赛尔笔记 | 对话中的情感分析与生成简述

作者:哈工大SCIR 陆鑫,田一间
介绍
近年来,随着自然语言处理技术的快速发展,人机对话系统受到了很多关注,并逐渐成为了学术界和工业界的研究热点。人机对话系统不断发展进步,应用范围不断扩大,人们对它也有了更高的要求,希望机器在关注回复内容的基础上,可以与人进行更深入的交流。
近期的一些工作表明[10, 13, 15,16, 18-21, 23],在人机对话系统中,除了回复内容之外,机器与人的情感交流也是一个重要问题。人类可以通过语言进行情感上的交流,获得情感上的慰藉,对话系统想要和人类进行有效的情感沟通,就必须具备一定的情感能力。具体来说,机器一方面需要对用户情感进行识别和判断,另一方面也需要在其回复中融入合适的情感。因此,如何在对话中赋予机器理解情感和表达情感的能力,是人机对话和情感分析领域面临的新的机遇和挑战。
本文主要介绍对话情感中的两个关键任务:对话情绪识别、对话情感生成,梳理了这两个任务常用的数据集和相关方法。本文在接下来的部分首先阐述对话情绪识别任务的相关内容;接着围绕对话情感生成任务展开介绍;最后是全文总结和对未来的展望。
对话情绪识别
任务介绍
对话情绪识别是一个分类任务,旨在对一段对话中的话语进行情绪分类。任务的输入是一段连续的对话,输出是这段对话中所有话语的情绪,图1给出了一个简单的示例。