YOLOv4团队开源最新力作!1774fps、COCO最高精度,分别适合高低端GPU的YOLO

极市导读
本文是YOLOv4的原班人马(包含CSPNet一作与YOLOv4一作AB大神)在YOLO系列的继续扩展,从影响模型扩展的几个不同因素出发,提出了两种分别适合于低端GPU和高端GPU的YOLO。该文所提出的YOLO-large在MSCOCO取得前所未有的精度(已公开的研究成果中最佳),且可以保持实时推理;所提出的YOLO-tiny在RTX 2080Ti显卡上结合TensorRT+FP16等技术,可以达到惊人的1774FPS@batch=4. >>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文标题:Scaled-YOLOv4:Scaling Cross Stage Partial Network
链接:https://arxiv.org/2011.08036
代码: https://github.com/WongKinYiu/ScaledYOLOv4
YOLOv4-CSP: https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-csp
YOLOv4-tiny: https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-tiny
YOLOv4-large: https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-large
Abstract
该文提出一种“网路扩展(Network Scaling)”方法,它不仅针对深度、宽度、分辨率进行调整,同时调整网络结果,作者将这种方法称之为Scaled-YOLOv4。
由此得到的YOLOv4-Large取得了SOTA结果:在MS-COCO数据集上取得了55.4%AP(73.3% AP50),推理速度为15fps@Tesla V100;在添加TTA后,该模型达到了55.8%AP(73.2%AP50)。截止目前,在所有公开论文中,YOLOv-Large在COCO数据集上取得最佳指标。而由此得到的YOLOv4-tiny取得了22.0%AP(42.0%AP50),推理速度为443fps@TRX 2080Ti;经由TensorRT加速以及FP16推理,batchsize=4时其推理速度可达1774fps。
该文的主要贡献包含以下几点:
-
设计了一种强有力的“网络扩展”方法用于提升小模型的性能,可以同时平衡计算复杂度与内存占用; -
设计了一种简单而有效的策略用于扩展大目标检测器; -
分析了模型扩展因子之间的相关性并基于最优划分进行模型扩展; -
通过实验证实:FPN structure is inherently a once-for-all structure -
基于前述分析设计了两种高效模型:YOLOv4-tiny与YOLOv4-Large。
Principles of model scaling
在这部分内容里面,我们将讨论一下模型扩展的一些准则。从三个方面展开介绍:(1) 量化因子的分析与设计;(2) 低端GPU上tiny目标检测器的量化因子;(3) 高端GPU上目标检测器的量化因子设计分析。
General principle of model scaling
When the scale is up/down, the lower/higher the quantitative cost we want to increase/decrease, the better. ----author
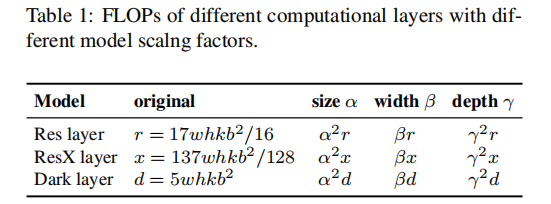
上面给出了模型扩展所需要考虑的一些因素。接下来,我们将分析几种不同的CNN模型(ResNet, ResNeXt, DarkNet)并尝试理解其相对于输入大小、层数、通道数等的定量损失。
对于包含k层b个通道的CNN而言,ResNet的计算量为:
,
ResNeXt的是:
,
DarkNet的是:
。
假设用于调整图像大小、层数以及通道数的因子分别为
,其调整对应的FLOPs变化见下表,可以看到:它们与FLOPs提升的关系分别是square, linear, square。
CSPNet可以应用与不同的CNN架构中,且可以降低参数量与计算量,同时还可以提升精度与降低推理耗时。下表给出了CSPNet应用到ResNet,ResNeXt与DarkNet时的FLOPs变化,可以看到:新的架构可以极大的降低计算量,ResNet降低23.5%,ResNeXt降低46.7%,DarkNet降低50.0%。因此CSP-ized是适合模型扩张的最佳模型。

Scaling Tiny Models for Low-End Devices
对于低端设备而言,模型的推理速度不仅受计算量、模型大小影响,更重要的是,外部设备的硬件资源同样需要考虑。因此,当进行tiny模型扩展时,我们必须考虑带宽、MACs、DRAM等因素。为将上述因素纳入考量范围,其设计原则需要包含西面几个原则:
-
Make the order of computation less than .
