Weight Standarization:携手GN,超越BN
https://arxiv.org/abs/1903.10520
所属领域:深度学习-网络结构研究
一
温故而知新
先简要复习一下BN的概念:
(1)主要解决了:ICS(Internal Covariate Shift)现象

google原文这样定义:
We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training.
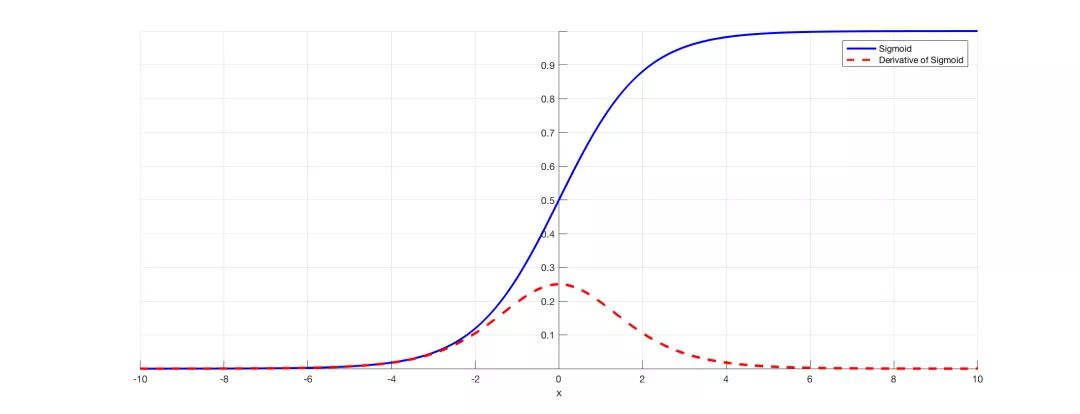
简单理解,就是激活函数势必会改变各层数据的分布,那么随着网络的加深,这种改变的趋势也会加剧,数据分布会越来越偏移。我们知道像sigmoid、tanh这一类激活函数在x绝对值较大时梯度较小,当x逐渐向函数两端区域靠拢时,模型将很难继续优化更新。
因此,BN试图将各层数据的分布固定住(目前能肯定的是,确实固定了数据的范围,但不一定真的调整了分布),使得各层数据在进入激活函数前,保持均值为0,方差为1的正态分布。这样就能使数据尽量靠近激活函数的中心,在反向传播时获得有效的梯度。
当然,由于BN的本质还是根据激活函数调整数据分布范围,所以增加了偏移量 