由于对话本身具有很多要素,话语的情绪识别并不简单等同于单个句子的情绪识别,而是需要综合考虑对话中的背景、上下文、说话人等信息,这些都是对话情绪识别任务中独特的挑战。
对话情绪识别可广泛应用于各种对话场景中,如社交媒体中评论的情感分析、人工客服中客户的情绪分析等。此外,对话情绪识别还可应用于聊天机器人中,实时分析用户的情绪状态,实现基于用户情感驱动的回复生成。
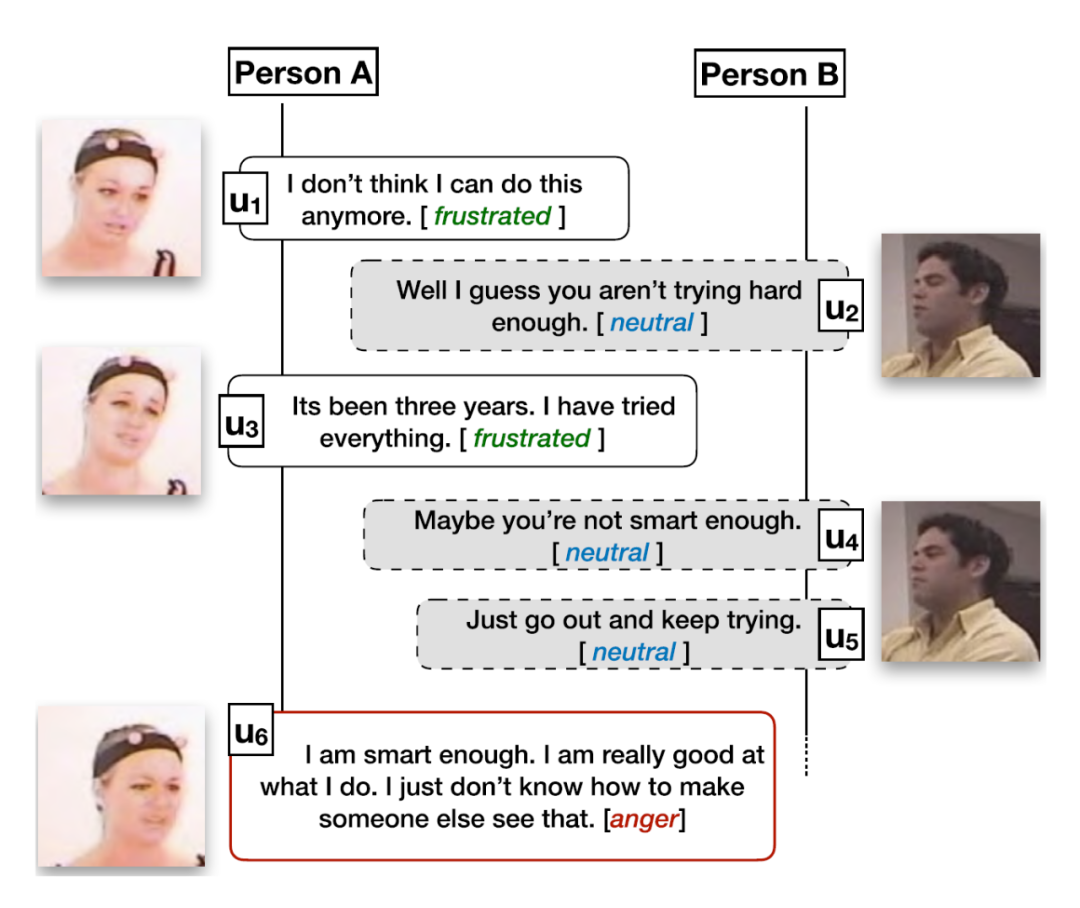
图1 对话情绪识别示例[1]
数据集介绍
IEMOCAP[2]。南加州大学的SAIL实验室收集,由人扮演的双人对话,12小时的多模态视听数据。