的预测;
某种程度上来说,这个课程所有的内容最后都会集中于本讲内容,通过本讲的学习,我们将会学习到如何训练一个Agent,使其能够在完全未知的环境下较好地完成任务,得到尽可能多的奖励。本讲是基础理论部分的最后一讲,本讲以后的内容都是关于实际应用强化学习解决大规模问题的理论和技巧。本讲的技术核心主要基于先前一讲以及更早的一些内容,如果对先前的内容有深刻的理解,那么理解本讲内容将会比较容易。
简介 Introduction
上一讲主要讲解了在模型未知的情况下如何进行预测。所谓的预测就是评估一个给定的策略,也就是确定一给定策略下的状态(或状态行为对)的价值函数。这一讲的内容主要是在模型未知的条件下如何优化价值函数,这一过程也称作模型无关的控制。
现实中有很多此类的例子,比如控制一个大厦内的多个电梯使得效率最高;控制直升机的特技飞行,机器人足球世界杯上控制机器人球员,围棋游戏等等。所有的这些问题要么我们对其模型运行机制未知,但是我们可以去经历、去试;要么是虽然问题模型是已知的,但问题的规模太大以至于计算机无法高效的计算,除非使用采样的办法。本节的内容就专注于解决这些问题。
根据优化控制过程中是否利用已有或他人的经验策略来改进我们自身的控制策略,我们可以将这种优化控制分为两类:
一类是现时策略学习(On-policy Learning),其基本思想是个体已有一个策略,并且遵循这个策略进行采样,或者说采取一系列该策略下产生的行为,根据这一系列行为得到的奖励,更新状态函数,最后根据该更新的价值函数来优化策略得到较优的策略。由于要优化的策略就是当前遵循的策略,这里姑且将其翻译为“现时策略”。
另一类是离线策略学习(Off-policy Learning): 其基本思想是,虽然个体有一个自己的策略,但是个体并不针对这个策略进行采样,而是基于另一个策略进行采样,这另一个策略可以是先前学习到的策略,也可以是人类的策略等一些较为优化成熟的策略,通过观察基于这类策略的行为,或者说通过对这类策略进行采样,得到这类策略下的各种行为,继而得到一些奖励,然后更新价值函数,即在自己的策略形成的价值函数的基础上观察别的策略产生的行为,以此达到学习的目的。这种学习方式类似于“站在别人的肩膀上可以看得更远”。由于这些策略是已有的策略,这里姑且翻译为“离线策略”。
先从简单的“现时策略”开始讲解。
现时策略蒙特卡洛控制 On-Policy Monte-Carlo Control
在本节中我们使用的主要思想仍然是动态规划的思想。先来回顾下动态规划是如何进行策略迭代的。
通用策略迭代(回顾)
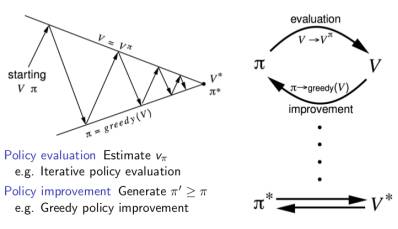
通用策略迭代的核心是在两个交替的过程之间进行策略优化。一个过程是策略评估,另一个是改善策略。如上图的三角形区域所示,从一个策略π和一个价值函数V开始,每一次箭头向上代表着利用当前策略进行价值函数的更新,每一次箭头向下代表着根据更新的价值函数贪婪地选择新的策略,说它是贪婪的,是因为每次都采取转移到可能的、状态函数最高的新状态的行为。最终将收敛至最优策略和最优价值函数。
注意使用动态规划算法来改善策略是需要知道某一状态的所有后续状态及状态间转移概率
不基于模型控制的两个条件
那么这种方法是否适用于模型未知的蒙特卡洛学习呢?答案是否定的,这其中至少存在两个问题。其一是在模型未知的条件下无法知道当前状态的所有后续状态,进而无法确定在当前状态下采取怎样的行为更合适。解决这一问题的方法是,使用状态行为对下的价值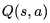
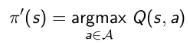