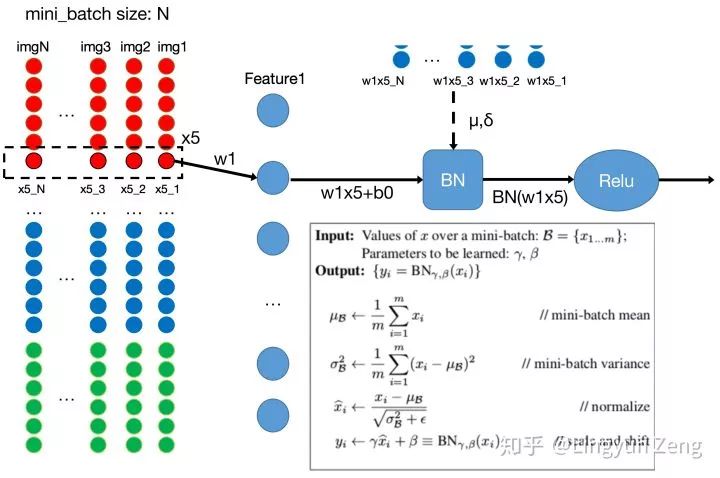
(2)计算方式
BN,batch normalization,即是对batch进行归一化。如图所示,一个batch取N张图片。
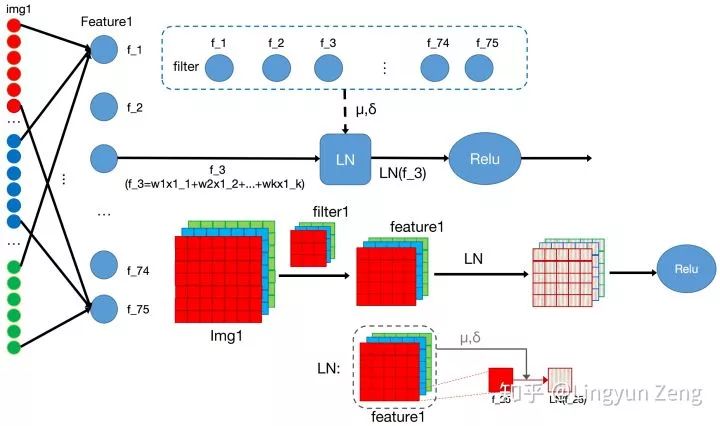
Layer normalization(LN)可以更好地帮助我们理解BN。BN是把整个batch的数据看做整体,针对每个神经元的输入来归一化。LN则是把每一层的数据看做整体,针对每一层进行归一化。解决了BN不能很好适用于RNN的问题。
(3)存在的问题
batch_size过小:由于BN是以整个batch来计算均值和方差,所以batch size不能设置过小,失去BN的意义。
batch_size过大:①超过内存容量 ②跑一次epoch迭代次数少,达到相同精度所需要的迭代次数(参数调整的次数)是差不多的,所以大的batch size需要跑更多的epoch,导致总的训练时间变长。③过大的batch size会直接固定下降方向,导致很难更新。
二
What is Weight standarization?
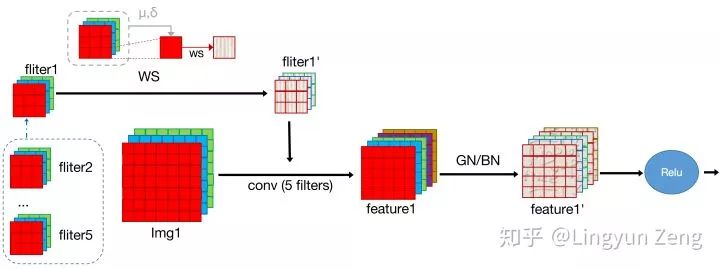
于是,为了像BN一样加速训练过程,又能够摆脱对于large batch size的限制,WS(Weight standarization)横空出世。
常见的normalization方式(e.g. BN,LN,IN,GN)都是从激活函数的输入来考虑,以不同的方式对激活函数的输入进行标准化;WS则想,我们这么费心费力地去处理卷积后的结果来加速训练,那为什么不直接去处理这个卷积的weight呢。最后实验表明,确实直接向weight下手对速度的影响更加直观。同时,直接处理weight,也很好地规避了对batch size的依赖,使得真正的mini batch size成为可能。
三
实验结果
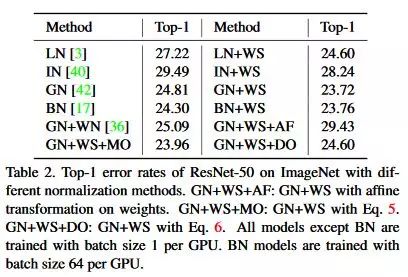
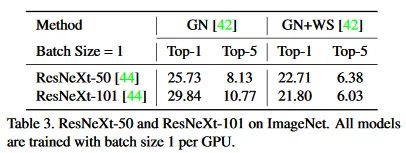
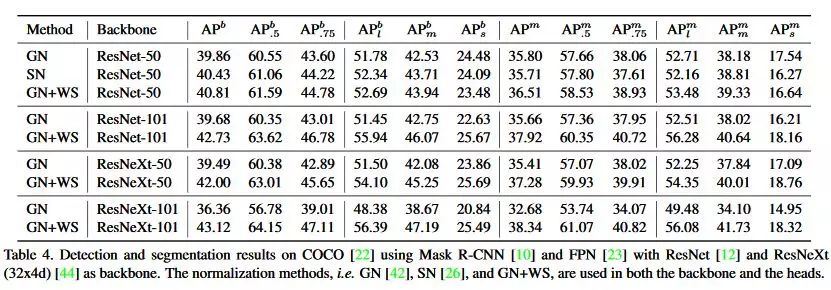
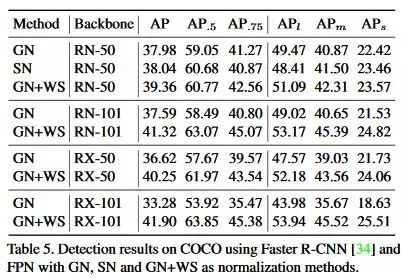
实验非常全面,在ImageNet、COCO、VOC、ModelNet40都对GN+WS和BN+WS做了详细的实验分析,具体可以去原文仔细阅读。
最后的结论是GN+WS可以在micro batch(1~2images per GPU)的条件下,匹配甚至超越BN在large batch size下的性能。

-----END-----
作者 | Lingyun Zeng
(https://www.zhihu.com/people/lingyun-zeng/activities)
版权声明
本文版权归《Lingyun Zeng》,转载请自行联系

历史文章推荐
AI综述专栏 | 多模态机器学习综述
深度学习中不得不学的Graph Embedding方法
旷视研究院新出8000点人脸关键点,堪比电影级表情捕捉
何恺明团队最新研究:3D目标检测新框架VoteNet,直接处理点云数据,刷新最高精度
打开阿兹海默之门:华裔张复伦利用RNN成功解码脑电波,合成语音 | Nature
图嵌入(Graph embedding)综述
半天2k赞火爆推特!李飞飞高徒发布33条神经网络训练秘技
再也不用担心我的公式写不出来了:一款公式输入神器实测
【深度学习】一文看尽深度学习各领域最新突破
2019 年 12 个深度学习最佳书籍清单!值得收藏
你正在看吗?👇

