重磅 | 2017年深度学习优化算法研究亮点最新综述火热出炉

翻译 | AI科技大本营(微信ID:rgznai100)
梯度下降算法是机器学习中使用非常广泛的优化算法,也是众多机器学习算法中最常用的优化方法。几乎当前每一个先进的(state-of-the-art)机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现。但是,它们就像一个黑盒子一样,很难得到它们优缺点的实际解释。
近日,Sebastian Ruder针对2017年优化算法的一些新方法,整理出了一份2017深度学习优化研究亮点报告,值得关注。
近年来有很多不同的优化算法被提出来了,这些算法采用不同的方程来更新模型的参数。如2015年推出的Adam算法(Kingma and Ba, 2015),可以说在今天仍然是最常用的一种优化算法之一。从机器学习实践者的角度来看,这表明优化深度学习的最佳实践在很大程度上还是保持不变的。
在过去的一年中,我们已经提出了新的算法优化想法,这将有助于未来我们优化模型的方式。在这篇博客文章中,我将介绍在我看来是深度学习上最令人兴奋的亮点和最有前途的优化方向。注意,阅读这个博客的基础是熟悉SGD算法和自适应调节学习率的算法,如Adam算法。
改进的Adam优化算法
尽管像Adam这样的自适应调节学习率的方法使用非常广泛,但是在计算机视觉和自然语言处理等许多相关任务上如目标识别(Huang et al.,2017)或机器翻译(Wu et al.,2016)[ 3 ],大多数先进的(state of the art)结果仍然是由传统的梯度下降算法SGD得到的。最近的理论(Wilson et al.,2017)提供了一些证据证明跟带动量的SGD算法相比,自适应学习率算法更难收敛到(并且不太理想的)最小值点。可以通过经验推测,在目标检测,字符级的语言建模和选区解析等任务上,自适应学习率方法找到的极小值比带动量 的SGD算法找到的极小值结果要差一些。这似乎是反直觉的,因为自适应学习率算法Adam能够保证良好的收敛,其结果应当比正常的SGD算法好。但是,Adam和其他的自适应学习率方法并不是没有自己的缺陷。
解耦权重衰减
在一些数据集上,与带动量的SGD算法相比, Adam算法泛化能力差的部分解释就是权重衰减。权重衰减最常用在图像分类问题里面,衰变的权重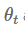
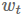
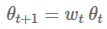
这可以防止权重值变得太大。因此,权重衰减也可以理解为一个L2正则化项,它依赖于权重衰减率
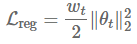
权重衰减在许多神经网络库中都有实现,可以作为上述的正则化项或者直接修改梯度。由于可以在动量和Adam算法的更新方程(通过与其他衰减项相乘)中修改梯度,所以权重衰减跟L2正则化也不一样。因此,Loshchilov和Hutter(2017)提出通过在像原始定义中那样梯度参数更新之后再添加解耦权重衰减。带动量和权重衰减更新的SGD算法(SGDW)如下所示:
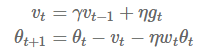
其中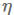
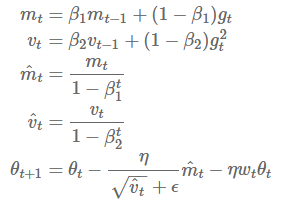
其中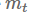
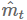
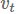
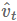
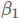
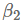