这样做的目的是可以改善策略而不用知道整个模型,只需要知道在某个状态下采取什么什么样的行为价值最大即可。具体是这样:我们从一个初始的Q和策略π开始,先根据这个策略更新每一个状态行为对的q值,s随后基于更新的Q
确定改善的贪婪算法。
即使这样,至少还存在一个问题,即当我们每次都使用贪婪算法来改善策略的时候,将很有可能由于没有足够的采样经验而导致产生一个并不是最优的策略,我们需要不时的尝试一些新的行为,这就是探索(Exploration),使用一个示例来解释:
示例——贪婪行为选择
如图:在你面前有两扇门,考虑如下的行为、奖励并使用贪婪算法改善策略:


这种情况下,打开右侧门是否就一定是最好的选择呢?答案显而易见是否定的。因此完全使用贪婪算法改善策略通常不能得到最优策略。为了解决这一问题,我们需要引入一个随机机制,以一定的概率选择当前最好的策略,同时给以其它可能的行为一定的几率,这就是Ɛ-贪婪探索。
Ɛ-贪婪探索
Ɛ-贪婪探索的目标使得某一状态下所有可能的行为都有一定非零几率被选中执行,也就保证了持续的探索,
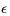
的概率在所有可能的行为中选择(也包括那个当前最好的行为)。数学表达式如下:
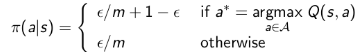
定理:使用Ɛ-贪婪探索策略,对于任意一个给定的策略π,我们在评估这个策略的同时也总在改善它。
证明:
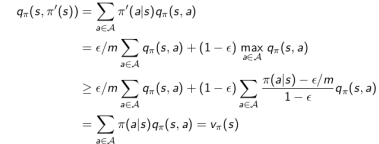
注:在证明上述定理过程中使用的不等式是在经过合理、精心设计的。
解决了上述两个问题,我们最终看到蒙特卡洛控制的全貌:使用Q函数进行策略评估,使用Ɛ-贪婪探索来改善策略。该方法最终可以收敛至最优策略。如下图所示:
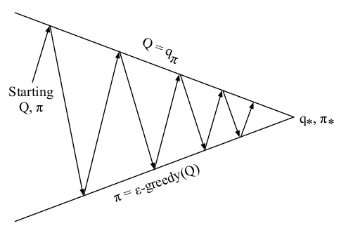
图中每一个向上或向下的箭头都对应着多个Episode。也就是说我们一般在经历了多个Episode之后才进行依次Q函数更新或策略改善。实际上我们也可以在每经历一个Episode之后就更新Q函数或改善策略。但不管使用那种方式,在Ɛ-贪婪探索算下我们始终只能得到基于某一策略下的近似Q函数,且该算法没没有一个终止条件,因为它一直在进行探索。因此我们必须关注以下两个方面:一方面我们不想丢掉任何更好信息和状态,另一方面随着我们策略的改善我们最终希望能终止于某一个最优策略,因为事实上最优策略不应该包括一些随机行为选择。为此引入了另一个理论概念:GLIE。
GLIE
GLIE(Greedy in the Limit with Infinite Exploration),直白的说是在有限的时间内进行无限可能的探索。具体表现为:所有已经经历的状态行为对(state-action pair)会被无限次探索;另外随着探索的无限延伸,贪婪算法中Ɛ值趋向于0。例如如果我们取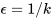
基于GLIE的蒙特卡洛控制流程如下:

定理:GLIE蒙特卡洛控制能收敛至最优的状态行为价值函数。
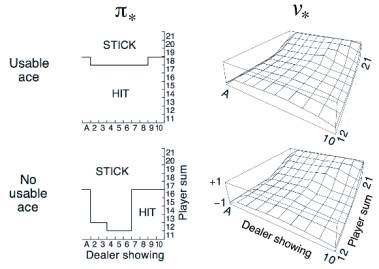
示例——二十一点游戏的最优策略
该图最终给出了二十一点比赛时的最优策略,但借用David的话,本文对于使用该策略进行赌博导致的输赢不负任何责任。
最优策略是这样:当你手上有可用A时,大多数情况下当你的牌面和达到17或18时停止要牌,如果庄家可见的牌面在2-9之间,你选择17,其它条件选择18;当你手上没有A时,最优策略提示大多数情况下牌面和达到16就要停止叫牌,当庄家可见的牌面在2-7时,这一数字更小至13甚至12。这种极端情况下,宁愿停止叫牌等待让庄家的牌爆掉。
