CVPR 2020 Oral丨基于范例的精细可控图像翻译CoCosNet,一键生成你心目中的图像
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
编者按:图像翻译是近年来的研究热点,类比于自然语言翻译,它将输入图像的表达转化为另一种表达,在图像创作、图像风格化、图像修复、域自适应学习等领域有着广泛应用。然而现有技术通常仅能产生合理的目标域图像,其具体风格并不可控。为此,本文提出基于范例的图像翻译技术 CoCosNet,建立原域图与目标域范例图像的密集对应,使生成图片精细匹配范例图片风格。
CoCosNet 方法在一系列任务(语义分割->自然图像、轮廓->人脸图片、关键点->姿态图片)中,生成质量大幅领先现有方法,且图像风格精细可控。此外,我们利用弱监督学习得到跨域图片之间的集对应,实现如图像编辑、人像批量上妆等有趣应用。这项成果发表于 CVPR 2020 oral 论文“Cross-domain Correspondence Learning for Exemplar-based Image Translation”。
只需寥寥数笔,图像翻译助你成为神笔马良。作为生成对抗模型的研究分支,图像翻译(image translation)技术近年来取得了一系列突破。它将图片从一种域(domain)的表达形式转换为另一种表达,而域可以定义得很广泛:如将域按照性别划分,那么网络将学习人像性别转换;如域表征为不同画风,那么网络将学到毕加索到莫奈的创作风格迁移;当域定义为草图或风景图,网络则从草图生成风光大片。简而言之,图像翻译技术需要两个域的图片作为训练数据,域内的图片共享相同的属性,而域间有着共同的属性区别,网络则学习两种数据分布之间的映射。我们甚至可以用这项神奇的技术,将人像中戴有的 N95 口罩一键去除,生成靓丽自拍,一扫疫情带来的心情阴霾。
图像翻译技术可谓百花齐放,而它的发展也沿着一条清晰的脉络。CVPR 2017 上首先提出的 Pix2Pix 需要配对监督,之后的无监督图像翻译工作 CycleGAN 大大拓展了应用范围;针对它们仅能生成单张目标域结果的问题,随后的 BiCycleGAN、UNIT/MUNIT、DRIT 等工作进一步支持多模态(multi-modal)图像的生成。此后,图像翻译朝着更高分辨率(Pix2PixHD),更高质量(GauGAN),视频(Vid2Vid),小样本适应(FUNIT)等方向扩展 [1]。
然而,两个问题依旧有待解决:1)尽管最近的工作支持多模态图像生成,但其结果是从隐空间中采样得到的生成结果,生成图风格不可预知,用户无法指定具体实例的样式(如红色的法拉利、橘红的天空);2)现有方法的图片往往有较明显的瑕疵,影响用户体验。
技术路线
我们认为基于范例(exemplar-based)的技术路线能较好地解决上述问题。具体地,网络接受输入域图片的同时,接受一张目标域的范例图片,该范例图片与输入图有相似的语义且具有用户期望的目标风格。网络同时以输入图和范例图做条件(condition),学习输出符合指定风格的图片。值得注意的是,一些先前工作也支持范例输入,但这些方法将范例图片编码为一维风格编码(如长度为512维的向量),但我们认为这样的一维编码不足以刻画细致的实例风格,因而这些方法仅能大致地影响整体图片风格。
