腾讯优图:带噪学习和协作学习,不完美场景下的神经网络优化策略
机器之心发布
机器之心编辑部
在 机器之心 CVPR 2020 线上分享第三期,腾讯优图实验室高级研究员 Louis为我们分享了论文《带噪学习和协作学习:不完美场景下的神经网络优化策略》,本文是对此次分享的回顾与总结。
神经网络的成功建立在大量的干净数据和很深的网络模型基础上。但是在现实场景中数据和模型往往不会特别理想,比如数据层面有误标记的情况,像小狗被标注成狼,而且实际的业务场景讲究时效性,神经网络的层数不能特别深。



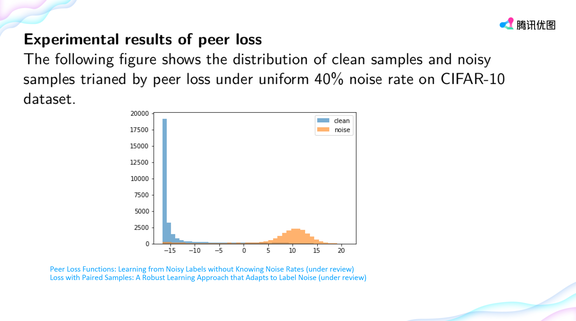
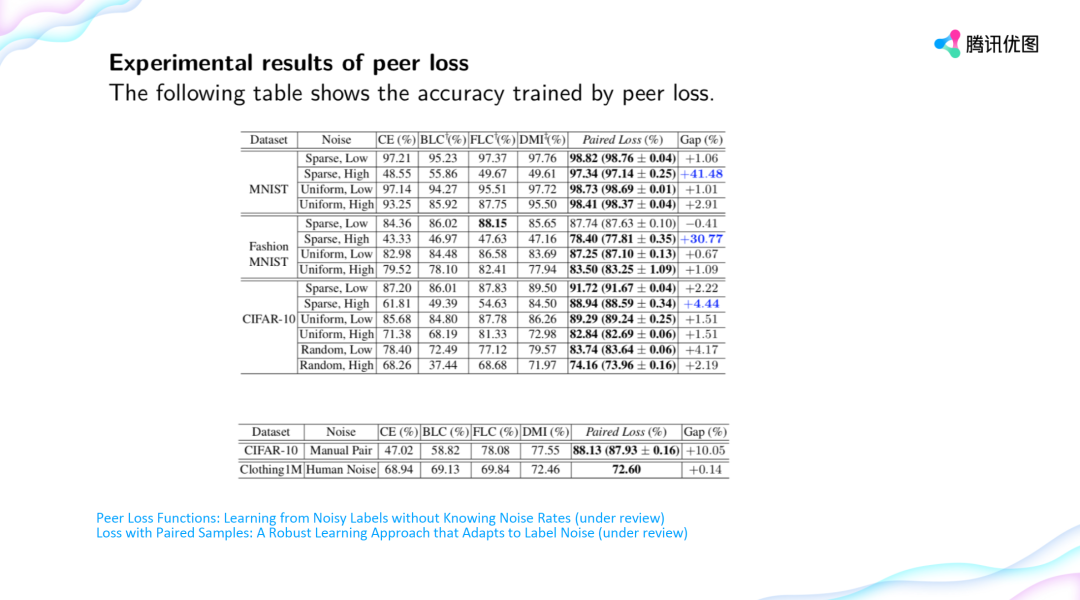
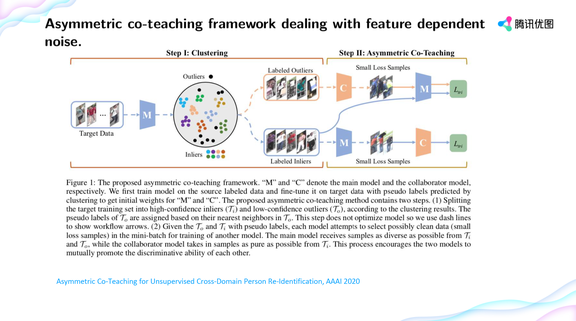

