AAAI 2020学术会议提前看:常识知识与常识推理
人工智能顶级会议 AAAI 2020 将于 2 月 7 日-2 月 12 日在美国纽约举办,AAAI 2020 最终收到 8800 篇提交论文,评审了 7737 篇,接收了 1591 篇,接收率 20.6%。
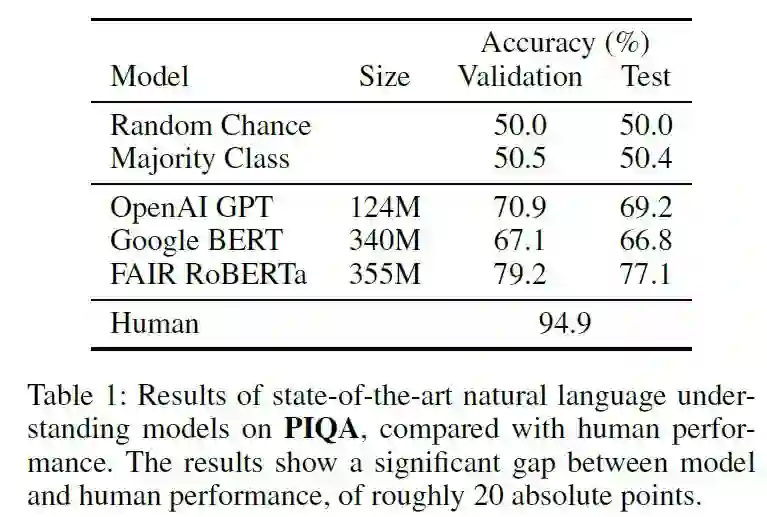
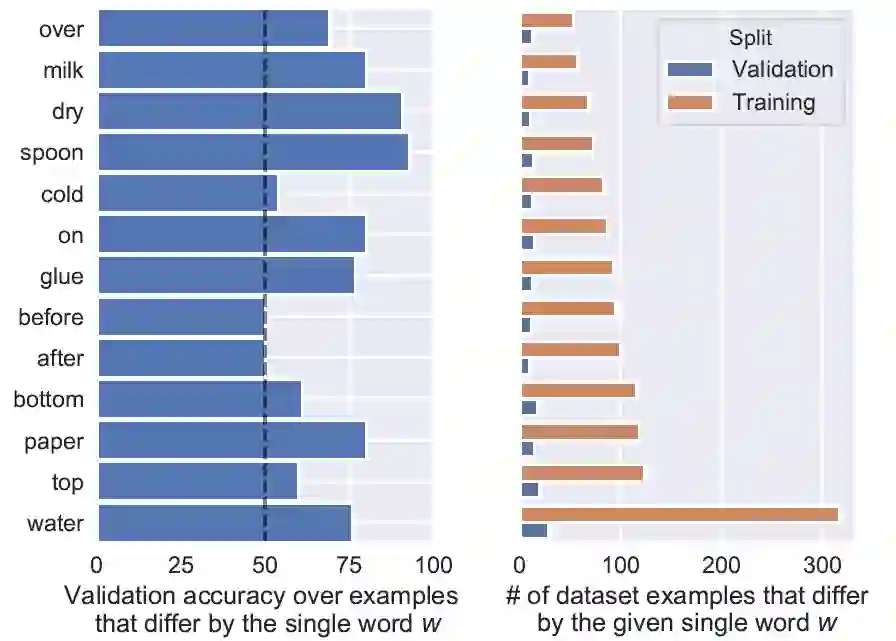
常识问题是人工智能领域最难的问题之一。在 NLP 领域,BERT 模型虽然已经表现出色,但是在常识知识问答数据集上的性能仍旧远低于人类。在计算机视觉领域,结合视觉场景的常识知识问答问题仍然具有较大难度。促进人工智能发展,使得机器具有「常识思维」,对于常识知识、常识推理的研究是值得关注的未来发展方向。本次 AAAI 2020 学术会议论文提前看,笔者挑选了常识知识、常识推理相关的 3 篇论文为大家作以解读。