另外,它将学习率的选择与权重衰减的选择分开,这使得超参数的优化更好,因为超参数不再相互依赖。它还将优化器的实现与权重衰减的实现分开,这有助于实现更整洁和更可重用的代码(例如参见 fast.ai AdamW/SGDW implementation)。
修正指数滑动平均值
最近几篇论文(Dozat和Manning,2017; Laine和Aila,2017)通过实验发现,在Adam算法上,一个较低的
一篇已经提交正式的ICLR 2018论文提出了这样一个问题,指出基于使用前面迭代所产生梯度平方的指数滑动平均值是自适应学习率方法的泛化能力差的另一个原因。通过基于之前梯度平方的指数滑动平均来更新参数是自适应学习率方法的核心,例如Adadelta,RMSprop和Adam。指数平均的贡献应该在于:可以防止学习率随着训练的进行而变得极小,这是Adagrad算法的关键缺陷。但是,梯度的短期存储成为了其他情况下的障碍。
在Adam算法收敛到次优解的环境中,已经观察到一些minibatches提供了大的信息梯度,但是由于这些minibatches很少发生,指数平均减小了它们的影响,所以导致了收敛性差。作者提供了一个简单的凸优化问题的例子,利用Adam算法也可以观察到相同的行为。
为了解决这个问题,作者提出了一种新的算法AMSGrad,它使用基于之前梯度平方的最大值而不是指数平均值来更新参数。没有偏差纠正估计的完整的AMSGrad更新如下所示:
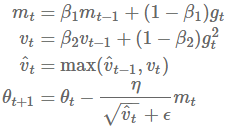
与Adam算法相比,作者在小数据集和CIFAR-10数据上看到了性能的提升。
微调学习率
在许多情况下,我们的模型是不需要改进和调整的,而是我们的超参数。最近的语言建模例子证明,与更复杂的模型相比,调整LSTM参数(Melis等,2017)和正则化参数(Merity等,2017)可以产生更好的(state of the art)结果。
在深度学习中优化的一个重要超参数是学习率
Zhang et al. (2017)表明,具有调整学习率退火方案和动量参数的SGD不仅与Adam算法相当,而且收敛速度更快。另一方面,虽然我们可能认为Adam算法的学习率的适应性可能模仿学习率退火,但是明确的退火方案仍然是有益的:在机器翻译(Denkowski和Neubig,2017)上,如果我们对Adam算法增加SGD样式的学习率退火,它的收敛速度更快。
事实上,学习率退火方案似乎是新的特征工程,因为我们经常可以找到改进的学习率退火方案,从而改善我们模型的最终收敛路径。一个有趣的例子是Vaswani et al. (2017)论文中提出的,虽然看到一个模型的超参数要经受大规模的超参数优化是很正常的,但有趣的是将学习率减小时间表看作是对细节同样重视的点:作者使用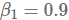
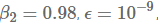
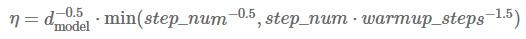
其中
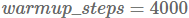
Smith et al. (2017) 最近的另一篇论文展示了学习率和批量大小之间的一个有趣的联系,两个超参数通常被认为是相互独立的:他们表明,减小学习率相当于增加批量大小,而后者 允许增加并行。相反,我们可以减少模型更新次数,从而通过增加学习率的值和缩放批量大小来加快训练速度。这对于大规模的深度学习是有影响的,可以在不需要调整超参数的情况下,重新调整现有的训练方式。
热重启(warm restarts)
加入重启的随机梯度下降算法(SGD with restarts)
另外一个最近提出的有效方法是SGDR ((Loshchilov and Hutter, 2017) [6]),是随机梯度下降算法的改进,使用了热重启技术取代学习率衰减。每次重启时,学习率初始化为一些值,然后逐渐减少。更重要的是,这机制是热重启,因为优化不是从头开始的,而是从模型在上一步收敛的参数开始的。关键的因素是学习率的衰减是基于陡峭的余弦衰减过程,这将很快的降低学习率,如下所示:
