【ESIM】论文阅读笔记:文本蕴含之ESIM
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要5分钟
跟随小博主,每天进步一丢丢


机器学习算法与自然语言处理出品
@公众号原创专栏作者 刘聪NLP
学校 | 中国药科大学 药学信息学硕士
知乎专栏 | 自然语言处理相关论文
最近一直在做自然语言推理和文本蕴含的相关工作,为了加深自己对论文的理解,在这里写下论文笔记。上一篇分享的文本蕴含论文bilateral multi-perspective matching (BiMPM)模型,这次分享的论文是Enhanced Sequential Inference Model(ESIM)。如果有错误的地方,请大家及时指正。

一、背景介绍
文本蕴含或者自然语言推理任务,就是判断后一句话(假设句)能否从前一句话(前提句)中推断出来。ESIM论文首先证明了基于链式LSTM的顺序推理模型可以优于之前使用非常复杂的网络结构的模型,在此基础上,进一步表明了通过增加局部推理和推理组合,可以很好地改进顺序推理模型。在这篇论文中,不仅介绍了ESIM模型,还介绍了包含语法分析信息的树型LSTM网络。我主要介绍ESIM模型部分。
二、模型介绍
模型主要包括四层:输入编码层(Input Encoding Layer)、局部推理层(Local Inference Layer)、推理组合层(Inference Composition Layer)和预测层(Prediction Layer),如图1所示,其中左边部分为ESIM模型,右边部分为树型LSTM网络。
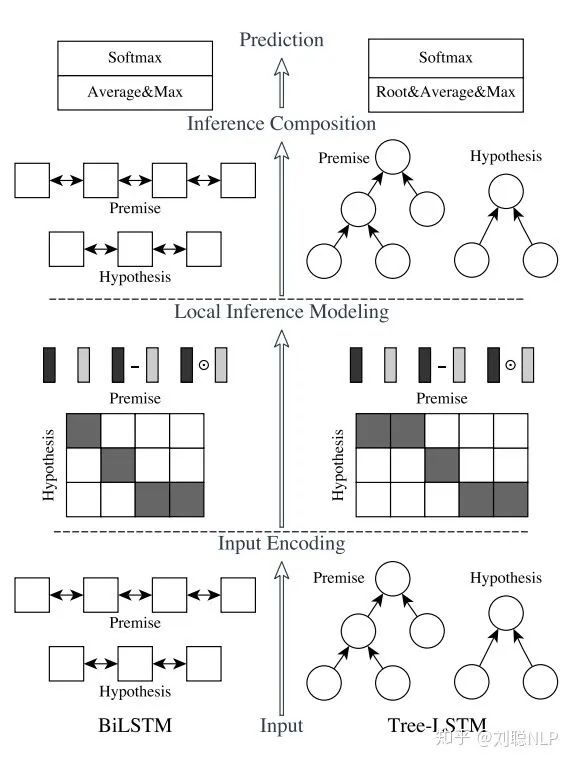
下面将对各层进行介绍:
1、输入编码层(Input Encoding Layer)
在这一层中,本模型首先对前提句和假设句中的每个词映射成一个向量,然后用一个双向LSTM分别编码前提句和假设句的词向量。在这里,BiLSTM使句子中的学每个单词具有其上下文含义。
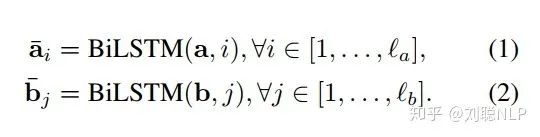
其中, 



2、局部推理层(Local Inference Layer)
在这一层中,本模型首先使用点积的方式,求解前提句和假设句的相似度矩阵,即
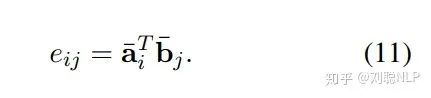
其中,
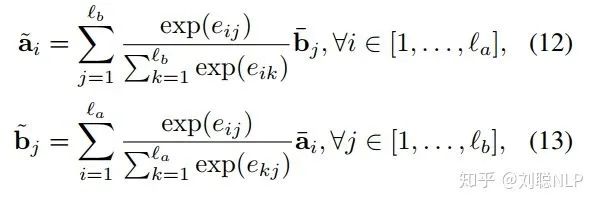
其中,




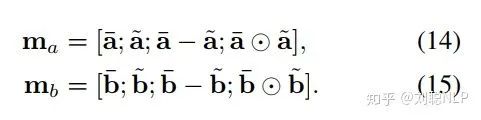
其中, 

3、推理组合层(Inference Composition Layer)
在这一层中,本模型首先使用BiLSTM对局部信息 


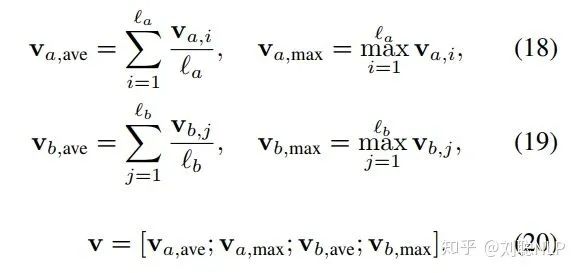
4、预测层(Prediction Layer)
在这一层中,本模型将上述得到的固定长度向量
三、模型参数
该论文中,word embedding为300维,所有的双向LSTM的隐层节点数为300,dropout rate为0.5,学习率为0.0004,采用adam优化器,第一动量设为0.9,第二动量设为0.999,batch size大小为32。在模型训练过程中,训练词向量。
四、总结
以上就是我对该篇论文的理解,如果有不对的地方,请大家见谅并多多指教。以后会继续做文本蕴含方面的分享,下一篇应该是孪生网络、DIIN或CAFE中的一篇。




