本文对华中科大、阿里巴巴合作完成的、发表在AAAI 2020的论文《All You Need Is Boundary: Toward Arbitrary-Shaped Text Spotting》进行解读。
论文链接:https://arxiv.org/pdf/1911.09550.pdf
该论文提出了用边界点来表示任意形状文本的方法,解决了自然场景图像中任意形状文本的端到端识别问题。如图1所示:
现有方法用外接四边形框来表示文本边界(图1,(a)),通过RoI-Align来提取四边形内的特征(图1,(b)),这样会提取出大量的背景噪声,影响识别网络。利用边界点来表示任意形状文本有以下优势:
-
边界点能够描述精准的文本形状,消除背景噪声所带来的影响(图1,(c));
-
通过边界点,可以将任意形状的文本矫正为水平文本,有利于识别网络(图1,(d));
-
由于边界点的表示方法,识别分支通过反向传播来进一步优化边界点的检测。
文本检测和识别常作为两个独立的子任务进行研究,但事实上,两者是相互关联并且能相互促进的。
近期的一些工作开始关注到文本端到端识别问题,并取的了显著的进展。面对不规则的文本,这些方法多采用分割的方式对文字区域进行描述。分割的方法常需要复杂的后处理,并且获取的文本框和识别分支之间并不可导,识别分支的文本语义信息无法通过反向传播来对文本框进行优化。
同时一些方法使用字符分割的方法进行识别,这使得识别器失去序列建模能力,并且需要额外的字符标注,增加了识别的训练难度以及标注成本。
虽然边界点的预测理论上可以直接从水平候选框中预测(如图3(d)所示),但是自然场景中的文本呈现各种不同的形状、角度以及仿射变换等,这使得直接从水平候选框中预测边界点变得十分困难,不具有稳定性。
因此,我们在文本实例的最小外接四边形上预测边界点,这样可以将不同角度、形状的文本旋转为水平形状,在对齐后的文本实例上预测边界点对于网络更为高效,容易。
本文的方法的包含三个部分:多方向矩形包围框检测器(the Oriented Rectangular Box Detector),边界点检测器(the Boundary Point Detection Network),以及识别网络(the Recognition Network)。对于多方向矩形包围框检测器,该文首先使用RPN网络进行候选区提取。
为了产生多方向的矩形框,在提取出的候选区对目标矩形框的中心偏移量、宽度、高度和倾斜角度进行回归。获取了矩形包围框后,利用矩形框进行特征提取,并在提取的的候选区中进行文字边界点的回归。得到预测的边界点后,对文本区域的特征进行矫正,并将矫正的特征输入到后续的识别器中。
对于边界点检测网络,如图3(c)所示,该方法根据默认锚点(设定的参考点)进行回归,这些锚点被均匀的放置在最小矩形包围框的两个长边上,同时从文本实例的每个长边上等距采样K个点作为文字的目标边界点。本文采用预测相对偏移量的方式来获取边界点的坐标,即预测一个的向量(个边界点)。对于边界点
![]() 可从预测的偏移量获取,
可从预测的偏移量获取,
![]() ,其中
,其中
![]() 代表定义的描点。
对于识别网络,识别器使用矫正的特征预测出字符序列。首先,编码器将矫正的特征编码为特征序列
代表定义的描点。
对于识别网络,识别器使用矫正的特征预测出字符序列。首先,编码器将矫正的特征编码为特征序列
![]() 。 然后基于注意力的解码器将F转化为字符序列
