神经网络中的权重初始化一览:从基础到Kaiming

大数据文摘出品
来源:medium
编译:李雷、刘思佳、张弛
在进行各种小实验和思维训练时,你会逐步发现为什么在训练深度神经网络时,合适的权重初始化是如此重要。
那么如何使用不同的方法初始化神经网络中的每层权重呢?
本文作者James Dellinger,总结了Jeremy Howard在fast.ai上最新的《Deep Learning Part II》课程之后,他自己在Jupyter Notebook上重做了一遍,然后为大家提供了以下建议。
为什么要初始化权重
权重初始化的目的是防止在深度神经网络的正向(前向)传播过程中层激活函数的输出损失梯度出现爆炸或消失。如果发生任何一种情况,损失梯度太大或太小,就无法有效地向后传播,并且即便可以向后传播,网络也需要花更长时间来达到收敛。
矩阵乘法是神经网络的基本数学运算。在多层深度神经网络中,一个正向传播仅需要在每层对该层的输入和权重矩阵执行连续的矩阵乘法。这样每层的乘积成为后续层的输入,依此类推。
举个简单的例子,假设我们有一个包含网络输入的向量x。训练神经网络的标准做法,是让输入值落入类似一个均值为0,标准差为1的正态分布中,以确保其被归一化。

让我们假设有一个没有激活函数的简单的100层网络,并且每层都有一个包含这层权重的矩阵a。为了完成单个正向传播,我们必须对每层输入和权重进行矩阵乘法,总共100次连续的矩阵乘法。
事实证明,把层权重值用标准正态分布进行初始化并不是一个好主意。为了弄明白个中原因,我们可以模拟网络的正向传播。
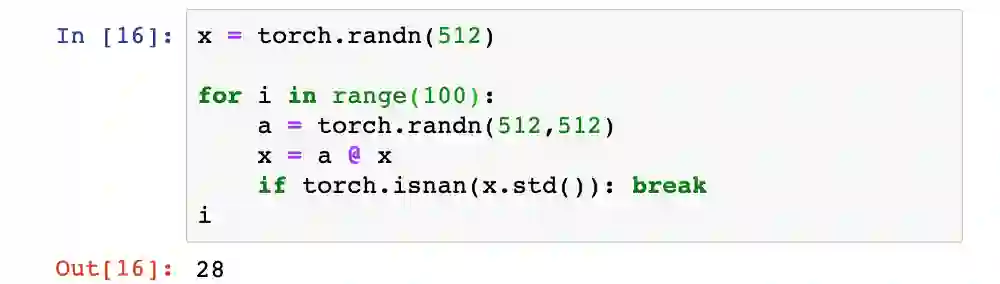
呃!在这100次矩阵乘法某次运算中,层输出变得非常大,甚至计算机都无法识别其标准差和均值。我们实际上可以看到产生这种结果需要多长时间。

在网络的第29个激活层输出发生梯度爆炸,很明显网络的权重初始化值过大。
不仅如此,我们同时还要防止层输出发生梯度消失。为了看看当网络权重初始值太小时会发生什么 - 我们将缩小例子的权重值,使它们仍然落入平均值为0的正态分布内,而标准差为0.01。
在上述假设的正向传播过程中,激活层输出出现了完全消失的现象。
总结一下,权重初始值太大或者太小,网络都将无法很好地进行学习。
怎样才能找到最佳值?
如上所述,神经网络正向传播在数学上只需做连续的矩阵乘法。如果输出y是输入向量x和权重矩阵a之间的矩阵乘法之积,则y中的第i个元素被定义为:
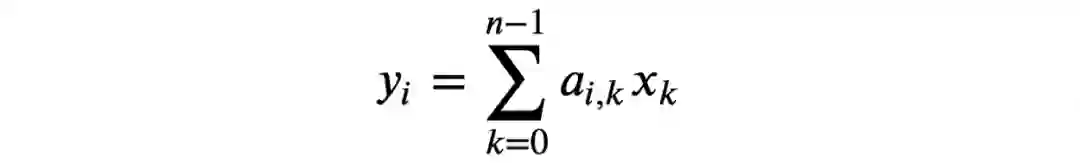
其中i是权重矩阵a给定行的索引,ķ既是给定列的索引及输入向量X的元素索引,n是X中元素的个数。这个公式可以在Python中表示为:
y[i] = sum([c*d for c,d in zip(a[i], x)])
可以证明,在某给定层,根据标准正态分布初始化的输入x和权重矩阵a的乘积,通常具有非常接近输入连接数平方根的标准差,在我们的例子中是√512。