现时策略时序差分控制
On-Policy Temporal-Difference Control
上一讲提到TD相比MC有很多优点:低变异性,可以在线实时学习,可以学习不完整Episode等。因此很自然想到是否可以在控制问题上使用TD学习而不是MC学习?答案是肯定的,这就是下文要讲解的SARSA。
SARSA
SARSA名称来源于下图所示的序列描述:针对一个状态S,以及一个特定的行为A,进而产生一个状态行为对(SA)),与环境交互,环境收到个体的行为后会告诉个体即时奖励R以及后续进入的状态S';接下来个体遵循现有策略产生一个行为A',根据当前的状态行为价值函数得到后一个状态行为对(S'A')的价值(Q)利用这个Q值更新前一个状态行为对(SA)的价值。
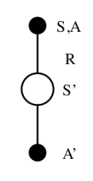
更直观的解释是这样:一个Agent处在某一个状态S,在这个状态下它可尝试各种不同的行为,当遵循某一策略时,会根据当前策略选择一个行为A,个体实际执行这个行为,与环境发生实际交互,环境会根据其行为给出即时奖励R,并且进入下一个状态S',在这个后续状态S',再次遵循当前策略,产生一个行为A',此时,个体并不执行该行为,而是通过自身当前的状态行为价值函数得到该S'A'
状态行为对的价值,利用该价值同时结合个体S状态下采取行为A所获得的即时奖励来更新个体在S状态下采取A行为的(状态)行为价值。与蒙特卡洛控制不同的时,每一个时间步,也就是在单个Episode内每一次个体在状态
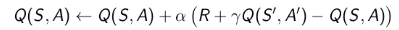
现时策略控制的SARSA算法

注:
算法中的
是以一张大表存储的,这不适用于解决规模很大的问题;
对于每一个Episode,在S状态时采用的行为A是基于当前策略的,同时该行为也是实际Episode发生的行为,在更新SA状态行为对的价值循环里,个体并不实际执行在S'下的A'行为,而是将行为A'留到下一个循环执行。
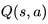 是以一张大表存储的,这不适用于解决规模很大的问题;
是以一张大表存储的,这不适用于解决规模很大的问题;定理:满足如下两个条件时,Sarsa算法将收敛至最优行为价值函数。
条件一:任何时候的策略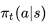
条件二:步长系数αt满足:
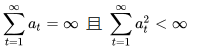
示例——有风格子世界
已知:如图所示,环境是一个10*7的长方形格子世界,同时有一个起始位置S和一个终止目标位置G,水平下方的数字表示对应的列中有一定强度的风,当该数字是1时,个体进入该列的某个格子时,会按图中箭头所示的方向自动移动一格,当数字为2时,表示顺风移动2格,以此类推模拟风的作用。任何试图离开格子世界的行为都会使得个体停留在移动前的位置。对于个体来说,它不清楚整个格子世界的构造,即它不知道格子是长方形的,也不知道边界在哪里。也不清楚起始位置、终止目标位置的具体为止。对于它来说,每一个格子就相当于一个封闭的房间,在没推开门离开当前房间之前它无法知道会进入哪个房间。个体具备记住曾经去过的格子的能力。格子可以执行的行为是朝上、下、左、右移动一步。
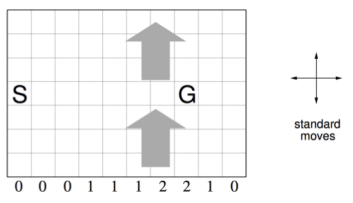
问题:个体如何才能找到最短从起始格子S到终止目标格子G的最短路线?