10个专业演员(5男5女),一共分为5个Session,每个Session分配1男1女。对话分为两部分,一部分是固定的剧本,另一部分是给定主题情景下的自由发挥。151段对话,共7433句。标注了6类情绪:Neutral, Happiness, Sadness, Anger, Frustrated, Excited,非中性情绪占比77%。IEMOCAP是对话情绪识别中最常用的数据集,质量较高,优点是有多模态信息,缺点是数据规模较小。
数据集链接:https://sail.usc.edu/iemocap/
数据集链接:https://www.humanizing-ai.com/emocontext.html
数据集链接:https://affective-meld.github.io/
相关工作介绍
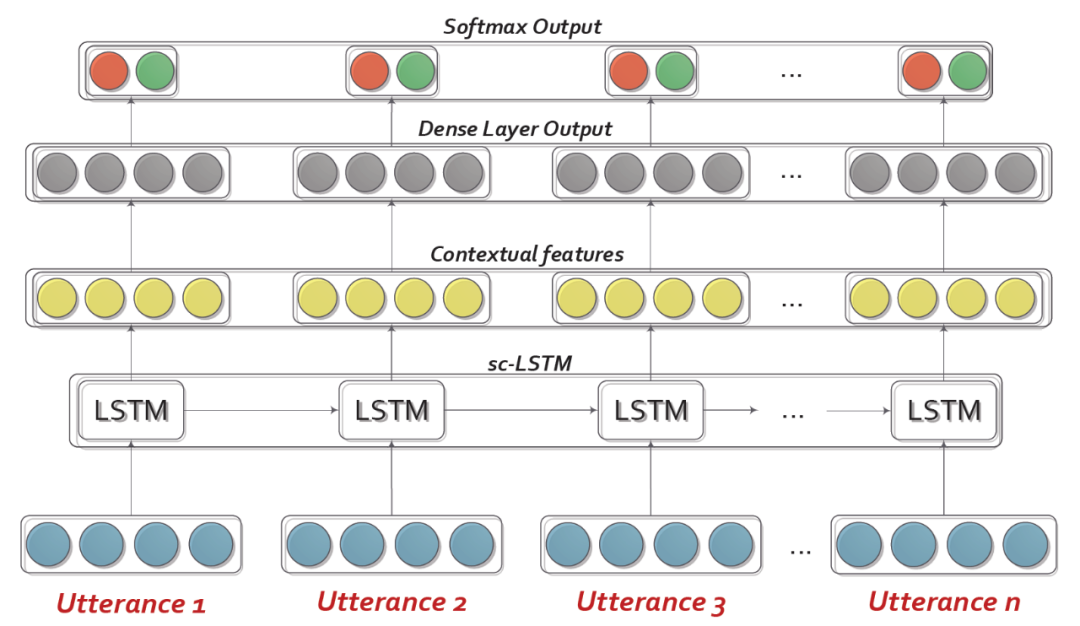
第一类:上下文建模
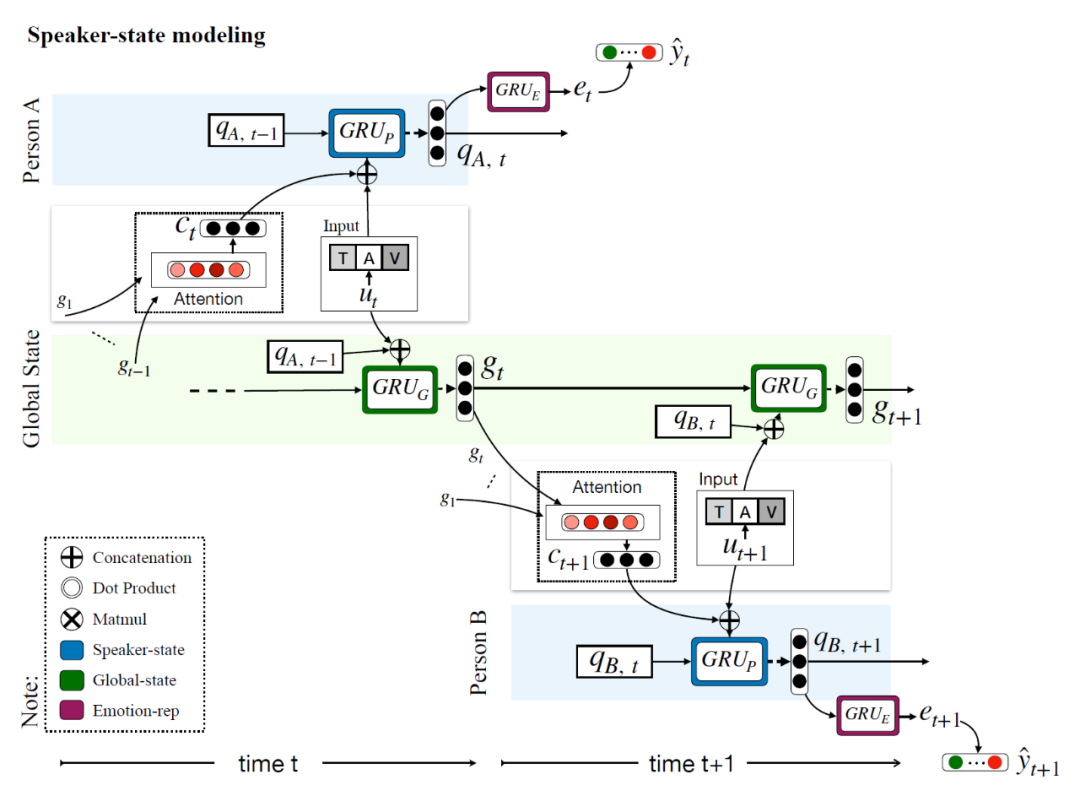
第二类:说话人建模
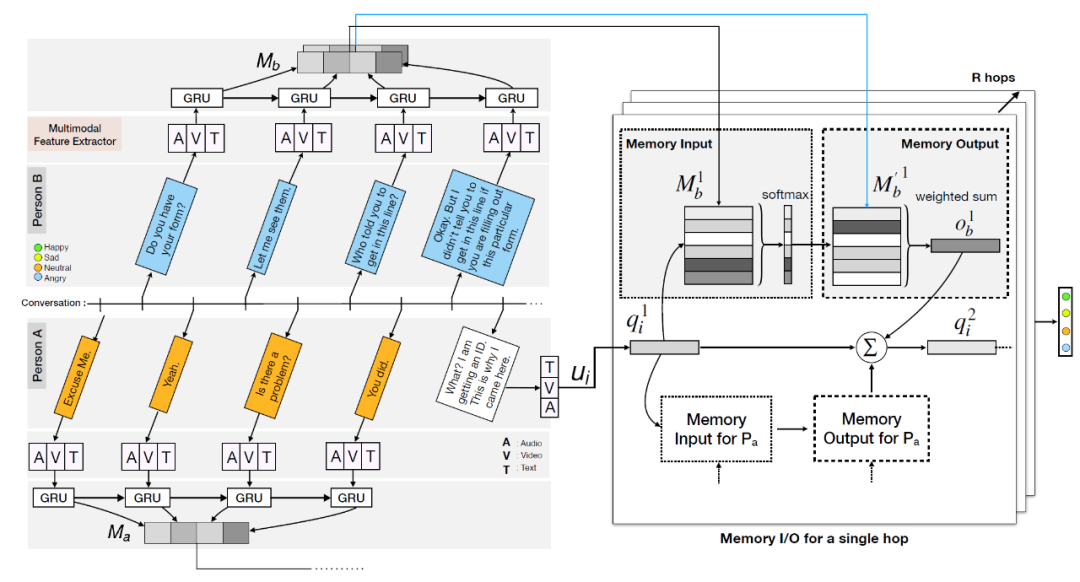
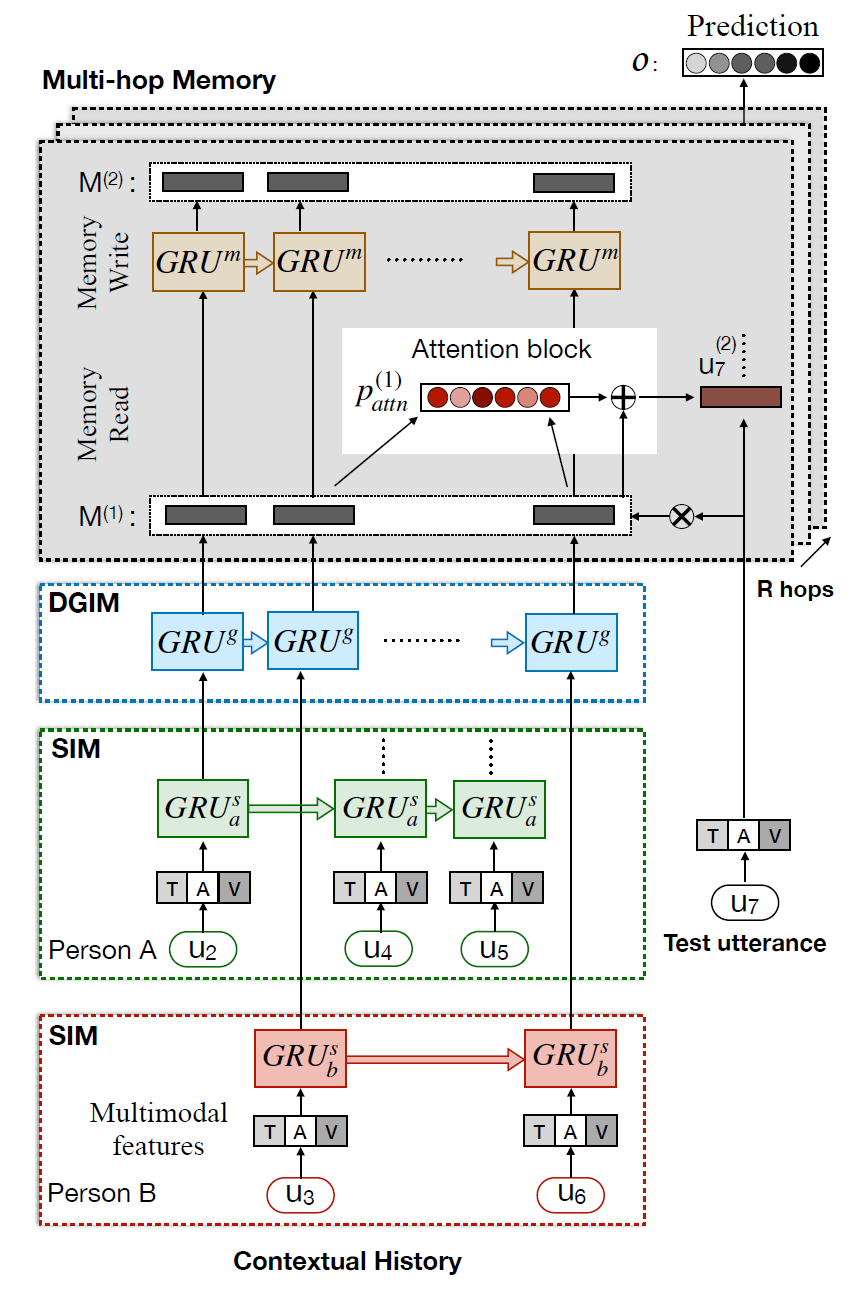
第三类:区分说话人的建模
对话情感生成
任务介绍
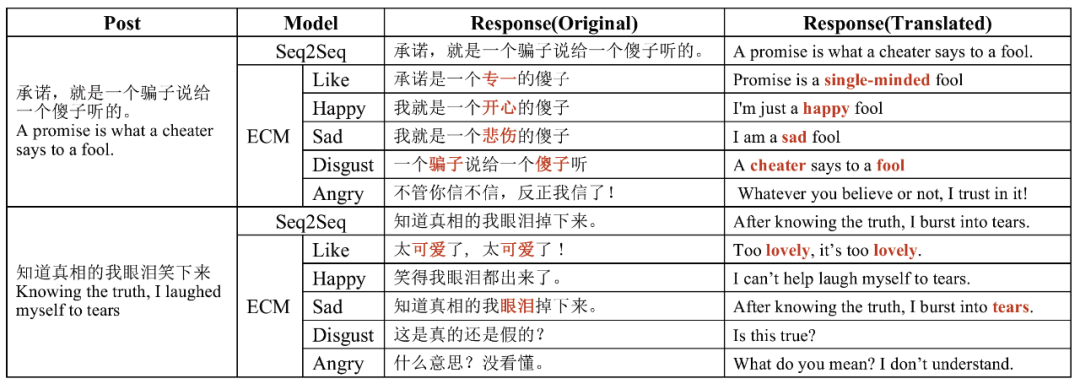
数据集介绍