如果我们从矩阵乘法定义来看这个值就再正常不过了:为了计算y,我们将输入向量x的某个元素乘以权重矩阵a的一列所得的512个乘积相加。在我们的例子中使用了标准正态分布来初始化x和a,所以这512个乘积的均值都为0,标准差都为1。
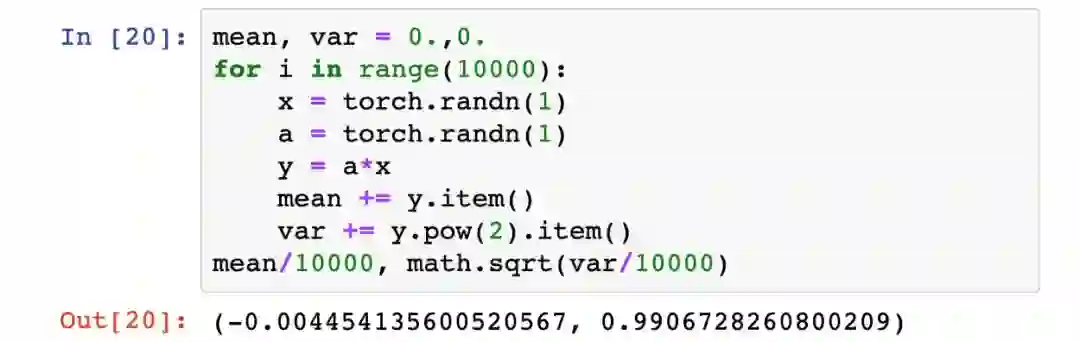
然后,这512个乘积的总和的均值为0,方差为512,因此标准差为√512。
这就是为什么在上面的例子中层输出在29次连续的矩阵乘法后会发生梯度爆炸。这个简单的100层网络架构中,我们想要的是每层输出具有大约1的标准差,这样就可以使我们在尽可能多的网络层上重复矩阵乘法,而不会发生梯度爆炸或消失。
如果我们首先通过将权重矩阵a的各随机选择值除以√512来对其进行缩小,那么生成输出y的某个元素的输入元素与权重乘积的方差通常只有1 /√512。
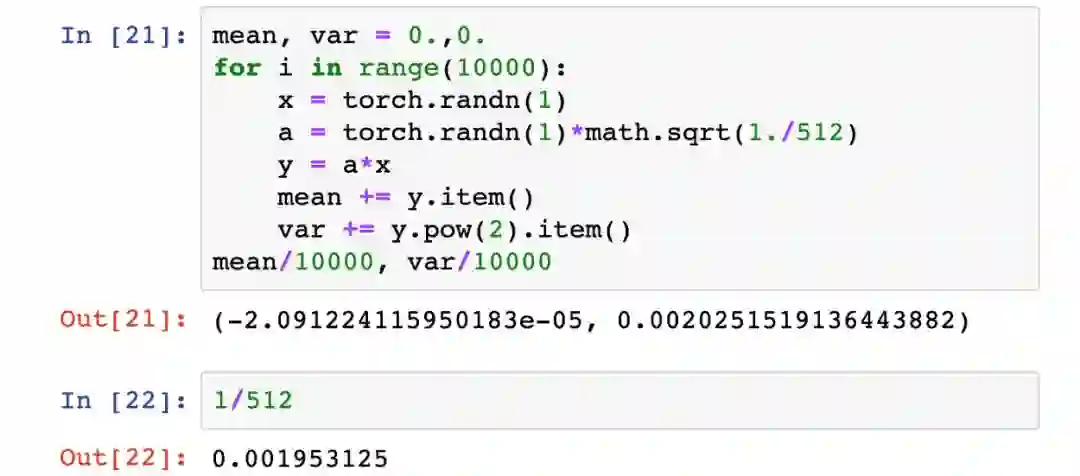
这意味着矩阵y的标准差(由输入x和权重a通过矩阵乘法生成的512个值组成)将是1。我们可以通过实验来验证。
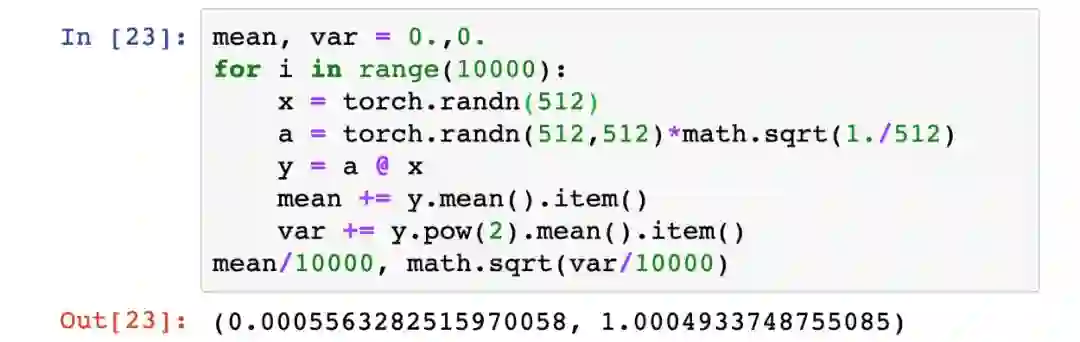
现在让我们重新运行之前的100层神经网络。与之前一样,我们首先从[-1,1]内的标准正态分布中随机选择层权重值,但这次我们用1/√n来缩小权重,其中n是每层的网络输入连接数,在我们的例子是512。