解答:首先将这个问题用强化学习常用的语言重新描述下。这是一个不基于模型的控制问题,即个体在不清楚模型机制条件下试图寻找最优策略的问题。在这个问题中,环境信息包括格子世界的形状是10*7的长方形;起始和终止格子的位置,可以用二维或一维的坐标描述,同时还包括个体在任何时候所在的格子位置。风的设置是环境动力学的一部分,它与长方形的边界共同及个体的行为共同决定了个体下一步的状态。个体从环境观测不到自身位置、起始位置以及终止位置信息的坐标描述,个体在与环境进行交互的过程中学习到自身及其它格子的位置关系。个体的行为空间是离散的四个方向。可以设置个体每行走一步获得即时奖励为-1,直到到达终止目标位置的即时奖励为0,借此希望找到最优策略。衰减系数λ可设为1。
其最优路线如下图所示:
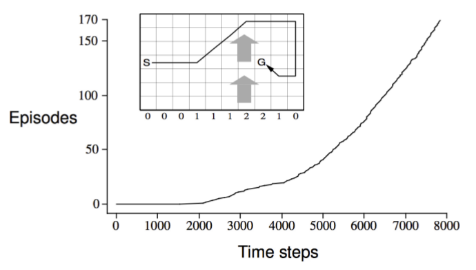
个体通过学习发现下面的行为序列(共15步)能够得到最大程度的奖励: -14
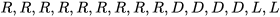
在个体找到这个最优行为序列的早期,由于个体对环境一无所知,SARSA算法需要尝试许多不同的行为,因此在一开始的2000多步里,个体只能完成少数几个完整的Episode,但随着个体找到一条链接起点到终点的路径,其快速优化策略的能力就显现的很明显了,因为它不需要走完一个Episode才能更新行为价值,而是每走一步就根据下一个状态能够得到的最好价值来更新当前状态的价值。
在实践环节,我们使用Python编写具体的SARSA代码。读者可以根据这些代码深入理解SARSA的核心思想。
n-步SARSA
在之前,我们学习了n-步收获,还记得定义吗?,这里类似的引出一个n-步Sarsa的概念。观察下面一些列的式子:
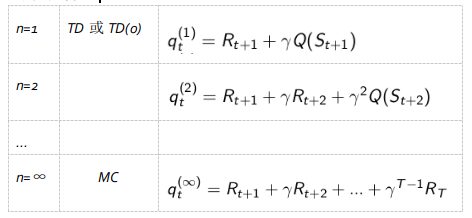

定义n-步Q收获(Q-return):
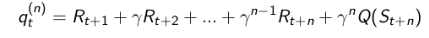
体会:个人感觉这个定义公式里没有体现出状态行为对的概念,理解起来容易与之前的n-步G收获混淆,其实Q本身是包含行为的,也就是在当前策略下基于某一个状态产生的行为。Q收获与G收获是有一定关系的,这可以结合第二章的Bellman方程来理解,这里不再赘述。
有了如上定义,可以把n-步Sarsa用n-步Q收获来表示,如下式
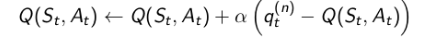
假如我们给n-步Q收获的每一个收获分配一个权重,如下图引入参数λ分配权重,并按权重对每一步Q收获求和,那么将得到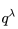
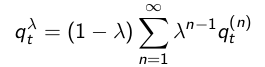
Sarsa(λ)前向认识:
如果用某一状态的
收获来更新状态行为对的Q值,那么可以表示称如下的形式:
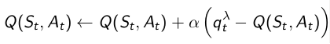
这就是前向认识Sarsa(λ),使用它更新Q价值需要遍历完整的Episode,我们同样可以反向理解Sarsa(λ).