相比大模型,轻量型模型的不同之处在于:参数利用率更高(保采用更少的计算量获得更高的精度)。当进行模型扩展时,我们期望计算复杂度要尽可能的低。下表给出了两种可以高效利用参数的模型对比。

对于通用CNN来说, 之间的性见上表( )。因此,DenseNet的计算复杂度为 ,OSANet的计算复杂度为 。两者的计算复杂度阶段都比ResNet( )的更低。在这里作者选用了OSANet作为tiny模型的选型。
-
Minimize/balance size of feature map.
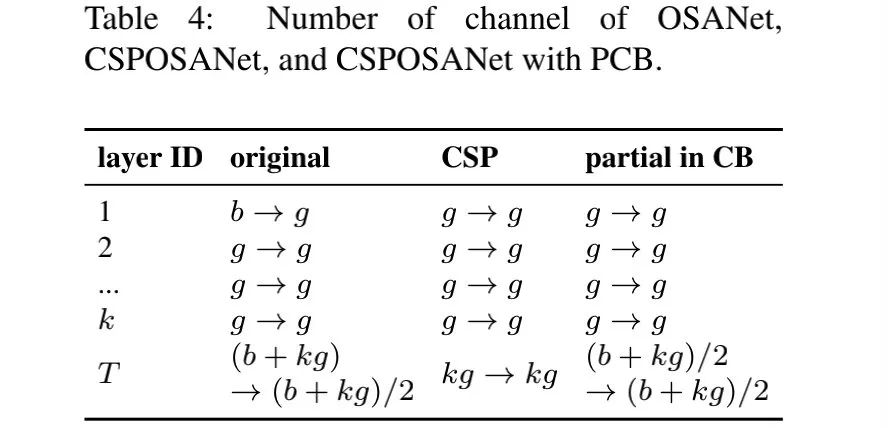
为获得最佳的推理速度-精度均衡,作者提出了一个新的概念用于在CPSOSANet计算模块之间进行梯度截断。如果把CSPNet设计思想用到DenseNet或者R二十Net架构中,由于第 层的输出是 到 的集成融合,我们必须把完整的计算模块当做一个整体来看待。由于OSANet的计算模块属于PlainNet架构的范畴,这就使得CSPNet的任一层都可以得到有效的梯度截断。我们采用这个特征重组b个通道以及计算模块中的kg通道,将其以相同的通道数划分到两个分支,见下表。当通道数为 时,最佳的划分方式为均等划分 。事实上,我们还要考虑硬件的带宽 因素,此时的最佳划分则表示为 。该文提出的CSPOSANet可以动态的调整通道分配。
-
Maintain the same number of channels after convolution
对于低端设备的计算复杂度评估,我们还需要考虑功耗,而影响功耗的最大因素当属MAC(memory access cost)。通常来说,卷积的MAC计算方式如下:
-
Minimize Convolutional Input/Output(CIO)
