资源 | 从变分边界到进化策略,一文读懂机器学习变换技巧
选自inFERENCe
作者:Ferenc Huszár
机器之心编译
参与:路雪、黄小天
本文作者 Ferenc Huszár 是一名机器学习研究者,在剑桥取得博士学位,对概率推断、生成模型、无监督学习和应用深度学习解决问题感兴趣。本文总结了他关于机器学习变换式的技巧,机器之心对此进行编译介绍。
本文分享的是我的笔记,旨在帮助大家获得更好的理解。这是一本关于各种「变换式」的手册,将这些变换用于机器学习问题,并最终使其转为已知解决方案的问题:寻找一个易处理向量场的稳定吸引子。
典型设置为:你有一些模型参数θ。你想优化一些客观标准,但是使用下面列出的方式解决优化问题比较困难。如果可以的话,你可以对问题进行相应的变换处理。之后,如果问题得到了高效优化,非常棒。如果没有,你可以递归地使用该「变换」,直到解决该问题。
你可以将其作为一种编译器,将抽象的机器学习问题编译成寻找易处理向量场中稳定吸引子的典型问题。
那么,我先来介绍以下这些问题的变换:
变分边界(variational bound)
对抗博弈(Adversarial game)
进化策略(Evolution Strategy)
凸松弛法(convex relaxation)
变分边界
典型问题
我的损失函数 f(θ) 很难计算,主要是由于它涉及到难以解决的边缘化(marginalization),我无法评估它,除了将其最小化。
解决方案
让我们构建一组通常可微分的上边界:
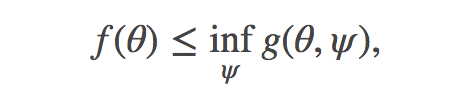
并解决优化问题
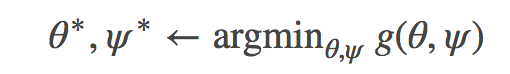
严格讲,一但优化结束,你可以摈弃辅助参数ψ∗ - 尽管结果经常证明其本身是有意义和有用的,尤其是对于近似推理,比如 VAE 识别模型。
变换技巧
詹森不等式(Jensen's inequality):凸函数的平均值永远不会低于平均值的凸函数取值。一般出现在下面的标准证据下界(standard evidence lower bound/ELBO)推导的一些变体之中:
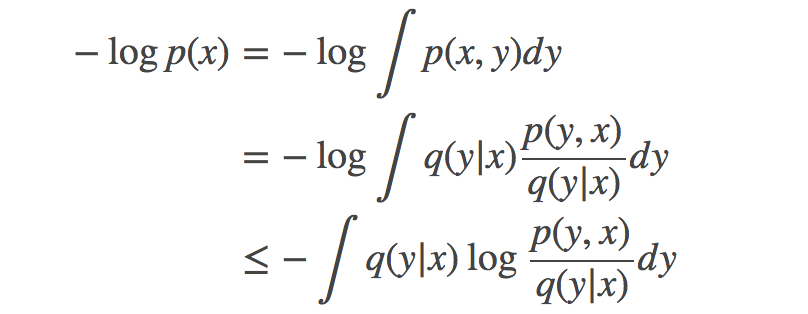
再参数化技巧:在变分推理中我们经常遇到这种形式的梯度:
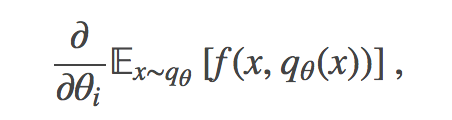
其中变量的 pdf 出现在被积函数中。如果我们可以找到有关其第二个参数的可微分函数 h:(E,Θ)↦X,和易于采样的 pϵ 对 E 的概率分布,下式则会成立:
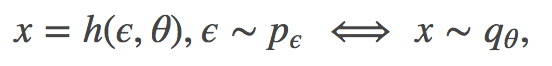
我们可以使用以下在变分上边界经常遇到的积分重构。
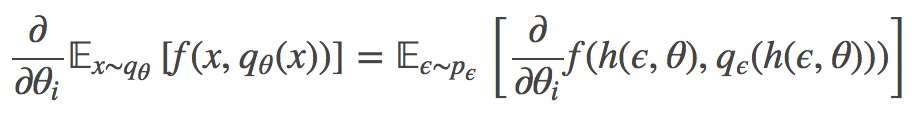
对于这个期望的蒙特卡罗估计量通常比 REINFORCE 估计量的相同数量具有明显更低的方差。
对抗性博弈
典型问题
我无法根据样本直接估计损失函数 f(θ),原因通常在于损失函数依赖于数据分布或模型,或二者皆有。