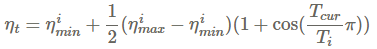
其中,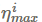
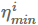
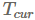
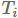
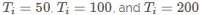
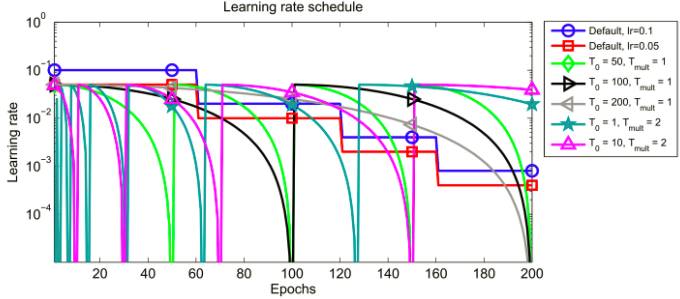
图1 使用了热重启的学习率迭代表(Loshchilov and Hutter, 2017)
重启后使用一个高的初始学习率能从根本上把参数的最优值弹射出去,到达之前收敛的地方,即到达损失函数曲面的不同区域。这种陡峭的衰减能使模型快速收敛到一个新的且更好的解。作者从经验发现,使用了热重启的随机梯度下降比学习率衰减方法迭代次数减少了2~4倍,并能达到相似的或者更好的性能。
使用热重启的学习率衰减也被称为循环学习率,最初由Smith提出的。fast.ai学生的另外两篇文章讨论了热重启和循环学习率,两篇文章分别可以从这里找到。
文章1:http://https%3A%2F%2Fmedium.com%2F%40bushaev%2Fimproving-the-way-we-work-with-learning-rate-5e99554f163b,
文章2:http://http%3A%2F%2Fteleported.in%2Fposts%2Fcyclic-learning-rate%2F
快照集合(Snapshot ensembles)
快照集合(Huang et al., 2017)是一个最近提出的非常巧的方法,它使用热启动组装成一个整体,当训练单模型时不用额外的代价。这种方法可以训练一个单模型,按照我们之前看到的余弦衰减时间表收敛,然后保存模型参数,并进行热重启,重复这一个步骤M次。最后,所有保存的模型快照形成一个集合。从图2可以看到常用的随机梯度下降优化过程的错误曲面与快照集合过程的对比。
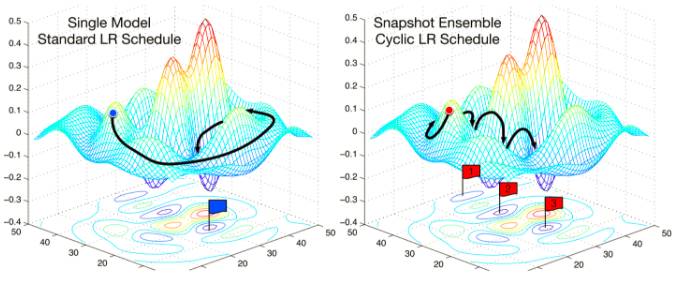
图2 随机梯度下降与快照集合(Huang et al., 2017)
一般来说,集合的成功在于集合中每个单独模型的多样性。因此,快照集合依赖于余弦衰减时间表能使模型在每次重启后都能收敛到不同的局部极值。作者在实践中证明,这是成立的,并在CIFAR-10, CIFAR-100, 和SVHN三个数据集上取得了目前最好的结果。
带重启动的Adam算法
正如我们之前看到的,由于权重衰减不正常,热启动最开始对Adam算法并不适用。在固定权重衰减后,Loshchilov and Hutter (2017) 同样的把热启动扩展到Adam。他们设置参数为

他们建议一开始选取较小的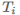
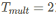
学习优化
去年最有意思的一篇文章(荣获Reddit网站 “2016年最好文章”)是由Andrychowicz et al. (2016)提出的,他们训练了一个长短期记忆网络优化器,在训练主要模型时更新参数。不幸的是,学习一个独立的长短期记忆网络优化器或者使用预训练的长短期记忆网络优化器进行优化会大大的增加训练模型的复杂度。
今年另外一个很有影响力的“学会学习(learning-to-learn)”论文在特定语言领域,使用了一个长短期记忆网络来生成模型架构。虽然搜索过程需要大量的资源,但是所发现的结构可以用来替代已有的方法。这个搜索过程被证明是有效的,且在语言建模上取得了最好的(state-of-the-art)结果,并且再CIFAR-10上取得很有竞争力的结果。