CIO是一个用来评价DRAM的IO状态的度量准则,下表给出了OSA,CSP的CIO对比。当 时,本文所提出的CSPOSANet具有最佳CIO。

Scaling Large Models for High-End GPUS
由于我们期望提升扩张CNN模型的精度,同时保持实时推理速度,这就要求我们需要从目标检测器的所有扩展因子中寻找最佳组合。通常而言,我们可以调整目标检测器的输入、骨干网络以及neck的尺度因子,潜在的尺度因子见下表。
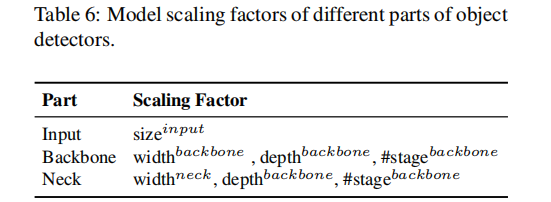
图像分类与目标检测的最大区别在于:前者仅需要对图像中的最大成分进行分类,而后者则需要预测图像中每个目标的位置。在单阶段目标检测器中,每个位置的特征向量用于预测类别、目标的大小,而目标大小的预测则依赖于特征向量的感受野。在CNN中,与感受野最相关的当属stage,而FPN结构告诉我们:更高的阶段更适合预测大目标。

上表汇总了与感受野相关因素,可以看到:宽度扩展不会影响感受野。当输入图像分辨率提升后,为保持感受野不变,那么就需要提升depth或者stage。也及时说:depth和stage具有最大的影响。因此,当进行向上扩增时,我们需要在输入分辨率、stage方面进行扩增以满足实时性,然后再进行depth和width的扩增。
Scaled-YOLOv4
接下来,我们将尝试把YOLOv4扩展到不同的GPU(包含低端和高端GPU)。
CSP-ized YOLOv4
YOLOv4是一种针对通用GPU设计的实时目标检测方案。在这里,作者对YOLOv4进行重新设计得到YOLOv4-CSP以获取最佳的速度-精度均衡。
Backbone