Sarsa(λ)反向认识:
与上一讲对于TD(λ)的反向认识一样,引入效用追踪(Eligibility Trace)概念,不同的是这次的E值针对的不是一个状态,而是一个状态行为对:
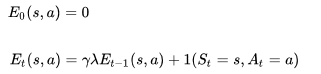
它体现的是一个结果与某一个状态行为对的因果关系,与得到结果最近的状态行为对,以及那些在此之前频繁发生的状态行为对对得到这个结果的影响最大。
下式是引入ET概念的SARSA(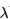
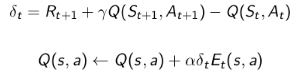
引入ET概念,同时使用SARSA(
具体的SARSA(

这里要提及一下的是E(s,a)在每浏览完一个Episode后需要重新置0,这体现了ET仅在一个Episode中发挥作用;其次要提及的是算法更新Q和E的时候针对的不是某个Episode里的Q或E,而是针对个体掌握的整个状态空间和行为空间产生的Q和E。算法为什么这么做,留给读者思考。
在实践环节,我们同样实现了该算法。
实际如果是基于查表的方式实现该算法,其速度明显比Sarsa要慢。毕竟带E的算法主要应用于在线更新。
下图则用了格子世界的例子具体解释了Sarsa和Sarsa(λ)算法区别:假定最左侧图描述的路线是个体采取两种算法中的一个得到的一个完整Episode的路径。为了下文更方便描述、解释两个算法之间的区别,先做几个合理的小约定:1)认定每一步的即时奖励为0,直到终点处即时奖励为1;2)根据算法,除了终点以外的任何状态行为对的Q值可以是任意的,但我们设定所有的Q值均为0;3)该路线是第一次找到终点的路线。
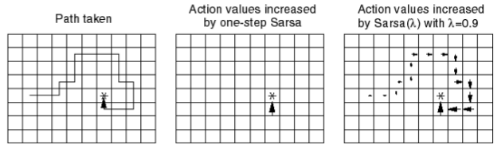
Sarsa(0)算法:
由于是现时策略学习,一开始个体对环境一无所知,即Q值均为0,它将随机选取移步行为。在到达终点前的每一个位置S,个体依据当前策略,产生一个移步行为,执行该行为,环境会将其放置到一个新位置S',同时给以即时奖励0,在新的位置S'上,根据当前的策略它会产生新位置下的一个行为,个体不执行该行为,仅仅在表中查找新状态下新行为的Q'值,由于Q=0,依据更新公式,它将把刚才离开的位置以及对应的行为的状态行为对价值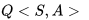
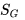
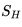
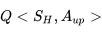
此时如果要求个体继续学习,则环境将其放入起点。个体的第二次寻路过程一开始与首次一样都是盲目随机的,直到其进入终点位置下方的位置
同样,经过第二次的寻路,个体了解到到达终点下方的位置
Sarsa(λ)算法:
该算法同时还针对每一次Episode维护一个关于状态行为对
,初始时E表值均为0。当个体首次在起点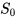
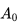
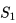
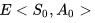
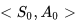
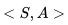
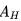
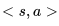
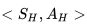
在图示的例子中没有显示某一状态行为频发的情况,如果个体在寻路的过程中绕过一些弯,多次到达同一个位置,并在该位置采取的相同的动作,最终个体到达终止状态时,就产生了多次发生的
当个体重新从起点第二次出发时,它会发现起点处向右走的价值不再是0。如果采用greedy策略更新,个体将根据上次经验得到的新策略直接选择右走,并且一直按照原路找到终点。如果采用Ɛ-greedy策略更新,那么个体还会尝试新的路线。
由于为了解释方便,做了一些约定,这会导致问题并不要求个体找到最短一条路径,如果需要找最短路径,需要在每一次状态转移时给个体一个负的奖励。
个人体会:Sarsa(λ)算法里在状态每发生一次变化后都对整个状态空间和行为空间的Q和E值进行更新,而事实上在每一个Episode里,只有个体经历过的状态行为对的E才可能不为0,为什么不仅仅对该Episode涉及到的状态行为对进行更新呢?理论上是可以仅对Episode里涉及的状态行为对的E和Q进行更新的,不过这要额外维护一个表,而往这个额外的表里添加新的状态行为对的E和Q值比更新总的状态行为空间要麻烦,特别是在早期个体没有一个较好的策略的时候需要花费很长很长时间才能找到终点位置,这在一定程度上反而没有更新状态空间省时。不过随着学习深入、策略得到优化,此表的规模会变小。
离线策略学习 Off-Policy Learning