同样的搜索策略也可以应用到任何以前手工定义核心过程的其他领域,其中一个领域就是深度学习的优化算法。正如我们以前看到的,优化算法比他们看起来更相似:他们都使用指数滑动平均指数(如动量)和过去梯度平方的指数滑动平均值(如:Adadelta, RMSprop, and Adam)的组合
Bello等人定义了一种特定领域的语言,包含了对优化有用的原语,比如这些指数滑动平均值。然后,他们通过在所有可能的更新规则空间中采样,形成更新规则,使用这些规则训练模型,基于训练模型在测试集中的表现更新循环神经网络控制器。完整的流程见图3
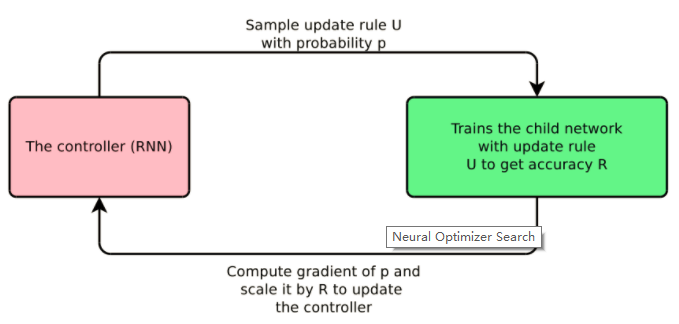
图3:神经优化搜索 (Bello et al., 2017)
特别是他们定义了两个更新公式,PowerSign和AddSign,PowerSign的更新公式如下:
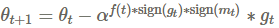
α是一个超参数,往往设置为e或者2. 函数f(t)设置为1或者衰减函数(线性、循环或者随着时间t衰减),m^t是过去梯度的滑动平均。通常设置为α=e,且无衰减。我们注意到,这个更新分别缩放梯度为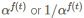
AddSign定义如下
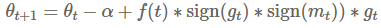
α经常设置为1或者2,与上面相似,这次的梯度尺度更新为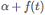
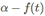
理解泛化
优化问题和泛化能力是密切相关的,因为模型收敛的最小值决定了模型泛化的程度。因此,优化问题的研究进展与理解这种极小值的泛化行为的理论进展是密切相关的,并且需要更深入地了解深度学习中的泛化问题。
然而,我们对深度神经网络泛化行为的理解仍然很浅。最近的研究表明,可能为局部最小值的数量随着参数数量呈指数型增长(Kawaguchi, 2016) [9]。考虑到当前深度学习结构巨大的参数数量,这样的模型能够很好的泛化得到解决方案,特别是考虑到它们能够完全记住随机的输入值,这似乎仍然是神奇的。
Keskar et al. (2017) [11] 认为最小值的清晰度是泛化能力不好的源头:他们特别地指出批量梯度下降所发现的尖锐极小值具有较高的泛化误差。这是直观的,因为我们通常会希望我们的函数是平滑的,尖锐的最小值表示相应误差表面高度的不规则性。但是,最近的研究表明,清晰度可能并不是一个好的指标,因为它表明局部最小值能够很好地泛化 (Dinh et al., 2017) [12]。Eric Jang在Quora上的回答也讨论了这篇文章。
提交给ICLR 2018的一份论文通过一系列消融分析,表明一个模型在激活空间会对单个方向有依赖性,即单个单元或特征图的激活是其泛化性能的良好预测。他们证明了这种模式适用于不同数据集的模型,以及不同程度的标签损坏。他们发现dropout并不能帮助解决这个问题,而批次规范化将阻碍单方向的依赖性。
虽然以上这些研究表明依然还存在很多我们所不知道的深度学习优化知识,但重要的是记住,收敛保证和存在于凸优化中的大量工作,在一定程度上现有的想法和见解也可以应用于非凸优化问题上。
NIPS2016上大量的优化教程提供了该领域更多理论工作的完美概述,可以帮助你了解更多这方面的知识。真的是一个非常让人兴奋的研究方向。
原文地址
http://ruder.io/deep-learning-optimization-2017/index.html
热文精选
Reddit热点 | 想看被打码的羞羞图片怎么办?CNN帮你解决
何恺明团队推出Mask^X R-CNN,将实例分割扩展到3000类
AI人才缺失催生的“跨境猎头”,人才年薪高达300万,猎头直赚100万
深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径
专访图灵奖得主John Hopcroft:中国必须提升本科教育水平,才能在AI领域赶上美国