因此,我们提出建立两个域图片(输入图及范例图)之间的密集语义对应(dense correspondence),进而依赖这样的对应,定位输入图在范例中相应位置的颜色、纹理信息,使得生成图片风格精细匹配范例中相同语义的物体(例如,草图的生成结果中,眼睛应该采用范例中的人眼细节)。同时,这样的方法也有助于降低网络学习难度、提高输出图片质量——这是因为网络可以更多地参考范例图中的细节,而无需预测物体的纹理细节。
于是,我们的生成任务归结于,如何精准地找到输入及范例之间的语义对应。这里有两大挑战:一是输入图和范例来自不同的域,它们的图像块(image patch)有着巨大的图片域差异(domain gap),因而我们无法用某种预先定义的距离指标(如颜色的欧氏距离)直接对应两类图片的图像块;另一方面,我们很难取得这样的标注信息,即不同域图片之间的语义对应,来作为网络训练的监督信息。如图1,建立自然人脸与油画人像之间的密集对应,事实上是困难的,而这样的跨域语义对应(cross-domain semantic correspondence)问题也是首次被提出。
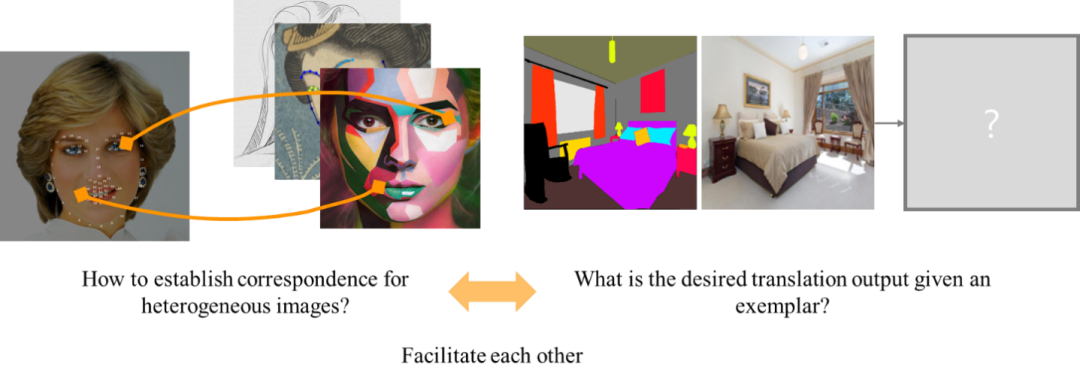
图1:左,建立跨域图片的语义对应。右,图像生成
那么如何解决跨域语义对应,并利用好对应关系实现图像生成呢?我们注意到,两个任务有着相辅相成的联系(图1):正确的语义对应,有助于指示网络参考范例的颜色及纹理,从而提高最终图像质量;反之,如果网络包含跨域对应的子模块,那么生成高质量图片的目标会反过来要求子模块找到合理的对应。基于这个想法,我们提出CoCosNet(CrOss-domain COrreSpondence network for image translation) 联合训练跨域对应和图像生成,其中跨域对应通过弱监督学习(weakly supervised learning)的方式得以建立。如图2所示,我们的方法精确匹配用户给定的范例风格的同时,大幅提升了图像质量。在复杂数据集 ADE20k 上,FID(Fréchet inception distance)由此前的33.9降低至26.4。

图2:CoCosNet 生成图。我们在三个任务上进行了实验,在语义分割蒙版->场景图像(1-2行)、轮廓->人脸图片(3-4行)、骨骼关键点->姿态图片(5-6行),均取得了迄今为止最高的生成质量。
具体方法
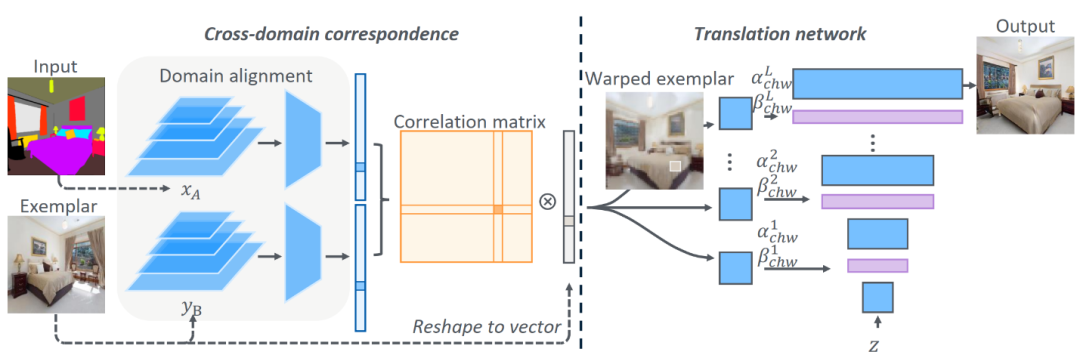
图3:CoCosNet 网络框架
我们提出的 CoCosNet 框架如图3所示。原域 A 中的输入图表示为 x_A,目标域 B 中的范例图表示为 y_B,我们希望网络学习得到输入图在 B 域中的对应 x_B=G(x_A, y_B)。
