NeurIPS 2019 | 一种对噪音标注鲁棒的基于信息论的损失函数

AI科技评论获授权转载自北京大学前沿计算研究中心
本文是第三十三届神经信息处理系统大会(NeurIPS 2019)入选论文《L_DMI:一种对噪音标注鲁棒的基于信息论的损失函数(L_DMI: A Novel Information-theoretic Loss Function for Training Deep Nets Robust to Label Noise)》的解读。该论文由北京大学前沿计算研究中心助理教授孔雨晴博士和北京大学数字视频编解码技术国家工程实验室教授、前沿计算研究中心副主任王亦洲共同指导,由2016级图灵班本科生许逸伦、曹芃(共同一作)合作完成。

Arxiv link: https://arxiv.org/abs/1909.03388
Code link: https://github.com/Newbeeer/L_DMI
简介
噪音标注(noisy label)是机器学习领域的一个热门话题,这是因为标注大规模的数据集往往费时费力,尽管在众包平台上获取数据更加快捷,但是获得的标注往往是有噪音的,直接在这样的数据集上训练会损害模型的性能。许多之前处理噪音标注的工作仅仅对特定的噪音模式(noise pattern)鲁棒,或者需要额外的先验信息,比如需要事先对噪音转移矩阵(noise transition matrix)有较好的估计。我们提出了一种新的损失函数,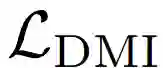
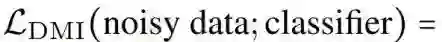
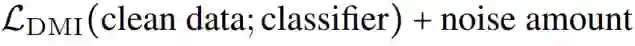
这意味着,理论上,用
之前,人们使用的损失函数仅仅对特定的噪音模式鲁棒。原因之一,是它们往往都是基于距离的(distance-based),比如 cross entropy loss,0-1 loss,MAE loss 等等,也就是说,这些损失函数定义的是分类器的输出和标签之间的一种距离。因此,如果标注者对某一分类具有很强的倾向,比如一个能力较低的标注者在标注医疗数据时,因为他知道大部分数据是良性的,所以他把所有良性的数据都标成了良性的,并且把90%的恶性的数据也标成了良性的。这样,我们收集到的标签就极其倾斜于良性这个分类,也就是有了对角线不主导(diagonally non-dominant)的噪音模式。在这种情况下,如果使用基于距离的损失函数,那么一个把所有数据都分类到良性的分类器就会比一个把所有数据都分类到真实标签的分类器有更小的损失函数值。
而不同于那些基于距离的损失函数,我们使用的是基于信息论的损失函数(information-theoretic loss function),即我们希望输出和标签之间有最高的互信息的分类器具有最低的损失函数值。这样,那个把所有数据都分类到良性的分类器由于和标签的互信息为零,就会有很高的损失函数值而被淘汰。但仅这一点是不够的,实际上我们希望的是找到一个信息测度 I,满足下列性质:
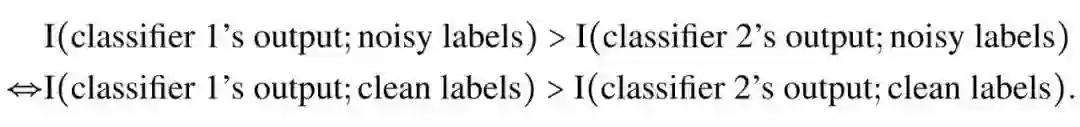
也就是说,这个信息测度在噪音标注(noisy label)上对分类器的序应该与其在正确标注(clean label)上对分类器的序相同。然而,香农的互信息不满足以上性质。
本文方法
我们使用了基于两个离散随机变量的联合分布矩阵的行列式的互信息 DMI[1]。它不仅保留有香农互信息的一些性质,还能够满足我们需要的上述性质。它的正式定义为:
定义:(基于行列式的互信息)给定两个离散随机变量 W1,W2,我们定义 W1,W2 间基于行列式的互信息(Determinant based mutual information)如下:
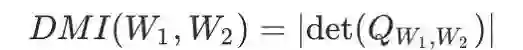
其中,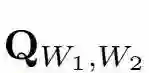
即 DMI 可以看成是两个取值范围相同的离散随机变量的联合分布矩阵的行列式的绝对值。
DMI 之所以满足上述性质,是因为如下定理[1]:
定理(DMI 的性质):DMI 非负,对称并且满足信息单调性。此外,它满足相对不变性:对于任意的随机变量 W1,W2,W3,当 W3 与 W2 关于 W1 条件独立,那么有:
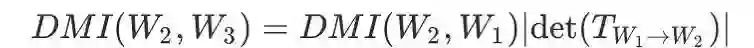
其中,
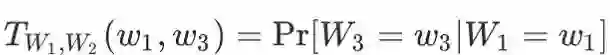
由于实际中变化的只有分类器的输出 W2, 因此矩阵 T 是固定的。DMI 的这种代数结构使得我们能够在噪声信道 (T) 固定的情况下,分别衡量分类器输出 W2 与信道输入 W1、信道输出 W3 的 DMI。由于 T 固定,因此 DMI 自然满足上文提到的分类器的序的性质。我们在论文的主定理中证明了这个代数结构使得 DMI 所对应的损失函数能够对噪声鲁棒。
基于 DMI,我们定义了的一种易于优化 DMI 的损失函数
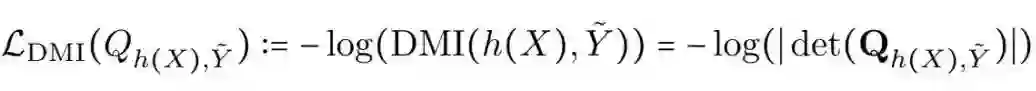
其中,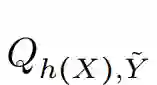