数据集链接:http://ntcir12.noahlab.com.hk/stc.htm
数据集链接:http://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html
数据集链接:http://opus.nlpl.eu/OpenSubtitles-v2018.php
数据集链接:https://github.com/claude-zhou/MojiTalk
相关工作介绍
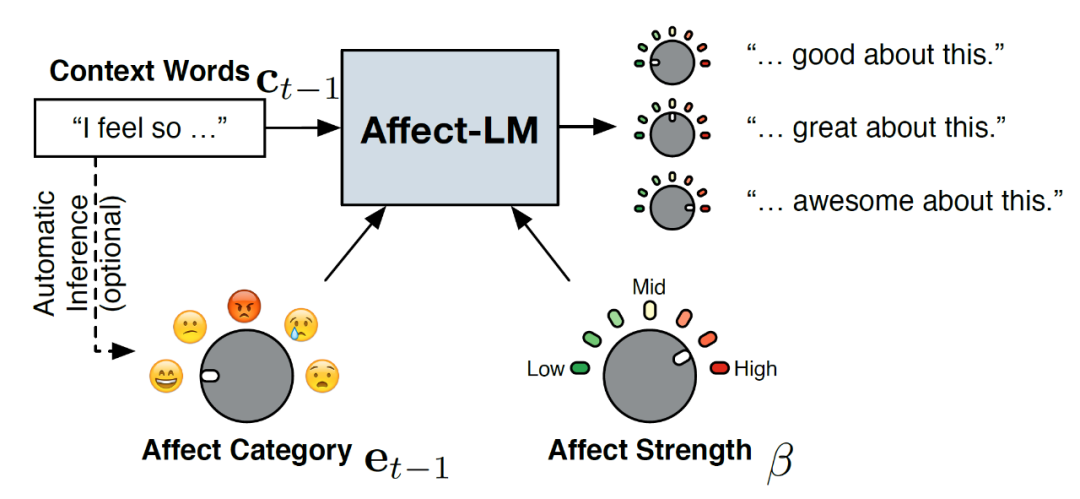
第一类:情感语言模型
第二类:指定回复情感的对话生成模型