整个网络由两个子网络构成。第一部分为跨域对应(cross-domain correspondence)子网络,其用于找到输入 x_A 与范例 y_B 之间的密集对应。然而,与一般的语义对应方法(如 SFNet [2])不同的是,这两种输入来自于不同的域——如图3中 x_A 是语义分割,y_B 是一张自然室内场景,而我们无法用预先训练的分类特征提取器(如 pretrained VGG/ResNet)来提取两种输入的特征。于是,我们想到利用训练集中 x_A 和它在目标域的配对 x_B,来训练两个域的特征提取器 (F_(A→B) 和 F_(B→A)),使得他们提取到的特征可以适应到一个对齐的隐空间,我们定义域自适应损失函数为:
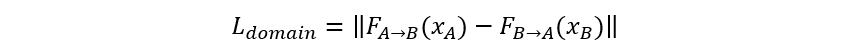
当输入 x_A 与 y_B 时,我们有理由相信,他们同样被适应到共有空间中,该空间保留了两张图片的语义特征。我们可以在这个特征空间中算两张图两两位置间的相似度矩阵 M,其中矩阵元素 M(u,v) 表示 x_A(u) 与 y_B(v) 之间的语义相似性。这个相似度矩阵也可以理解为注意力机制,因而 x_A 的对应点实际上是 y_B 中每个点的加权和,其权重取决于他们之间的语义相似度。因此,如果学习得当,我们将得到变形的 y_B(记为 r_(y→x),也就是图3中的 warped exemplar),该图与输入 x_A 语义对齐。这里,我们引入一个对应关系正则项,要求 r_(y→x) 经过反向形变后可以重建范例图片:
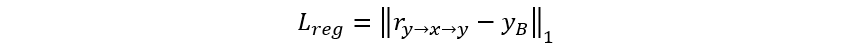
网络的第二部分为图像转换子网络(translation network)。这个网络尝试从输入 x_A 和与它对齐的范例 r_(y→x) 生成最终图像。这里我们采用改进的空间自适应去正则化层(spatially-variant denormalization layer)[3]:利用简单变换将 x_A 和 r_(y→x) 映射为正则化层的调制系数,通过调制正则化层来实现对生成图片的风格调制。这也类似于 StyleGAN [4]利用条件正则化层(BN)来改变生成风格,而我们做法区别在于,条件输入 x_A 和 r_(y→x) 为二维图像,正则化统计量(μ_(h,w),σ_(h,w))、去正则化系数(α_(h,w),β_(h,w))都是空间自适应的:
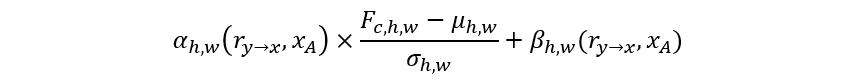
空间自适应在我们的任务中非常重要,它有助于将范例图像中的风格精细迁移到最终生成图片中,且通过反传,前面的跨域对应子模块能学到精细的语义对应。
为了学到正确的对应关系,我们对输出图像施加以下约束。1)特征匹配损失(perceptual loss):输出图像必须符合输入图片的语义约束,因此,我们要求它们经过预训练 VGG19 后的高层特征——Relu4-2层——应保持一致;2)上下文损失(contextual loss)[5]:输出图像应和范例图的对应物体风格相一致,为此我们在 VGG19 的低层特征图(Relu2-1, …. Relu5-2,更多的包含颜色,纹理信息)上匹配二者的统计分布。