。 然后基于注意力的解码器将F转化为字符序列
![]() , 其中T是序列长度。当为第t时,解码器通过隐藏层状态
, 其中T是序列长度。当为第t时,解码器通过隐藏层状态
![]() 和上一步的结果
和上一步的结果
![]() 预测当前步的结果。
本文的方法采用完全端到端的训练方式,网络的损失函数包含四个部分,
预测当前步的结果。
本文的方法采用完全端到端的训练方式,网络的损失函数包含四个部分,
![]() , 其中
, 其中
![]() 为RPN的损失,
为RPN的损失,
![]() 为多方向矩形框回归的损失值,
为多方向矩形框回归的损失值,
![]() 为边界点回归的损失值,
为边界点回归的损失值,
![]() 为识别网络的损失。
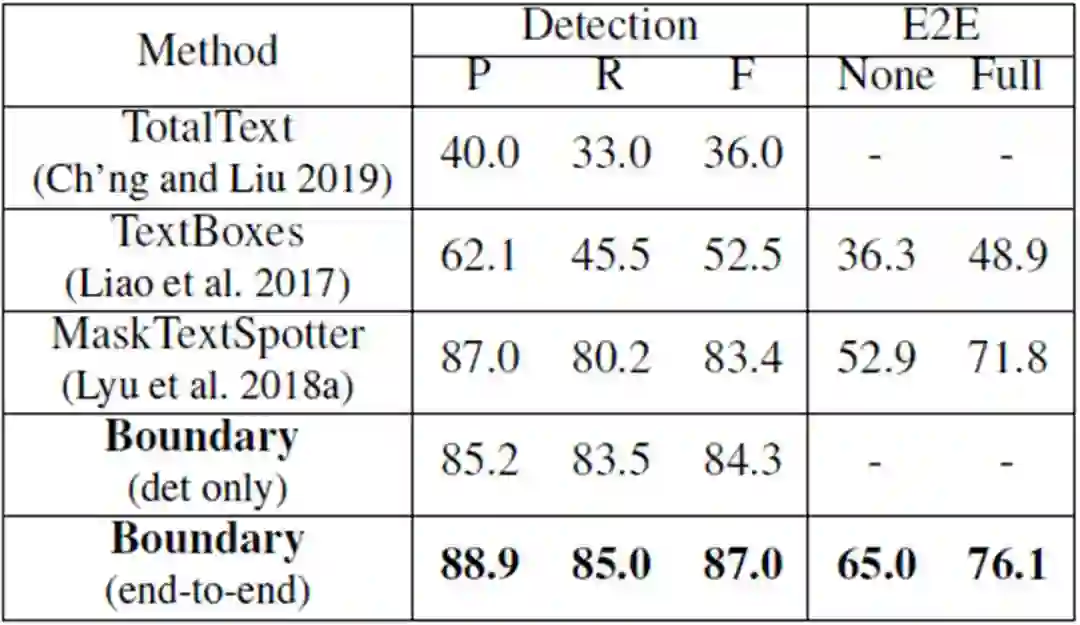
表 1:在全部文本上的结果。“ P”,“ R”和“ F”分别表示精度,召回率和F量度检测任务。“ E2E”表示端到端,“ None”表示没有任何词典的识别,“ Full”词典包含测试集中的所有单词。
文中的方法在曲形数据集上取得了优异的性能,大幅领先先前方法。总结来看,性能的提升主要来源于三点:
1) 相对于基于分割的方法MaskTextSpotter, 本文的识别器采用基于注意力的解码器,能够捕获字符之间的语义关系,而MaskTextSpotter独立地预测每个字符;
2) 相对于其他方法,本文使用边界点对文本区域的特征进行矫正,识别器拥有更好的特征;
3) 得益于更好的识别结果,由于检测和识别共享特征,检测的结果受特征影响得到进一步提升。
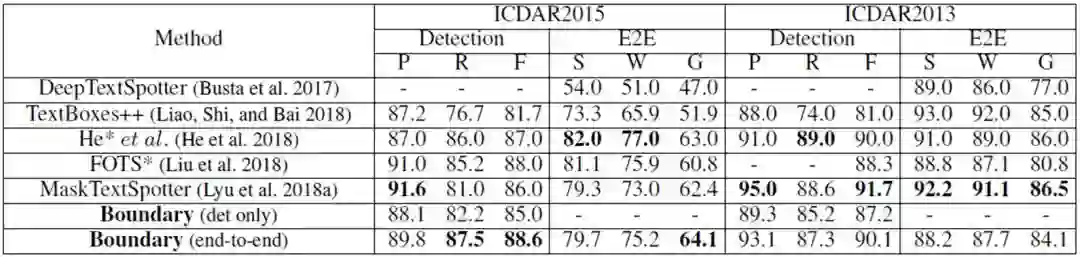
表2、ICDAR2015 和 ICDAR2013(DetEval)的结果。“ S”,“ W”和“ G”分别表示使用强,弱和通用词典进行识别。*表示使用MLT2017的训练数据集进行训练。
文中的方法在ICDAR15多方向数据集上取得较好的结果,得益于序列识别器,在只使用通用字典的情况下高于先前的结果。在ICDAR13水平数据集上,本文的方法未使用字符标注,也取得较好的结果。
图4:在Total-Text、ICDAR2015和ICDAR2013上的文本发现结果示例。
图4 展示了一些可视化的结果图。该方法能处理任意形状的文本,并且能很好地处理垂直文本,能够正确获取竖直文本的阅读顺序。
本文提出了一个以边界点表示任意形状文本的端到端网络,实验证明了此种方法在端到端识别任务上的有效性和优越性。检测任务和识别任务均能从边界点这种表示形式中受益:
1)由于边界点的表示是可导的,因此识别分支的导数回传会进一步优化检测结果;
2)使用边界点对不规则文本的特征进行矫正能移除背景干扰,可以提升识别性能。
为识别网络的损失。
表 1:在全部文本上的结果。“ P”,“ R”和“ F”分别表示精度,召回率和F量度检测任务。“ E2E”表示端到端,“ None”表示没有任何词典的识别,“ Full”词典包含测试集中的所有单词。
文中的方法在曲形数据集上取得了优异的性能,大幅领先先前方法。总结来看,性能的提升主要来源于三点:
1) 相对于基于分割的方法MaskTextSpotter, 本文的识别器采用基于注意力的解码器,能够捕获字符之间的语义关系,而MaskTextSpotter独立地预测每个字符;
2) 相对于其他方法,本文使用边界点对文本区域的特征进行矫正,识别器拥有更好的特征;