解决方案
我们可以构建一个近似,使
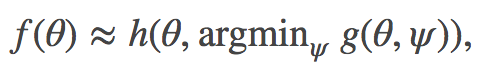
然后就可以解决在双人博弈中找到稳定均衡的问题,博弈中双方分别最小化与 ψ 有关的损失函数 g 和与 θ 有关的损失函数 h。
有时,近似可能是下界的形式,其中 h=−g:
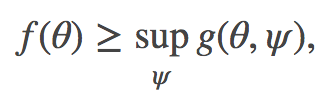
这种情况下,我们可以转而解决以下最小最大问题:
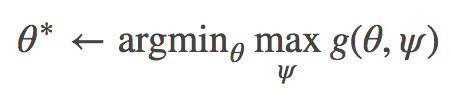
变换技巧
辅助任务中的贝叶斯优化:如果损失函数依赖于可从中轻松采样的概率分布的密度,通常你可以构建一个辅助任务,其贝叶斯优化解决方案依赖于密度的值。辅助任务示例:似然比估计的二分类、去噪,或评估评分函数的分数匹配。
凸共役性(Convex conjugate):损失函数包含密度的凸函数(如 f 散度),你可以通过用凸共役性的形式重新表述来变换你的问题。f 关于其凸共役性 f∗ 的表达式为:
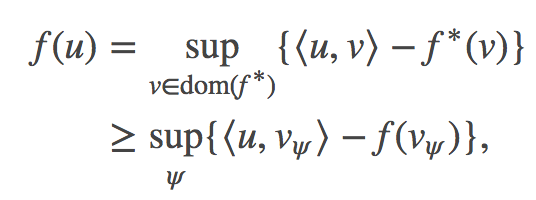
注意:u 是密度函数,内积 ⟨u,v_ψ⟩ 是 v_ψ 的期望值,可以近似到蒙特卡罗采样。
进化策略
典型问题
我的 f(θ) 易于评估但难以优化,可能是因为包含了离散运算,或者该函数是分段常值函数,无法使用反向传播。
解决方案
观察任意概率 pψ 在 θ 上的结果:
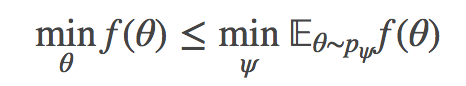
因此,在进化策略中,我们将优化问题简化为:
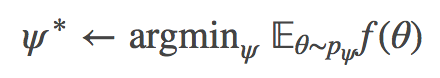
通常,根据函数 f 和分布 pψ 的类别,f 的局部最小值可以从 ψ 的局部最小值中恢复。
变换技巧
强化梯度估计量:它依赖以下技巧
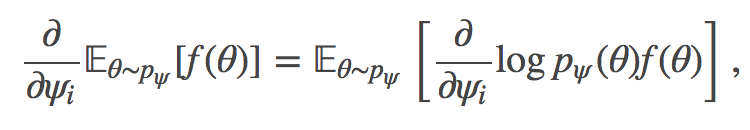
其中 RHS 可以轻松近似蒙特卡罗。蒙特卡罗强化估计量的方差一般比较高。
凸松弛法
典型问题
我的 f(θ) 很难优化,因为它具备不可微和非凸成分,如 ℓ_0(稀疏方法中的向量范数)或分类中的赫维赛德阶跃函数(Heaviside step function)。
解决方案
用凸逼近替换非凸组件,将目标变换成典型的凸函数 g。
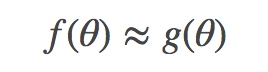
变换技巧
ℓ_1 损失函数:在很多稀疏学习情况下,我们希望最小化向量中非零项的数量,叫作 ℓ_0 损失函数。你可以用该向量的 ℓ_1 范数替换 ℓ_0 损失函数。
折叶损失函数(hinge loss)和大间隔方法:二值分类器在 0-1 损失函数下的错误率,其目标通常是分类器参数的分段常值函数(piecewise constant function),很难优化。我们可以用折叶损失替代 0-1 损失,可以理解为一个凸上界。然后,优化问题很可能最大化分类器的间隔。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