3) 对抗损失函数(adversarial loss):我们联合训练判别器 D,使得最终的输出图片难以与真实图片区分开来;4)特征匹配(feature matching):我们将 x_B 做形变增强,构造为 x_A 的伪范例,这样的伪范例对(pseudo exemplar pair)的输出应能完美重建 x_B,这里我们采用 VGG 特征匹配损失函数。
综上,总的训练目标为:
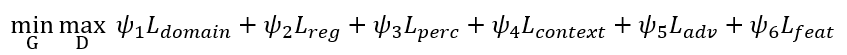
实验结果
我们在 ADE20k、CelebA-HQ 以及 Deepfashion 数据集上进行了验证,这三个数据集的任务分别为:语义分割->自然图像、轮廓->人脸图片、骨骼关键点->姿态图片。我们和之前的最好方法进行了多方面比较,首先是定性比较结果:

图4:不同方法的定性比较结果
如图4,对于最后一列表征所用到的范例图片,我们的结果(倒数第二列)相较之前方法取得明显的质量提升,且生成风格精细匹配范例图片。定量结果也进一步验证了我们的优势:如表1所示,我们的方法在三个任务中 FID 及 SWD 两个指标均显著降低。
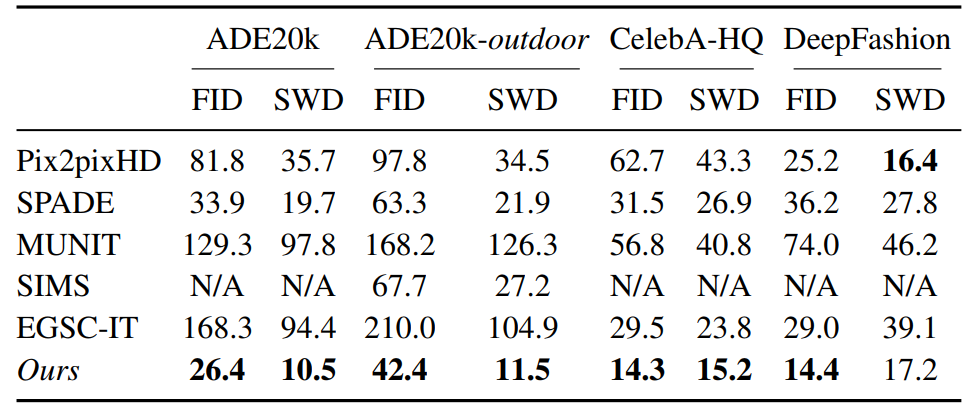
表1:图片质量的定量比较。我们采用 FID 和 SWD 两种指标,在不同任务中均取得明显优势
更多的定量比较请详见我们的论文。这里我们展示更多的结果(图5-7)。
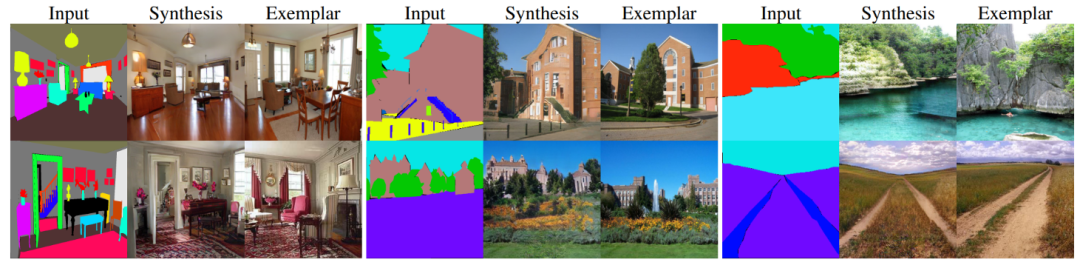
图5: 复杂数据集 ADE20k 上语义分割->自然场景的图像翻译结果

图6:CelebA-HQ 数据集上人脸轮廓->人像图像翻译结果

图7:Deepfashion 数据集上姿态关键点->人体姿态图片的图像翻译结果
我们的方法首次建立了跨域图片的密集对应关系,而这种对应关系完全通过弱监督学习得到。在图8中,我们手工选择了若干关键点,他们均在自然图片中找到了准确的对应。

图8:我们的方法利用与图像生成联合训练的方法,在弱监督训练下建立了稳定的跨域对应关系
更多应用与 Demo
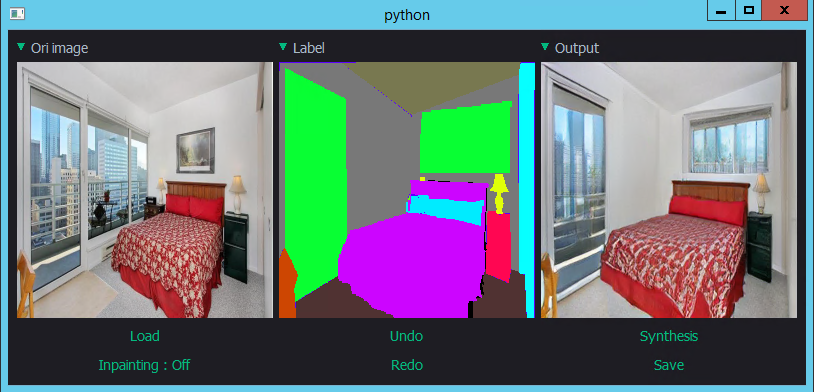
图9:图像编辑。用户可以简单地通过修改语义分割图(中),实现对输入图片(左)的增删改(输出结果为右图)
这一方法还可以用于人像批量上妆。用户可以选择在给定的一张人像用 PS 上妆,这个上妆过程往往是笔刷涂抹,利用人像之间的对应关系,我们可以批量将笔刷应用到其他人像上。下图中我们为一批图片加上烟熏妆。第一列为手工 PS,后面几列均为算法迁移结果。鉴于程序员审美与 PS 技术有限,相信专业人士能用我们的算法得到更出众的结果。

图10:我们的算法将用户上妆的 PS 笔刷一键迁移到其他人像
最后,受到之前工作的启发,我们从 Flicker 上获取了5万张风景图片作为训练数据,让用户能够通过手工描画语义分割一键生成风景大片。与之前的工作相比,我们生成的质量更高,且允许用户通过选择范例图来指定风景照风格。下图是我们得算法生成的风景大片。