在CSPDarknet53的设计中,跨阶段的下采样卷积计算量并未包含在残差模块中。因此,作者推断:每个CSPDarknet阶段的计算量为 。从该推断出发,CSPDarknet比DarkNet具有更好的计算量优势(k>1)。CSPDarkNet53每个阶段的残差数量分别为1-2-8-8-4。为得到更好的速度-精度均衡,作者将首个CSP阶段转换为原始的DarkNet残差层。
Neck
更有效的降低参数量,作者将PAN架构引入到YOLOv4中。PAN架构的处理流程见下图a,它主要集成了来自不同特征金字塔的特征。改进后的处理流程见下图b,它还同时引入了ChannelSplitting机制。这种新的处理方式可以节省40%计算量。
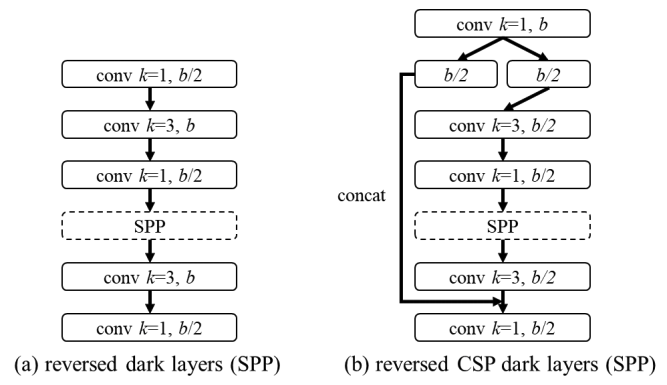
SPP
原始的SPP模块位于Neck中间部分,作者同样将SPP插入到CSPPAN中间位置,见上图b。
YOLOv4-tiny
YOLOv4是专为低端GPU而设计的一种架构,其计算模块见下图。在这里,作者采用CSPOSANet+PCB架构构成了YOLOv4的骨干部分。
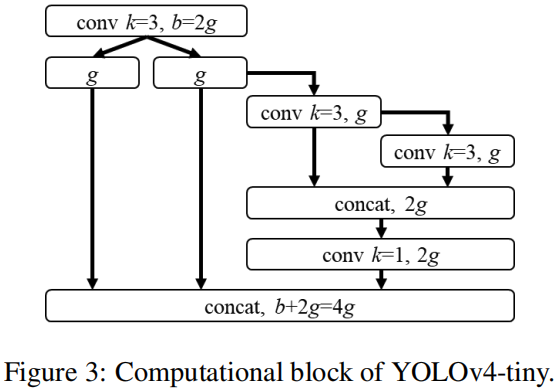
在计算模块中, 。通过计算,作者推断得到k=3,其对应的计算单元示意图见上图。至于YOLOv4-tiny的通道数信息,作者延续了YOLOv3-tiny的设计。
YOLOv4-large
YOLOv4-large是专为云端GPU而设计的一种架构,主要目的在于获得更好的目标检测精度。作者基于前述分析设计了一个全尺寸的YOLOv4-P5并扩展得到了YOLOv4-P6和YOLOv4-P7。其对应的网络结构示意图见下图。
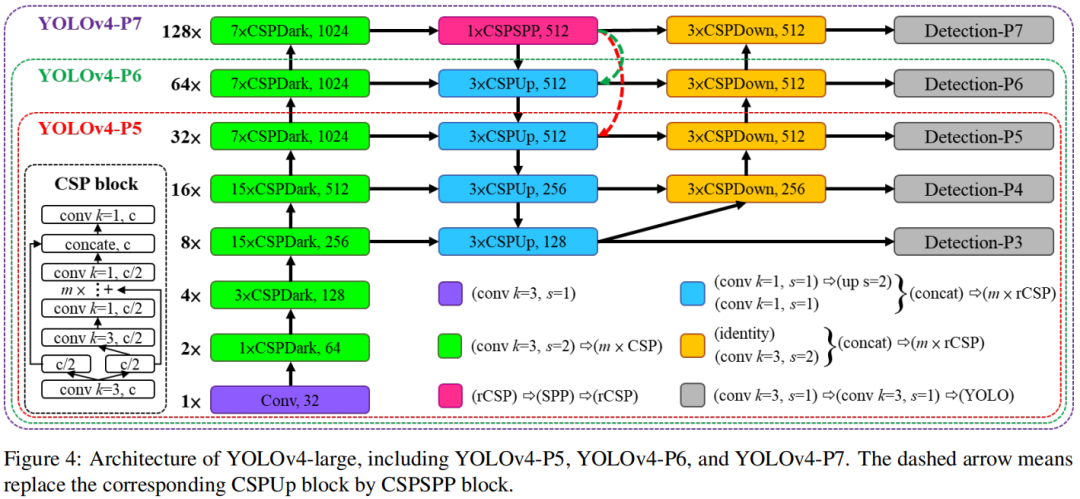
作者通过实验发现:YOLOv4-P6(宽度缩放因子1)可以达到30fps的实时处理性能;YOLOv4-P7(宽度缩放因子1.25)可以达到15fps的处理速度。