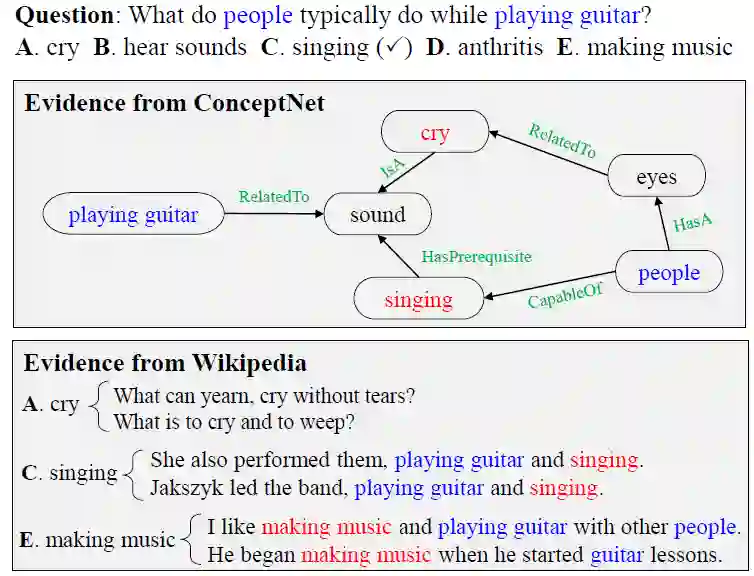
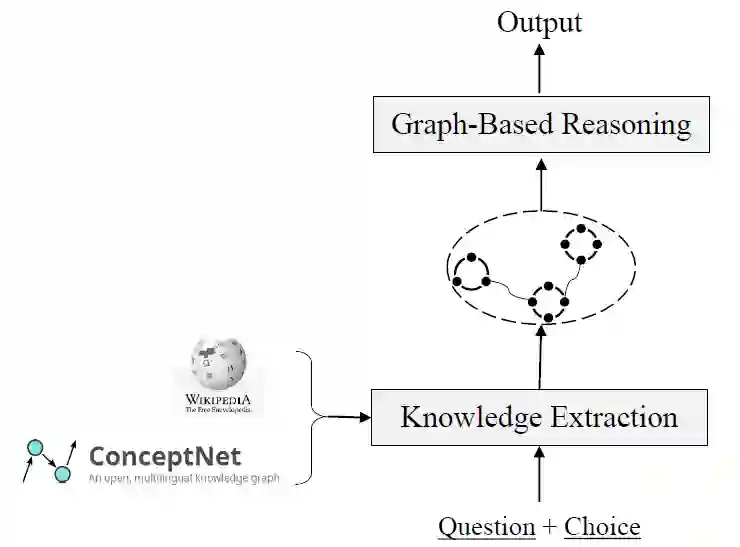

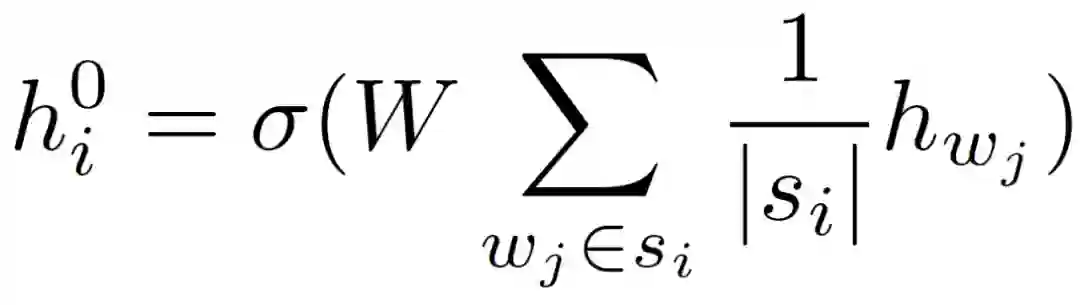
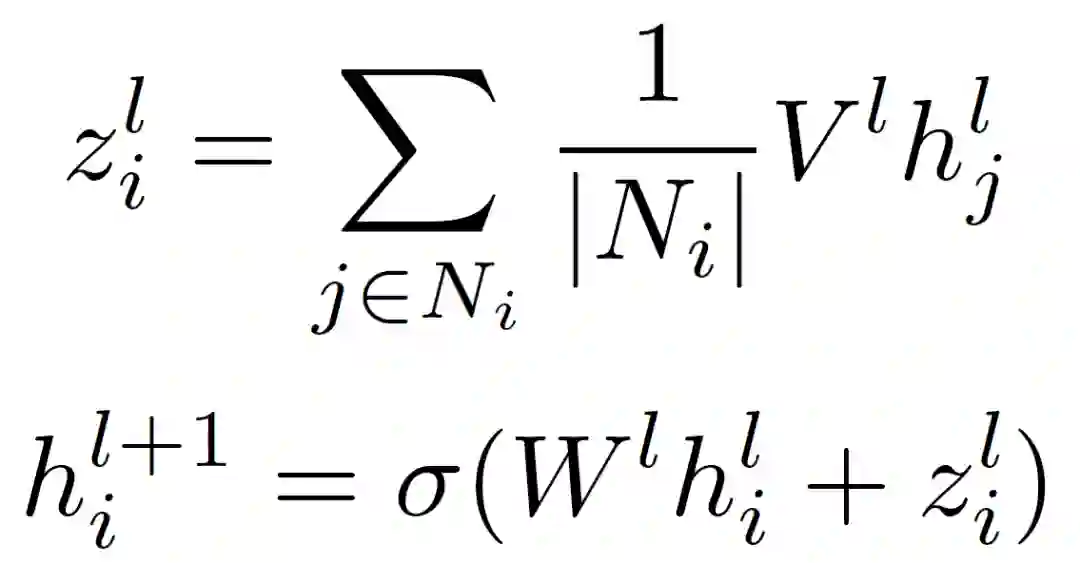
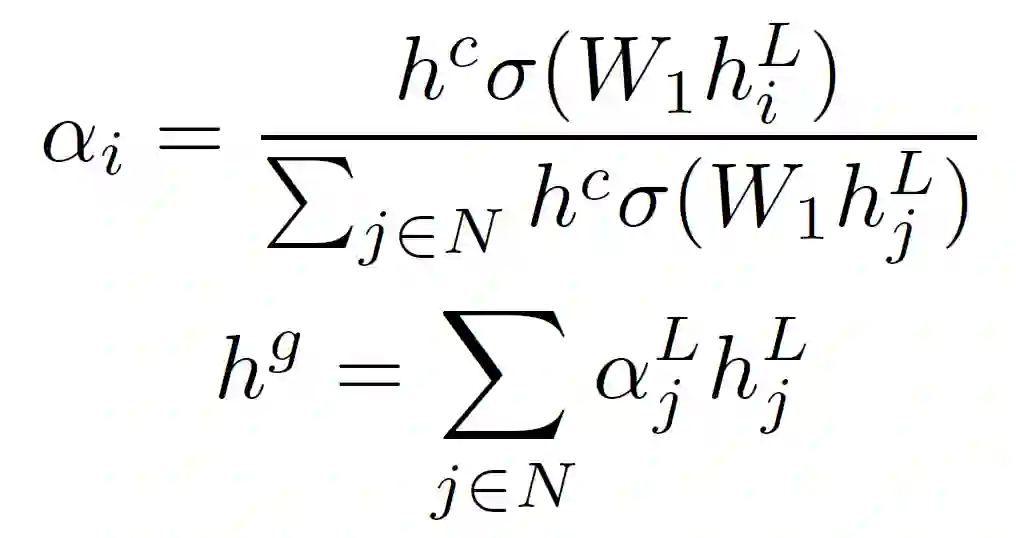
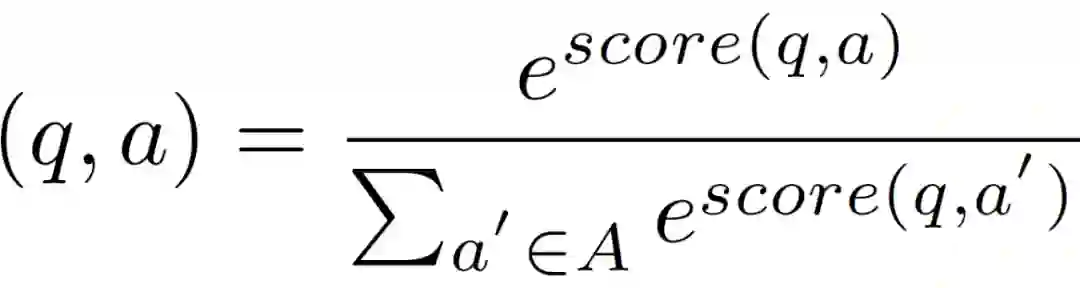
Group1:模型没有相应的描述,也没有发表论文
Group2:模型没有使用提取的知识
Group3:模型使用了提取的结构化知识
Gropu4:模型使用了提取的非结构化知识