搞定!即使连续传播了100层之后,层输出也没有发生梯度爆炸或者消失。
虽然乍一看似乎真的搞定了,但现实世界的神经网络并不像我们这个例子那么简单。因为为简单起见,我们省略了激活函数。但是,在实际中我们永远不会这样做。正是因为有了这些置于网络层末端的非线性激活函数,深度神经网络才能非常近似地模拟真实世界那些错综复杂的现象,并且生成那些令人惊讶的预测,例如手写样本的分类。
Xavier初始化
直到几年前,最常用的激活函数还是基于给定点对称的,并且函数曲线在该点加/减一定数值的范围内。双曲正切线和softsign函数就是这类激活函数。
Tanh和softsign激活函数。图片来源:Sefik Ilkin Serengil的博客。
我们在假设的100层网络每一层之后添加双曲正切激活函数,然后看看当使用我们自己的权重初始化方案时会发生什么,这里层权重按1 /√n缩小。
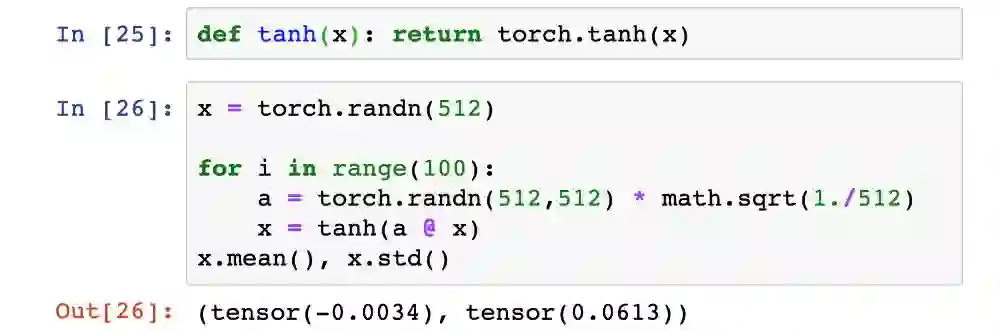
第100层的激活输出的标准偏差低至约0.06。这绝对是偏小的一面,但至少激活并没有完全消失!
现在回想起来,发现我们自己的权重初始化策略还是很直观的。但你可能会惊讶地发现,就在2010年,这还不是初始化权重层的传统方法。当Xavier Glorot和Yoshua Bengio发表了他们的标志性文章Understanding the difficulty of training deep feedforward neural networks,他们对比实验中的“常用启发式”是根据[-1,1]中的均匀分布来初始化权重,然后按1 /√n的比例缩放。
Understanding the difficulty of training deep feedforward neural networks
http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
事实证明,这种“标准”方法实际上并不能很好地发挥作用。

