深入机器学习系列之:高斯混合模型


数据猿导读
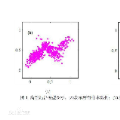
现有的高斯模型有单高斯模型(SGM)和高斯混合模型(GMM)两种。从几何上讲,单高斯分布模型在二维空间上近似于椭圆,在三维空间上近似于椭球。 在很多情况下,属于同一类别的样本点并不满足“椭圆”分布的特性,所以我们需要引入混合高斯模型来解决这种情况。

来源:星环科技丨作者:endymecy
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

单高斯模型
多维变量X服从高斯分布时,它的概率密度函数PDF定义如下:
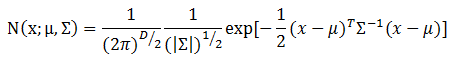
在上述定义中,x是维数为D的样本向量,mu是模型期望,sigma是模型协方差。对于单高斯模型,可以明确训练样本是否属于该高斯模型,所以我们经常将mu用训练样本的均值代替,将sigma用训练样本的协方差代替。 假设训练样本属于类别C,那么上面的定义可以修改为下面的形式:
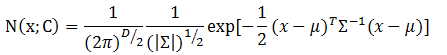
这个公式表示样本属于类别C的概率。我们可以根据定义的概率阈值来判断样本是否属于某个类别。
2
高斯混合模型
高斯混合模型,顾名思义,就是数据可以看作是从多个高斯分布中生成出来的。从中心极限定理可以看出,高斯分布这个假设其实是比较合理的。 为什么我们要假设数据是由若干个高斯分布组合而成的,而不假设是其他分布呢?实际上不管是什么分布,只K取得足够大,这个XX Mixture Model就会变得足够复杂,就可以用来逼近任意连续的概率密度分布。只是因为高斯函数具有良好的计算性能,所GMM被广泛地应用。
每个GMM由K个高斯分布组成,每个高斯分布称为一个组件(Component),这些组件线性加成在一起就组成了GMM的概率密度函数:
根据上面的式子,如果我们要从GMM分布中随机地取一个点,需要两步:
随机地在这K个组件之中选一个,每个组件被选中的概率实际上就是它的系数pi_k;
选中了组件之后,再单独地考虑从这个组件的分布中选取一个点。