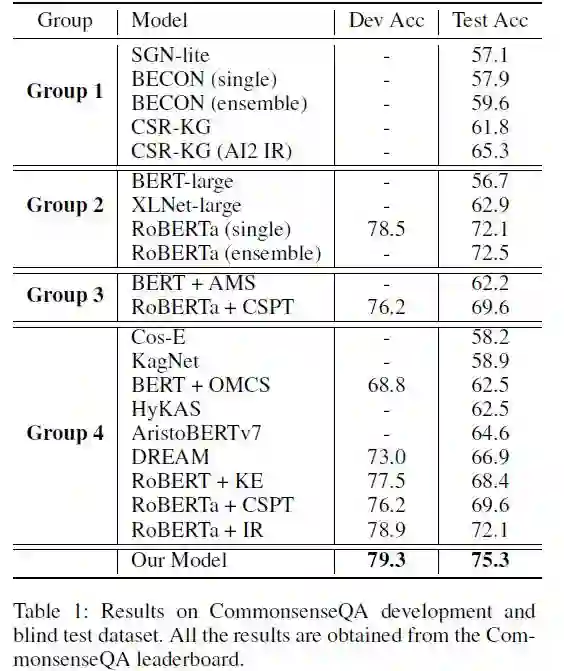


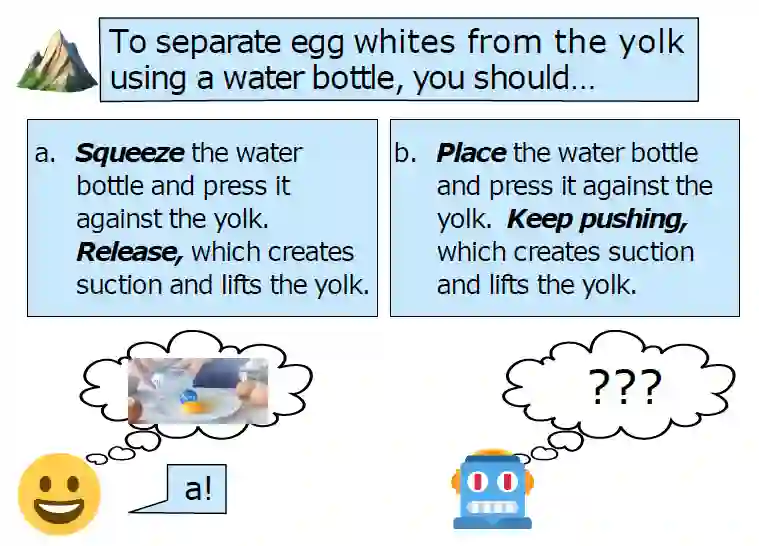
Commonsense Knowledge Base Completion with Structural and Semantic Context(利用结构和语义上下文的常识知识库实现)
论文链接:https://arxiv.org/pdf/1910.02915.pdf
Understanding the semantic content of sparse word embeddings using a commonsense knowledge base(使用常识知识库理解稀疏词嵌入的语义内容)
论文链接:https://kr2ml.github.io/2019/papers/KR2ML_2019_paper_29.pdf
Evaluating Commonsense in Pre-trained Language Models(在预训练语言模型中评估常识)
论文链接:https://arxiv.org/pdf/1911.11931.pdf
KnowIT VQA: Answering Knowledge-Based Questions about Videos(KnowIT VQA:回答关于视频的知识问题)
论文链接:https://arxiv.org/pdf/1910.10706.pdf
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年6月25日

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年6月25日