知识计算组实体对齐工作在ICBK2017学术会议上获得最佳学生论文奖
2017年8月9-10日第8届IEEE大知识国际学术会议(The 8th IEEE International Conference on Big Knowledge – ICBK2017)在合肥隆重举行。本届会议收到来自中国、美国、德国、加拿大、新加坡、韩国、土耳其、希腊等多个国家的70篇投稿,录用19篇,录用率27%。会上,知识计算组博士生官赛萍在实体对齐方面的工作“Self-learning and Embedding Based Entity Alignment”获得了最佳学生论文奖。
随着互联网技术和应用模式的迅猛发展,引发了互联网数据规模的爆炸式增长,知识图谱作为丰富直观的知识表达方式受到了广泛关注。实体对齐作为知识图谱的研究热点之一,在知识图谱构建和融合中发挥着重要作用。实体对齐旨在匹配不同实体库或不同知识图谱中的实体,比如匹配百度电影库中的电影ID实体和豆瓣电影库中的电影ID实体。
上述实例,来自不同库的两个电影ID实体,自身没有任何信息可用于对齐,传统基于实体自身信息重叠的对齐工作不能处理这种情况。针对这一现状,该工作提出了一种基于自学习和表示学习的无监督实体对齐方法SEEA(Self-learning and Embedding based Entity Alignment),更好地利用实体的属性信息进行对齐。SEEA的整体框架如下图所示:
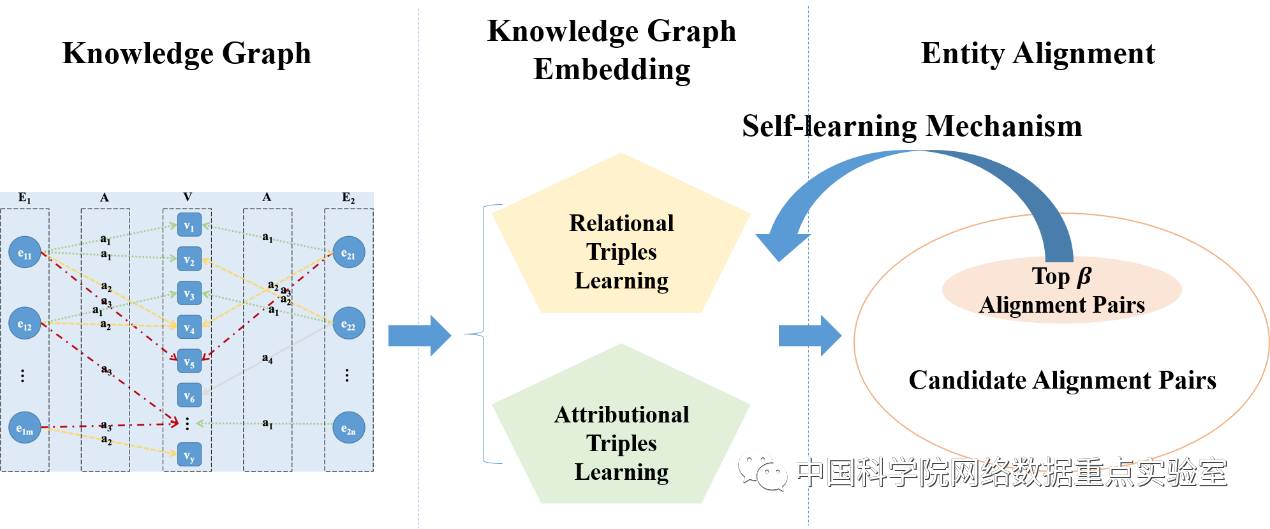
SEEA将待对齐的两个库构成一个知识图谱,作为输入。方法包含两个主要模块:知识图谱表示学习和实体对齐,以及一个重要机制:自学习机制。知识图谱表示学习模块区别对待关系三元组和属性三元组,这里的关系三元组只包含一种关系即对齐关系,一开始关系三元组为空,随着学习的推进,不断有学到的关系三元组加入。实体对齐模块通过实体表示的cosine相似度衡量实体匹配与否的程度。自学习机制作为实体对齐模块到知识图谱表示学习模块的反馈,选出top-β的双向匹配对齐实体对加入关系三元组进行下一轮训练,直至没有产生新的对齐实体对,停止迭代,产生最终实体对齐对。
在两个不同领域和不同语言的数据集:Cora1(抽取自论文引用数据集Cora)和Baidu Douban M/TV(来自百度电影和豆瓣电影)上的实验表明,文章提出的基于表示学习的对齐方法SEEA好于现有的表示学习方法。特别在Cora1数据集上,Recall和F1指标提升了8%左右。
Paper: Self-learning and Embedding Based Entity Alignment
Author: Saiping Guan, Xiaolong Jin, Yantao Jia, Yuanzhuo Wang, Huawei Shen and Xueqi Cheng