现时策略学习的特点就是当前遵循的策略就是个体学习改善的策略。离线策略学习(Off-Policy Learning)则指的是在遵循一个策略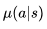
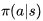
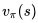
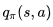
。为什么要这么做呢?因为这样可以较容易的从人类经验或其他个体的经验中学习,也可以从一些旧的策略中学习,可以比较两个策略的优劣。其中可能也是最主要的原因就是遵循一个探索式策略的基础上优化现有的策略。同样根据是否经历完整的Episode可以将其分为基于蒙特卡洛的和基于TD的。基于蒙特卡洛的离线策略学习仅有理论上的研究价值,在实际中毫无用处。在解释这一结论时引入了“重要性采样(importance sampling)”这个概念,这里就不详述了,有兴趣的读者可以参考原讲义。这里主要讲解常用的TD下的离线策略学习。
离线策略TD学习
离线策略TD学习的任务就是使用TD方法在遵循一个策略
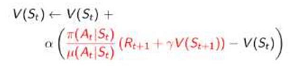
这个公式可以这样解释:个体处在状态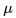
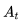
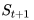
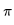
应用这种思想最好的方法是基于TD(0)的Q-学习(Q-learning)。它的要点在于,更新一个状态行为对的Q价值时,采用的不是当前遵循策略的下一个状态行为对的Q价值,而是采用的待评估策略产生的下一个状态行为对的Q价值。公式如下:
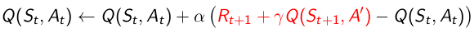

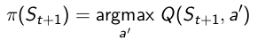
注:原讲义中的w.r.t是 with respect to的缩写,表示”在...基础上“。
这样Q学习的TD目标值可以被大幅简化:
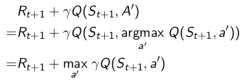
这样在状态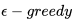
定理:Q学习控制将收敛至最优状态行为价值函数: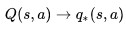
下图是Q学习具体的更新公式和图解:
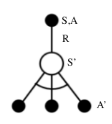
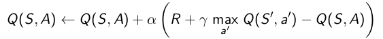
下图是Q学习的算法流程:

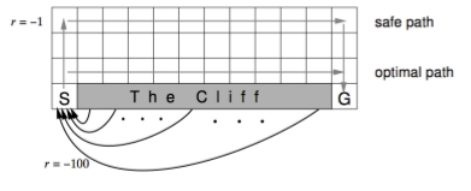
示例——悬崖行走
因为时间关系这个例子视频里没有讲解,这个例子也比较简单,可以用格子世界来模拟,图中悬崖用灰色的长方形表示,在其两端一个是起点,一个是目标终点。途中从悬崖指向起点的箭头提示悬崖同时也是终止状态。可以看出最优路线是贴着悬崖上方行走。
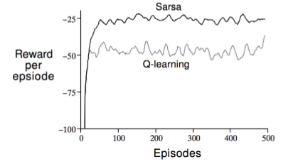
个人体会 该例体现出早期Q学习得到的策略要比SARSA要差一些,但后期最终总能找到最优策略。两者的曲线都有一定的起伏,说明两者都有一定的探索,即遵循的策略都是
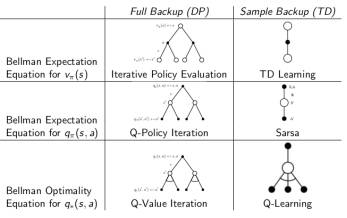
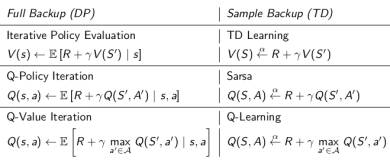
总结DP与TD关系
下面两张图概括了各种DP算法和各种TD算法,同时也揭示了各种不同算法之间的区别和联系。总的来说TD是采样+有数据引导(bootstrap),DP是全宽度+实际数据。如果从Bellman期望方程角度看:聚焦于状态本身价值的是迭代法策略评估(DP)和TD学习,聚焦于状态行为对价值函数的则是Q-策略迭代(DP)和SARSA;如果从针对状态行为价值函数的Bellman优化方程角度看,则是Q-价值迭代(DP)和Q学习。
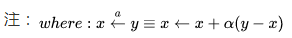
至此,David Silver强化学习公开课的第一部分就讲完了,第二部分将聚焦于各种价值函数、策略函数的近似表示;个体如何通过训练得到一个模型,并结合模型进行强化学习;如何从理论角度看平衡探索与利用这对矛盾;并最终结合经典游戏谈强化学习的实际应用。第二部分的内容虽然不像第一部分的这些内容之间联系比较紧密,但结合了不少深度学习的知识和宏观层次的模型架构,涉及到模型训练时参数的选择和调优,还是有相当难度的。在此之前读者们最好能动手实践基础部分的强化学习理论,我也将陆续贴出针对第一部分课程中提到的格子世界的代码和相关解释。敬请期待。
敬请关注专知公众号(扫一扫最下方二维码或者最上方专知蓝字关注),以及专知网站www.zhuanzhi.ai, 第一时间得到的《强化学习》第六讲 价值函数的近似表示!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!