怎样用GMM来做聚类呢?其实很简单,现在我们有了数据,假定它们是由GMM生成出来的,那么我们只要根据数据推出GMM的概率分布来就可以了,然后GMM的K个组件实际上就对应了K个聚类了。 在已知概率密度函数的情况下,要估计其中的参数的过程被称作“参数估计”。
我们可以利用最大似然估计来确定这些参数,GMM的似然函数如下:
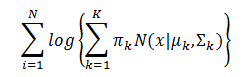
可以用EM算法来求解这些参数。EM算法求解的过程如下:
E-步。求数据点由各个组件生成的概率(并不是每个组件被选中的概率)。对于每个数据$x_{i}$来说,它由第k个组件生成的概率为公式:
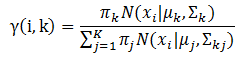
在上面的概率公式中,我们假定mu和sigma均是已知的,它们的值来自于初始化值或者上一次迭代。
M-步。估计每个组件的参数。由于每个组件都是一个标准的高斯分布,可以很容易分布求出最大似然所对应的参数值,分别如下公式:
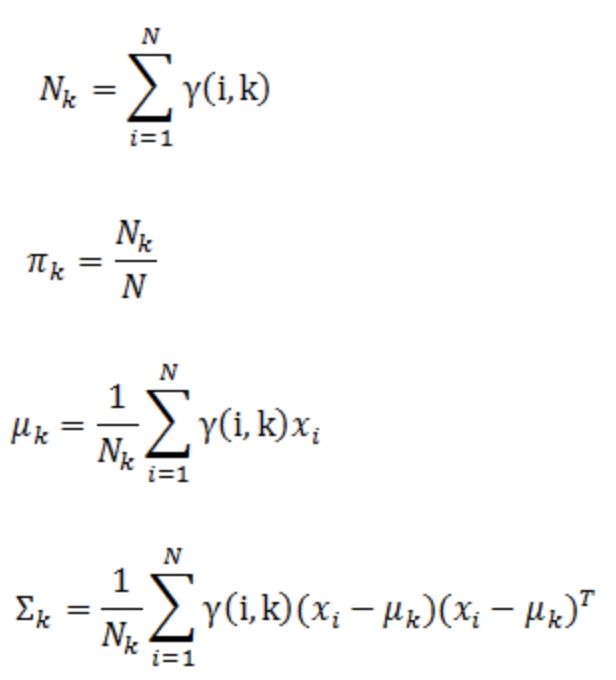
3
源码分析
(代码块部分可以左右滑动查看哦)
3.1 实例
在分析源码前,我们还是先看看高斯混合模型如何使用。
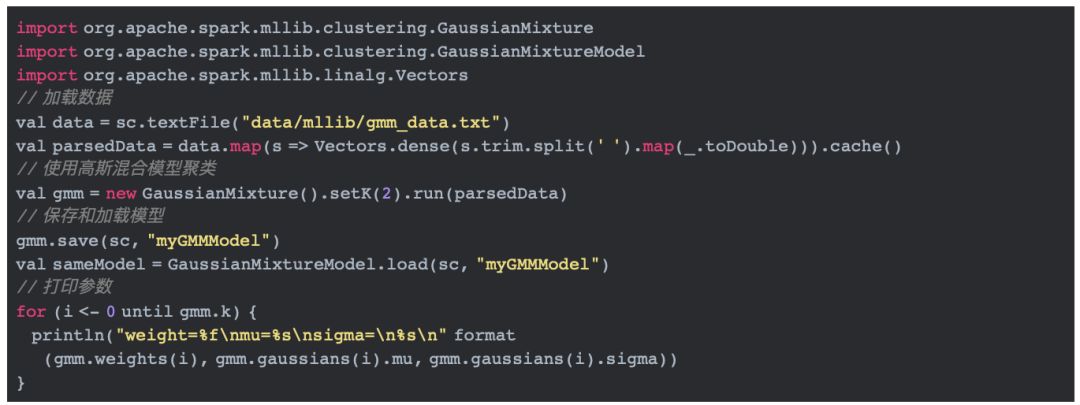
由上面的代码我们可以知道,使用高斯混合模型聚类使用到了GaussianMixture类中的run方法。下面我们直接进入run方法,分析它的实现。
3.2 高斯混合模型的实现
3.2.1 初始化
在run方法中,程序所做的第一步就是初始化权重(上文中介绍的pi)及其相对应的高斯分布。
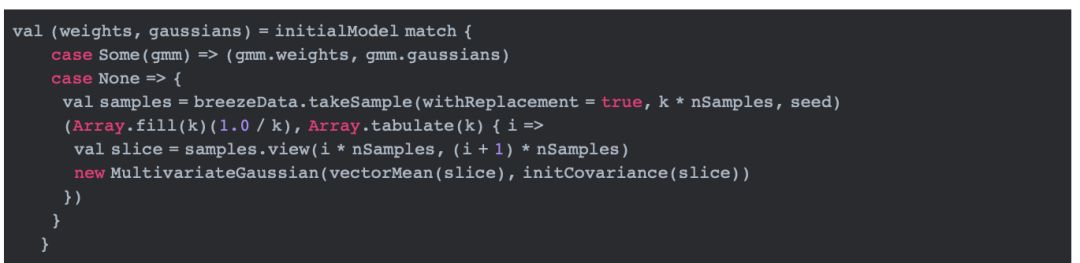
在上面的代码中,当initialModel为空时,用所有值均为1.0/k的数组初始化权重,用值为MultivariateGaussian对象的数组初始化所有的高斯分布(即上文中提到的组件)。 每一个MultivariateGaussian对象都由从数据集中抽样的子集计算而来。这里用样本数据的均值和方差初始化MultivariateGaussian的mu和sigma。