3) 得益于更好的识别结果,由于检测和识别共享特征,检测的结果受特征影响得到进一步提升。
表2、ICDAR2015 和 ICDAR2013(DetEval)的结果。“ S”,“ W”和“ G”分别表示使用强,弱和通用词典进行识别。*表示使用MLT2017的训练数据集进行训练。
文中的方法在ICDAR15多方向数据集上取得较好的结果,得益于序列识别器,在只使用通用字典的情况下高于先前的结果。在ICDAR13水平数据集上,本文的方法未使用字符标注,也取得较好的结果。
图4:在Total-Text、ICDAR2015和ICDAR2013上的文本发现结果示例。
图4 展示了一些可视化的结果图。该方法能处理任意形状的文本,并且能很好地处理垂直文本,能够正确获取竖直文本的阅读顺序。
本文提出了一个以边界点表示任意形状文本的端到端网络,实验证明了此种方法在端到端识别任务上的有效性和优越性。检测任务和识别任务均能从边界点这种表示形式中受益:
1)由于边界点的表示是可导的,因此识别分支的导数回传会进一步优化检测结果;
2)使用边界点对不规则文本的特征进行矫正能移除背景干扰,可以提升识别性能。
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
![]()
![]()
招 聘
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiawei@leiphone.com
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页




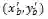 可从预测的偏移量获取,
可从预测的偏移量获取,
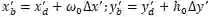 ,其中
,其中
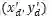 代表定义的描点。
代表定义的描点。
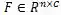 。 然后基于注意力的解码器将F转化为字符序列
。 然后基于注意力的解码器将F转化为字符序列
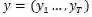 , 其中T是序列长度。当为第t时,解码器通过隐藏层状态
, 其中T是序列长度。当为第t时,解码器通过隐藏层状态
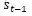 和上一步的结果
和上一步的结果
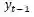 预测当前步的结果。
预测当前步的结果。
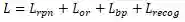 , 其中
, 其中
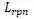 为RPN的损失,
为RPN的损失,
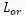 为多方向矩形框回归的损失值,
为多方向矩形框回归的损失值,
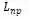 为边界点回归的损失值,
为边界点回归的损失值,
 为识别网络的损失。
为识别网络的损失。