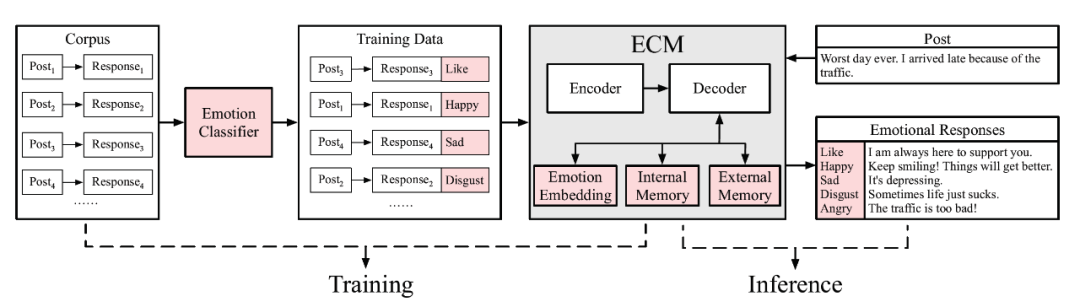
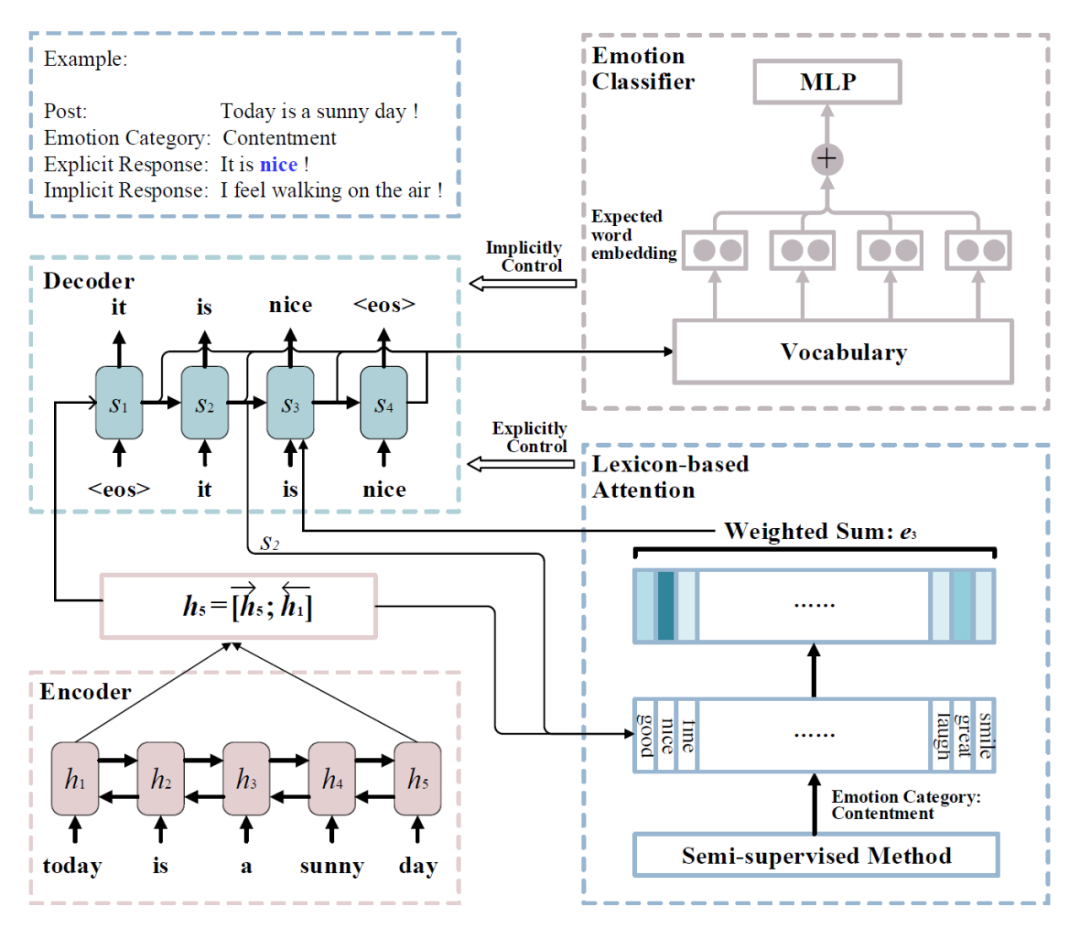
第三类:不指定回复情感的对话生成模型
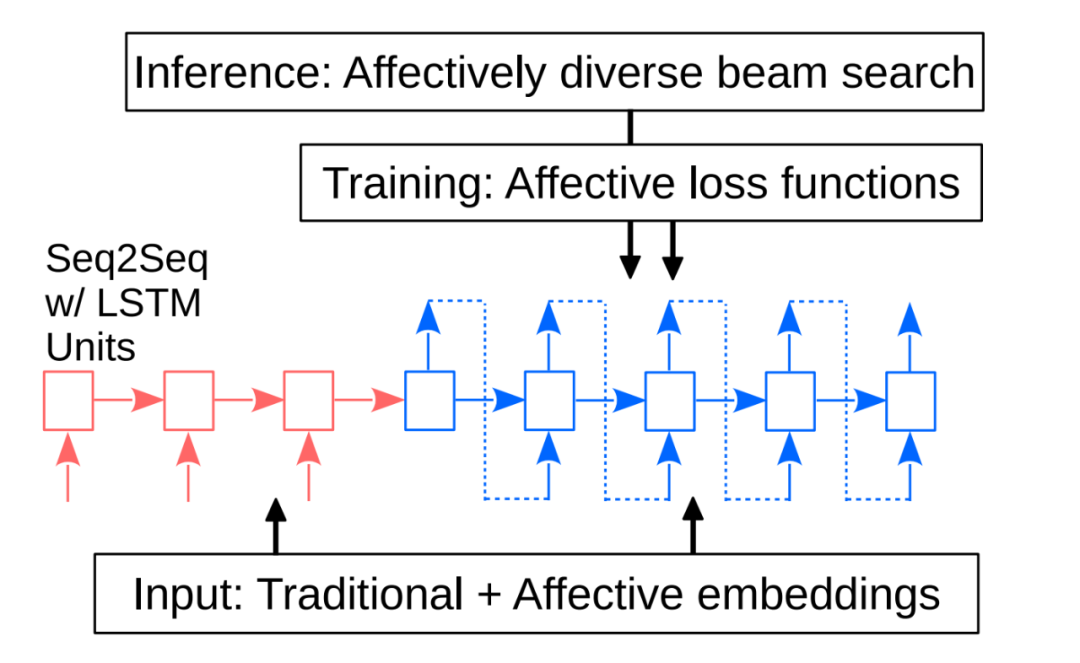
总结
参考资料
S. Poria, N. Majumder, R. Mihalcea, and E. Hovy. Emotion Recognition in Conversation: Research Challenges, Datasets, and Recent Advances. IEEE Access. 2019.