3.2.2 EM算法求参数
初始化后,就可以使用EM算法迭代求似然函数中的参数。迭代结束的条件是迭代次数达到了我们设置的次数或者两次迭代计算的对数似然值之差小于阈值。

在迭代内部,就可以按照E-步和M-步来更新参数了。
E-步:更新参数gamma

我们先要了解ExpectationSum以及add方法的实现。

ExpectationSum是一个聚合类,它表示部分期望结果:主要包含对数似然值,权重值(第二章中介绍的pi),均值,方差。add方法的实现如下:
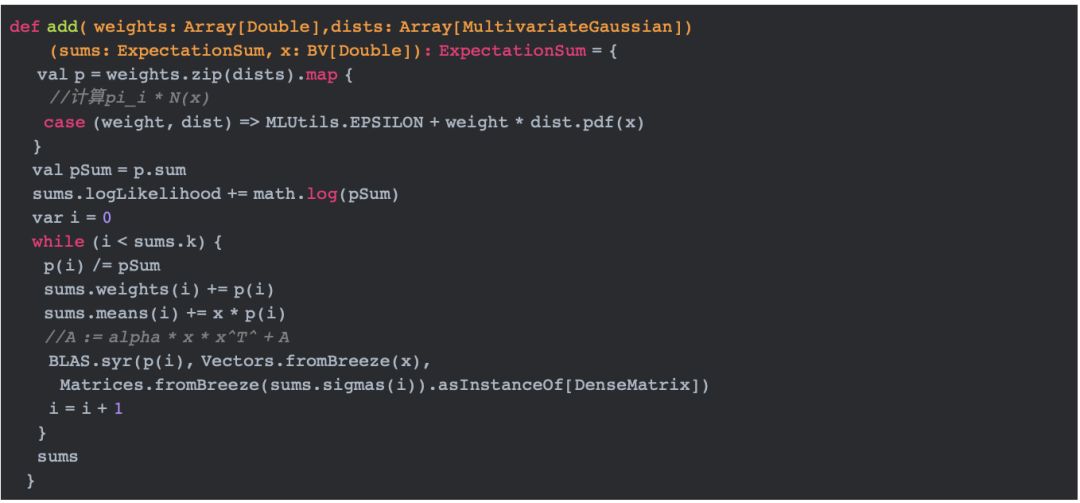
从上面的实现我们可以看出,最终,logLikelihood表示公式(2)中的对数似然。p和weights分别表示公式(3)中的gamma和pi,means表示公式(6)中的求和部分,sigmas表示公式(7)中的求和部分。
调用RDD的aggregate方法,我们可以基于所有给定数据计算上面的值。利用计算的这些新值,我们可以在M-步中更新mu和sigma。
M-步:更新参数mu和sigma
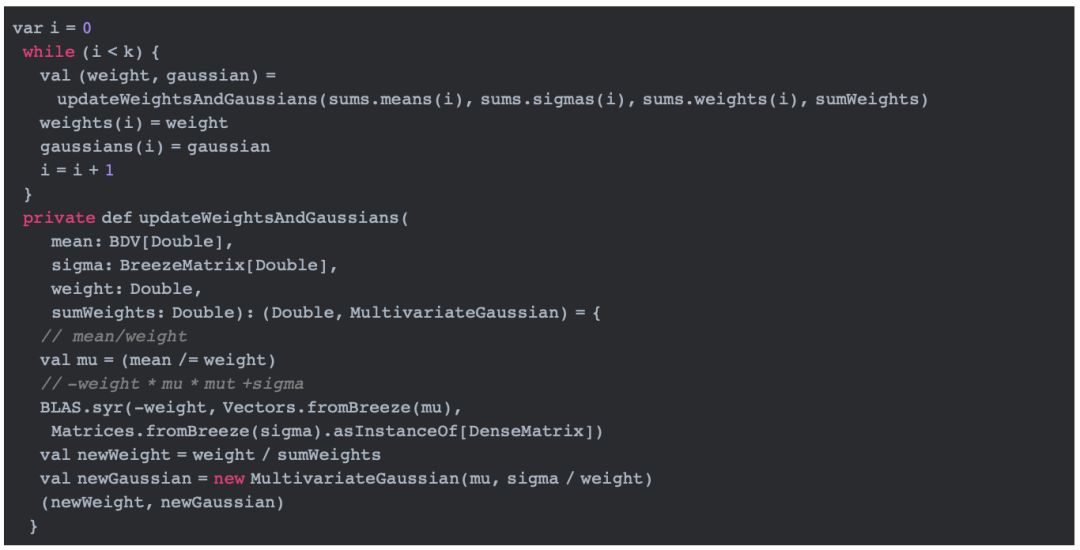
基于E-步计算出来的值,根据公式**(6),我们可以通过(mean /= weight)来更新mu;根据公式(7),我们可以通过BLAS.syr()来更新sigma;同时,根据公式(5), 我们可以通过weight / sumWeights来计算pi。
迭代执行以上的E-步和M-步,到达一定的迭代数或者对数似然值变化较小后,我们停止迭代。这时就可以获得聚类后的参数了。
3.3 多元高斯模型中相关方法介绍
在上面的求参代码中,我们用到了MultivariateGaussian以及MultivariateGaussian中的部分方法,如pdf。MultivariateGaussian定义如下:

MultivariateGaussian包含一个向量mu和一个矩阵sigma,分别表示期望和协方差。MultivariateGaussian最重要的方法是pdf,顾名思义就是计算给定数据的概率密度函数。它的实现如下:

上面的rootSigmaInv和u通过方法calculateCovarianceConstants计算。这个概率密度函数的计算需要计算sigma的行列式以及逆。

这里,U和D是奇异值分解得到的子矩阵。calculateCovarianceConstants具体的实现代码如下:

上面的代码中,eigSym用于分解sigma矩阵。