图11:算法可以按照用户手绘的语义构图生成风景图
结语
本文介绍了基于范例的精细可控图像翻译,CoCosNet 方法在多个任务上大幅提高现有图像翻译的生成质量,且具有风格可控的特性。我们注意到,近期的 StarGAN v2 [6] 同样支持基于范例的图像翻译。与其相比,我们相信显性地建立跨域对应有助于提高生成质量,之后也会进行更详细地对比。下一步,我们会将 CoCosNet 方法拓展至更高清图片生成领域。
代码即将开源,更多的算法细节请见论文。
论文原文: Cross-domain Correspondence Learning for Exemplar-based Image Translation
论文链接:https://arxiv.org/abs/2004.05571
项目网址: https://panzhang0212.github.io/CoCosNet/
参考文献
[1] Wu, Xian, et al. "A survey of image synthesis and editing with generative adversarial networks." Tsinghua Science and Technology 22.6 (2017): 660-674.
[2] Lee, Junghyup, et al. "SFNet: Learning object-aware semantic correspondence." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[3] Park, Taesung, et al. "Semantic image synthesis with spatially-adaptive normalization." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[4] Karras, Tero, et al. "A style-based generator architecture for generative adversarial networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[5] Mechrez, et al. "The contextual loss for image transformation with non-aligned data." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[6] Choi, Yunjey, et al. "StarGAN v2: Diverse Image Synthesis for Multiple Domains." arXiv preprint arXiv:1912.01865 (2019).
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