[2]C. Busso et al. IEMOCAP: interactive emotional dyadic motion capture database. Lang Resources & Evaluation. 2008.
[3]G. McKeown, M. Valstar, R. Cowie, M. Pantic, and M. Schroder. The SEMAINE Database: Annotated Multimodal Records of Emotionally Colored Conversations between a Person and a Limited Agent. IEEE Transactions on Affective Computing. 2012.
[4]Y. Li, H. Su, X. Shen, W. Li, Z. Cao, and S. Niu. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. IJCNLP. 2017.
[5]S.-Y. Chen, C.-C. Hsu, C.-C. Kuo, Ting-Hao, Huang, and L.-W. Ku. EmotionLines: An Emotion Corpus of Multi-Party Conversations. arXiv. 2018.
[6]A. Chatterjee, U. Gupta, M. K. Chinnakotla, R. Srikanth, M. Galley, and P. Agrawal. EmoContext: Understanding Emotions in Text Using Deep Learning and Big Data. Computers in Human Behavior. 2019.
[7]S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. ACL. 2019.
[8]S. Poria, E. Cambria, D. Hazarika, N. Majumder, A. Zadeh, and L.-P. Morency. Context-Dependent Sentiment Analysis in User-Generated Videos. ACL. 2017.
[9]D. Hazarika, S. Poria, A. Zadeh, E. Cambria, L.-P. Morency, and R. Zimmermann. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. NAACL. 2018.
[10]D. Hazarika, S. Poria, R. Mihalcea, E. Cambria, and R. Zimmermann. ICON: Interactive Conversational Memory Network for Multimodal Emotion Detection. EMNLP. 2018.
[11]N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, A. Gelbukh, and E. Cambria. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. arXiv. 2019.
[12]L. Shang, Z. Lu, and H. Li. Neural Responding Machine for Short-Text Conversation. ACL. 2015.
[13]H. Zhou, M. Huang, T. Zhang, X. Zhu, and B. Liu. Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory. AAAI. 2018.
[14]C. Danescu-Niculescu-Mizil and L. Lee. Chameleons in Imagined Conversations: A New Approach to Understanding Coordination of Linguistic Style in Dialogs. CMCL. 2011.
[15]N. Asghar, P. Poupart, J. Hoey, X. Jiang, and L. Mou. Affective Neural Response Generation. in Advances in Information Retrieval. 2018.
[16]P. Colombo, W. Witon, A. Modi, J. Kennedy, and M. Kapadia. Affect-Driven Dialog Generation. NAACL. 2019.
[17]J. Tiedemann. News from OPUS : A Collection of Multilingual Parallel Corpora with Tools and Interfaces. 2009.
[18]C. Huang, O. Zaïane, A. Trabelsi, and N. Dziri. Automatic Dialogue Generation with Expressed Emotions. NAACL. 2018.
[19]X. Zhou and W. Y. Wang. MojiTalk: Generating Emotional Responses at Scale. ACL. 2018.
[20]P. Zhong, D. Wang, and C. Miao. An Affect-Rich Neural Conversational Model with Biased Attention and Weighted Cross-Entropy Loss. AAAI. 2019.
[21]N. Lubis, S. Sakti, K. Yoshino, and S. Nakamura. Eliciting Positive Emotion through Affect-Sensitive Dialogue Response Generation: A Neural Network Approach. AAAI. 2018.
[22]S. Ghosh, M. Chollet, E. Laksana, L.-P. Morency, and S. Scherer. Affect-LM: A Neural Language Model for Customizable Affective Text Generation. ACL. 2017.
[23]Z. Song, X. Zheng, L. Liu, M. Xu, and X. Huang. Generating Responses with a Specific Emotion in Dialog. ACL. 2019.
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