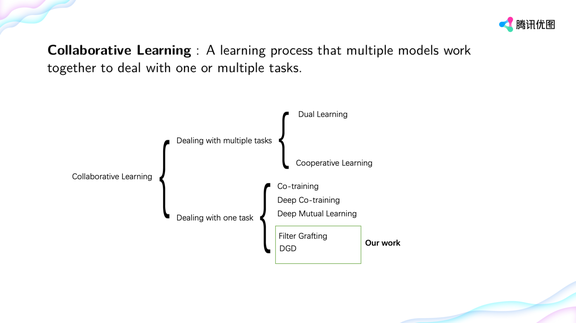
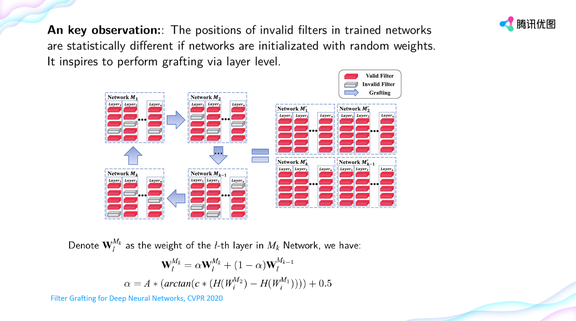
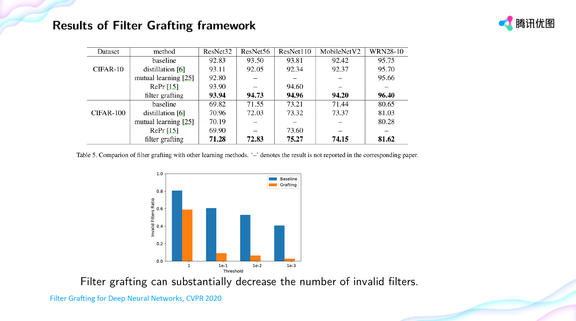
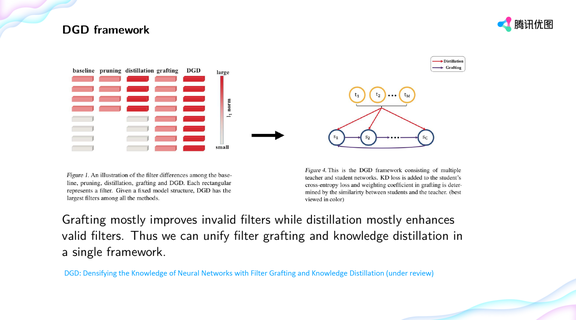
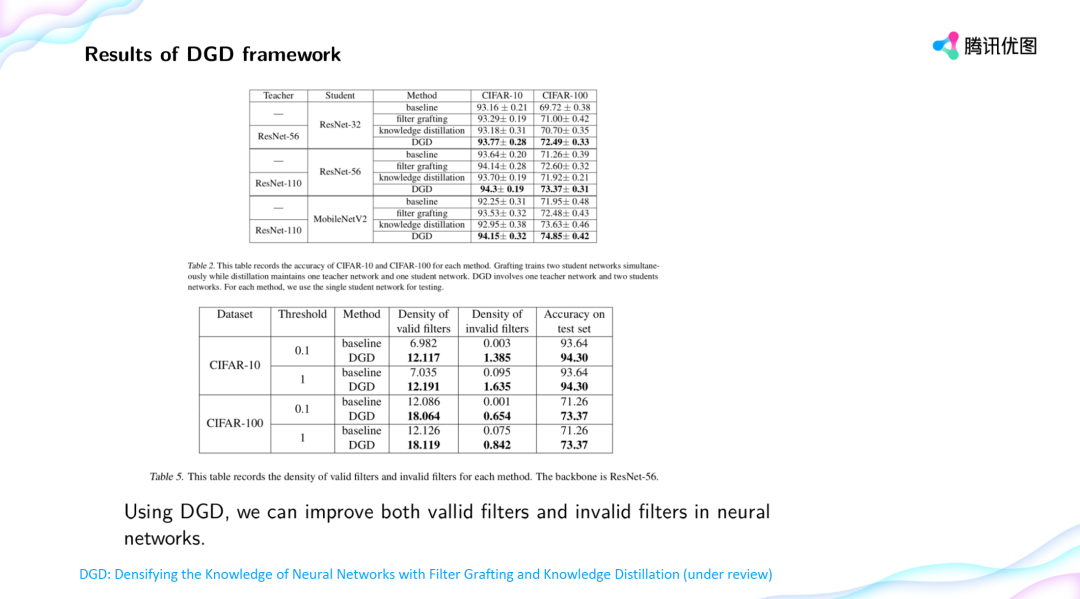
登录查看更多
相关内容

专知会员服务
54+阅读 · 2020年3月5日




相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文