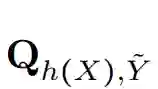
即分类器的输出 h(X) 与噪音标注
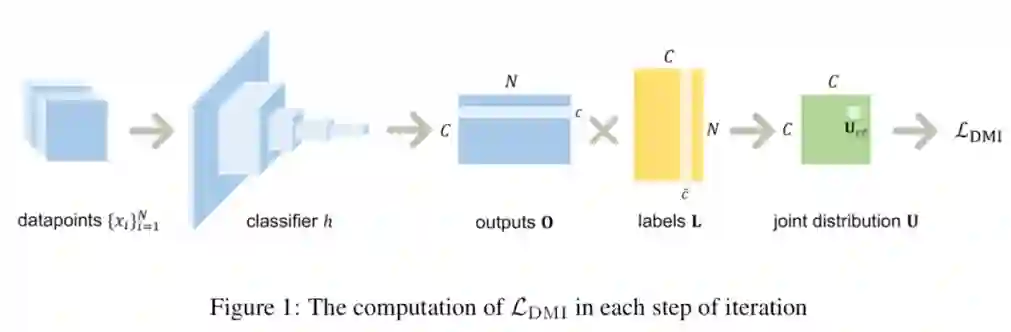
在数据 X 和噪音标注
实验结果
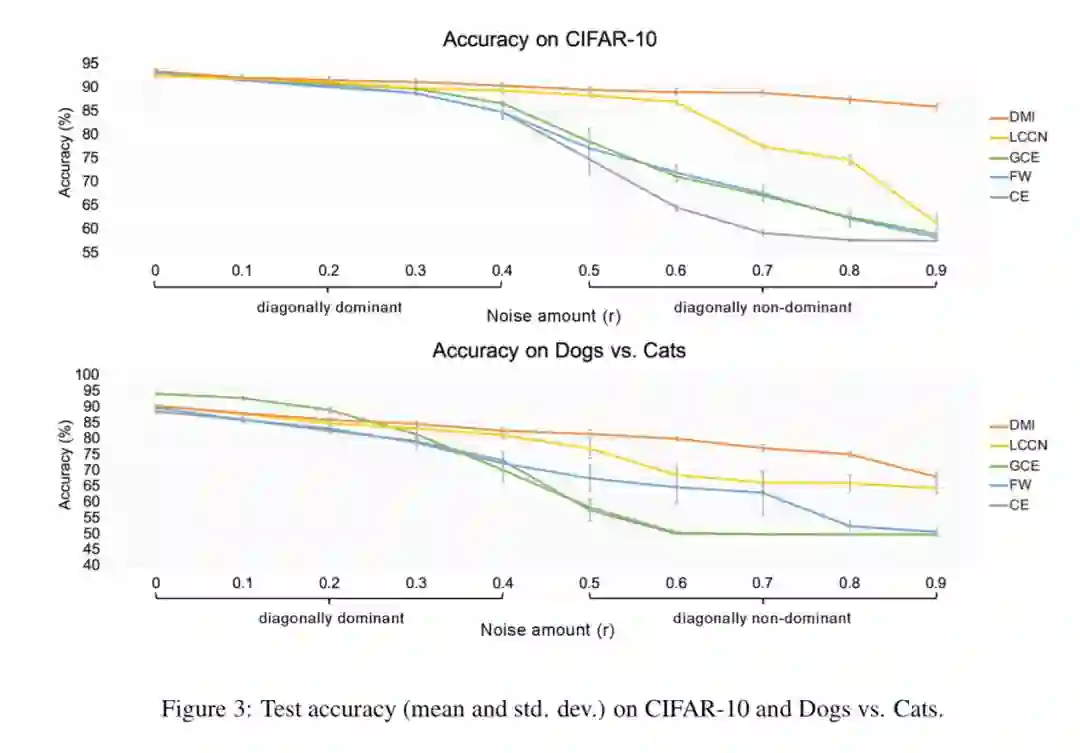
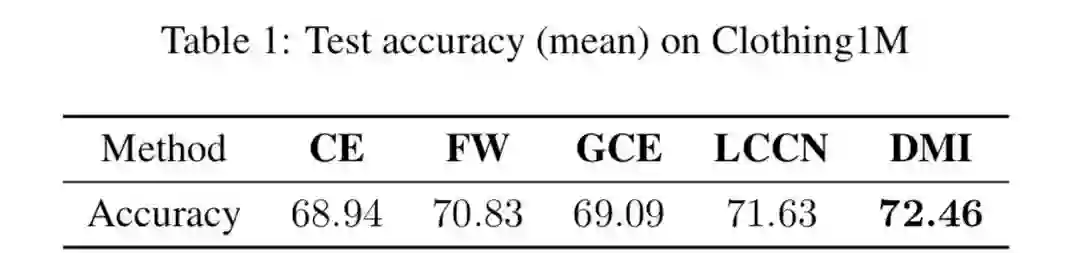
我们的方法在人工合成的数据集上和真实的数据集(Clothing 1M)上都取得了 state-of-the-art 的结果,并且在对角线不主导(diagonally non-dominant)的噪声模式(noise pattern)中优势明显。

Reference:
[1] Y. Kong, "Dominantly Truthful Multi-task Peer Prediction with a Constant Number of Tasks," to appear in SODA, 2020.