Experiments
作者在MSCOCO-2017数据集上验证了所提Scaled-YOLOv4的性能,作者提到并未采用ImageNet进行预训练,所有YOLOv4模型均从头开始训练。YOLOv4-tiny的训练了600epoch;YOLOv4CSP训练了300epoch;YOLOv4-large先训练了300epoch,然后采用更强的数据增广技术训练了150epoch。其他训练相关的超参作者采用k-mean与遗传算法决定。
Ablation study on CSP-ized model
作者首先针对CSP-ized模型进行了消融实验分析,结果见下表。作者从参数量、计算量、处理流程以及平均精度方面进行了CSP-ization的影响性分析。作者采用Darknet53作为骨干网络,选择FPN+SPP与PAN+SPP作为neck进行消融分析。作者同时还采用了LeakyReLU与Mish进行对比分析。
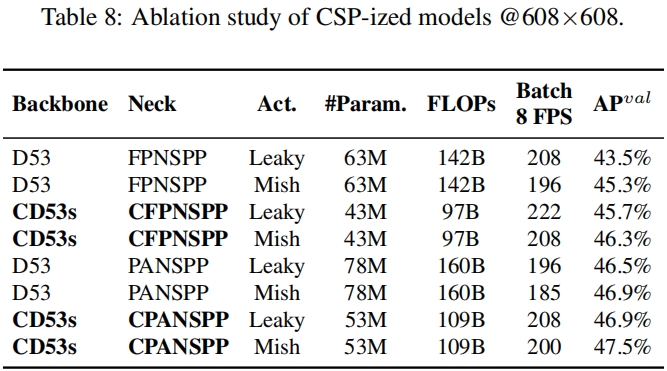
从上表可以看到:CSP-ized模型可以极大的降低参数量与计算量达32%,同时带来性能上的提升;同时还可以看到:CD53s-CFPNSPP-Mish、CD53s-CPANSPP-Leaky与D53-FPNSPP-Leaky相同的推理速度,但具有更高的指标(分别搞1%和1.6%AP),且具有更低的计算量。
Ablation study on YOLOv4-tiny
接下来,我们将通过实验来证实:CSPNet+partial的灵活性。作者将其与CSP-Darknet53进行了对比,结果见下表。
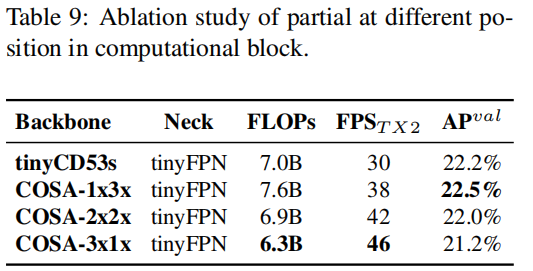
从上表可以看到:所设计的PCB技术可以使模型更具灵活性,因为它可以更具实际需要进行结构调整。同时也证实:线性缩放方式的局限性。作者最终选择COSA-2x2x作为YOLOv4-tiny,因其取得最佳的精度-速度均衡。