使用“标准”权重初始化方法重新运行我们的100层tanh网络会导致激活梯度变得无限小 - 就像消失一样了一样。
这种糟糕的结果实际上促使Glorot和Bengio提出他们自己的权重初始化策略,他们在他们的论文中称之为“正则化初始化”,现在通常被称为“Xavier初始化”。
Xavier初始化将每层权重设置为在有界的随机均匀分布中选择的值(如下表达式所示)
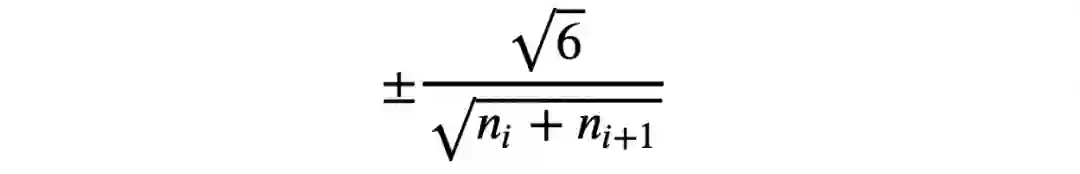
其中nᵢ是该层的传入网络连接数或该层的“fan-in”,nᵢ₊1是该层的传出网络连接数,也称为fan-out。
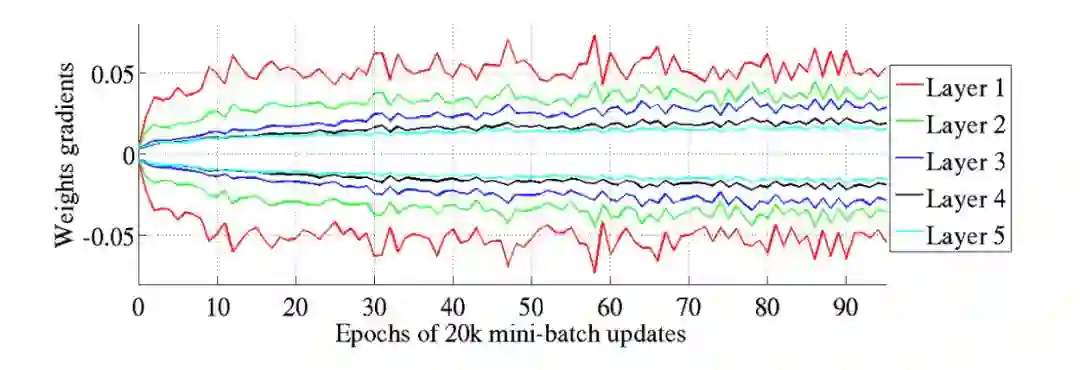
Glorot和Bengio认为Xavier权重初始化将保持激活函数和反向传播梯度的方差,一直向上或向下传播到神经网络的每一层。在他们的实验中,他们观察到Xavier初始化使一个5层网络能够将每层的权重梯度维持在基本一致的方差上。

相反,若不使用Xavier初始化,直接使用“标准”初始化会导致网络较低层(较高)的权值梯度与最上层(接近于零)的权值梯度之间的差异更大。
为了说明这一点,Glorot和Bengio证明了使用Xavier初始化的网络在CIFAR-10图像分类任务上实现了更快的收敛速度和更高的精度。让我们再次重新运行我们的100层tanh网络,这次使用Xavier初始化:

在我们的实验网络中,Xavier初始化方法与我们之前自定义方法非常相似,之前的方法是从随机正态分布中采样值,并通过传入网络连接数n的平方根进行缩放。
Kaiming初始化
从概念上讲,当使用关于零对称且在[-1,1]内有输出的激活函数(例如softsign和tanh)时,我们希望每层的激活输出的平均值为0,平均标准偏差大约为1,这是有道理的。这正是我们的自定义方法和Xavier都能实现的。
但是,如果我们使用ReLU激活函数呢?以同样的方式缩放随机初始权重值是否仍然有意义?
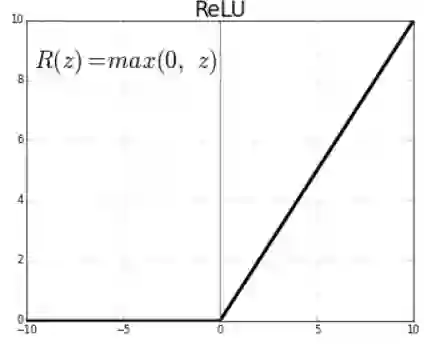
为了看看会发生什么,让我们在先前假设的网络层中使用ReLU激活来代替tanh,并观察其输出的预期标准偏差。

事实证明,当使用ReLU激活时,单个层的平均标准偏差将非常接近输入连接数的平方根除以2的平方根,在我们的例子中也就是√512/√2。

通过该值缩放权重矩阵a将使每个单独的ReLU层平均具有1的标准偏差。

正如我们之前所展示的那样,保持层激活的标准偏差大约为1将允许我们在深度神经网络中堆叠更多层而不会出现梯度爆炸或消失。
关于探索如何在类ReLU的激活的网络中最佳地初始化权重促使何凯明等优秀学者提出自己的初始化方案,这些方案是专门用来处理这些非对称,非线性激活的深层神经网络的。
在他们的2015年论文中何凯明等人证明了如果采用以下输入权重初始化策略,深层网络(例如22层CNN)会更早收敛:
1. 使用适合给定图层的权重矩阵创建张量,并使用从标准正态分布中随机选择的数字填充它。
2. 将每个随机选择的数字乘以√2/√n,其中n是从前一层输出到指定层的连接数(也称为“fan-in”)。
3. 偏差张量初始化为零。
我们可以按照这些指示来实现我们自己的Kaiming初始化版本,并验证如果在我们假设的100层网络的所有层使用ReLU,它确实可以防止激活输出爆炸或消失。

作为最后的比较,如果我们使用Xavier初始化,那么将会发生以下情况。

看!当使用Xavier初始化权重时,第100层的激活输出几乎完全消失了!
顺便提一下,当他们使用ReLU训练更深层的网络时。何凯明等人发现使用Xavier初始化的30层CNN完全停止并且不再学习。然而,当根据上面概述的三步初始化相同的网络时,它的收敛效果非常好。

对我们来说,故事的寓意是,我们从头开始训练的任何网络,特别是计算机视觉应用,几乎肯定会包含ReLU激活函数,并且是深度的。在这种情况下,Kaiming初始化应该是我们的首选权重初始化策略。
是的,你也可以成为一名研究员
更重要的是,当我第一次看到Xavier和Kaiming公式时,我并不羞于承认我感到畏惧。对于他们各自选用的六,二的平方根,我不禁感到这些一定是他们超凡的智慧结晶,但是我却无法理解的。但我们仍然要勇敢地面对它,有时深度学习论文中的数学很像象形文字,除了没有Rosetta Stone帮助翻译。
但我认为,我们在这里的经历向我们表明,这种感到恐惧的下意识反应虽然完全可以理解,但绝不是不可避免的。。虽然何凯明和(特别是)Xavier的论文确实包含了相当多的数学内容,但我们亲眼目睹了实验,经验观察。一些直观的常识足以帮助我们推导出当前最广泛使用的权重初始化方案的核心概念或者说:当有疑问时,要勇敢,尝试一下,看看会发生什么!
相关报道:
https://towardsdatascience.com/weight-initialization-in-neural-networks-a-journey-from-the-basics-to-kaiming-954fb9b47c79

大数据文摘联合R2.ai,请来了复旦大学的马博士,今晚8点,在线为各位讲述一个完整的建模流程如何实现,AutoML时代下的建模新特点,以及在这个时代保持自己的竞争优势。
长按海报二维码报名啦👇

实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
志愿者介绍
后台回复“志愿者”加入我们