Scaled-YOLOv4 for object detection
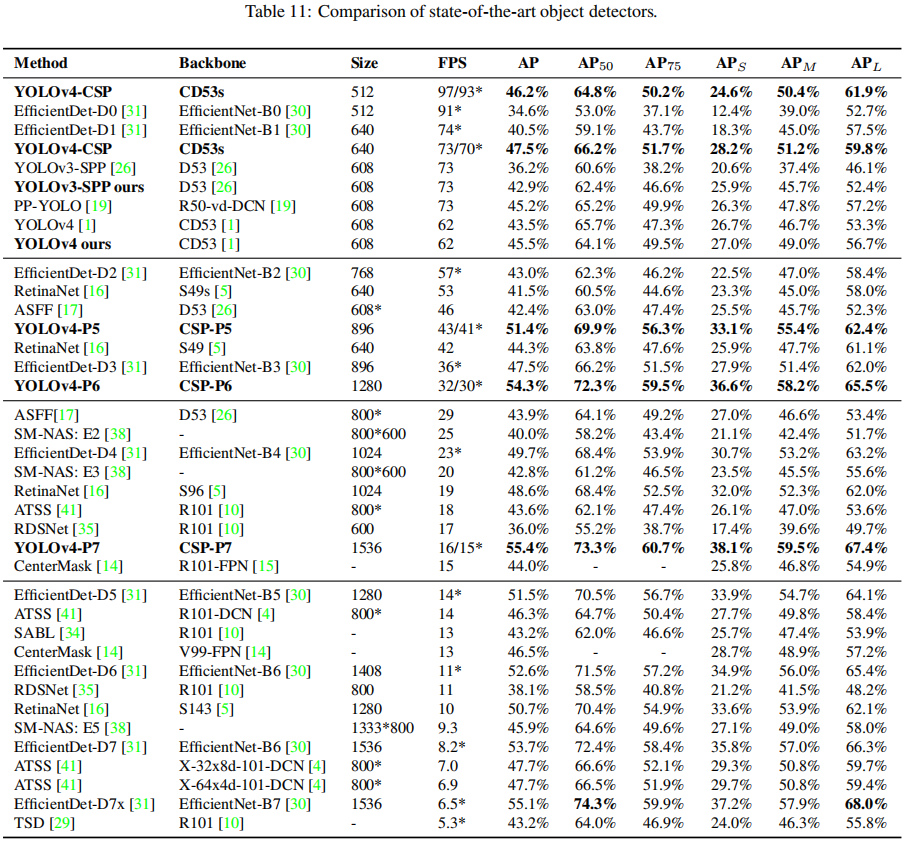
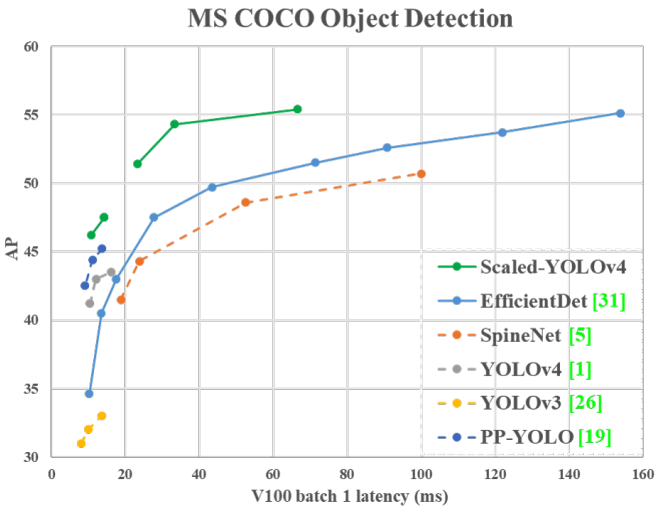
上图给出了本文所提Scaled-YOLOv4与其他SOTA目标检测方法的对比,可以看到:所提方法在不同约束下均取得了最佳的均衡。比如,YOLOv4-CSP与EfficientDet-D3具有相同的精度,但具有更开的推理速度(1.9倍);YOLOv4-P5与EfficientDet-D5具有相同的精度,推理速度则快2.9倍。类似现象可见:YOLOv4-P6 vs EfficientDet-D7, YOLOv4-P7 vs EfficientDet-D7x。更重要的是:所有Scaled-YOLOv4均达到了SOTA结果。
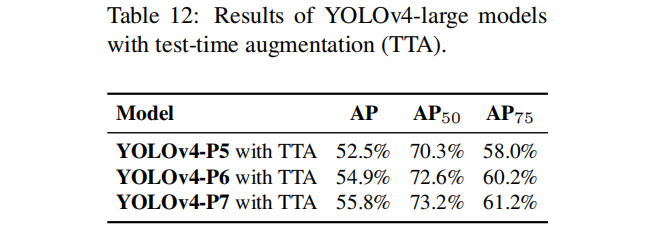
与此同时,作者还给出了添加TTA后的YOLOv4-large性能,可以看到分别可以得到1.1%,0.6%与0.4%AP的指标提升。
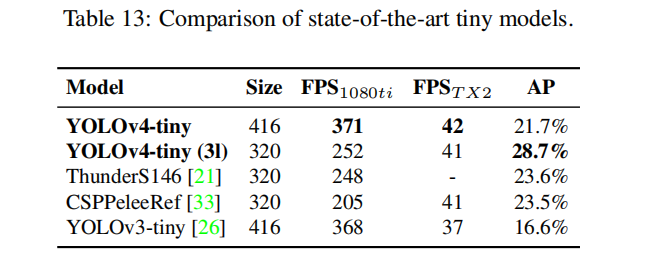
作者还对比了YOLOv4-tiny与其他tiny目标检测器的性能对比,见下表。可以看到:YOLOv4-tiny取得了最佳的性能。
最后,作者在不同的嵌入式GPU上测试了YOLOv4-tiny的性能,见下图。可以看到:无论哪种硬件平台下,YOLOv4-tiny均可以达到实时性。经过TensorRT FP16优化后的YOLOv40tiny最高可以达到1774fps的推理速度。

YOLO系列相关文章
推荐阅读






