算法周报: 再思考PDN和DC-GNN
对PDN再思索
这篇文章也不算新了,今天列在这里,是把我的疑问列出来,供大家讨论。
其实这篇文章的思路是非常简单的:
-
i2i召回,是各个推荐系统里面的常见召回方式。最基本的,把用户点击序列扔进word2vec,得到各item embedding,再扔进faiss建立索引。 -
但是线上召回的时候,其实是u->i->i的召回方式,需要针对每个来的用户,选择一些item当trigger -
之前,选择trigger的方式都是非常heuristic,都是规则性的。比如,选择 那些完成度高的、选择那些用户最近才刚刚交互过的。总之,我们可以给这些tirgger一个分数 TriggerRelevance,表示trigger对user的重要性、相关性。 -
再用选择出来的trigger,在faiss中查询与之相近的其他item。用 ItemSimilarity衡量trigger与candidate item之间的相似性。 -
最后召回一堆item,用 S=TriggerRelevance * ItemSimilarity排序,选出Top K作为本路i2i召回的结果返回。以上就是我们的常规操作。
PDN不过是将以上简单的常规操作,用一个复杂的模型来代替
-
u->i->i的过程,起了个新名字,叫一条path
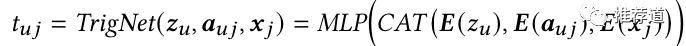
-
u->i的过程,叫trigger net -
喂入用户特征 ,行为序列中某个交互过的item的特征 -
就是衡量trigger "j"对user 'u'的重要性。 -
以前,我们不用模型,直接拿“item j的完成度”、“交互item j时的距今时间”等信息,拍个脑袋写个规则,就能够得到
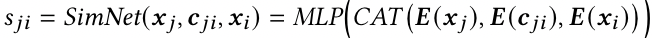
-
i->i,现在叫SimNet -
把history item(trigger) 和candidate item 喂入一个模型,得到 表示trigger与candidate item之间的相似度。 -
之前,我们不用模型,得到item embedding之后,直接点积就得到 了。
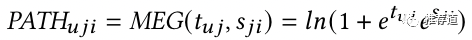
-
最终得分也一样是 TriggerRelevance和ItemSimilarity的综合
那么将我们原来驾轻就熟的“规则+点积”用现在复杂的“trigger net+sim net”代替,优点在哪里呢?是因为我们之前计算TriggerRelevance时,太拍脑袋了,现在用了一个NN就显得智能了吗?可能是吧。只不过,我之前评论Airbnb根据side info对user/item进行人工分组,远不如阿里EGES把side info喂入模型高明。后果,当我对DNN的崇拜破灭之后,才发现Airbnb手工注入先验知识的方法也有高明之处。
-
现在我唯一能找出来的“PDN做得如此复杂”的理由就是: 两阶段的一致性。 -
如果业务需要有非常复杂的多目标,PDN可以调教TriggerNet和SimNet,都朝着那复杂的、不只一个的多目标努力。 -
而且因为end-to-end,TriggerNet和SimNet可以相互配合,哪些可以牺牲一些 TriggerRelevance,哪些可以牺牲一些ItemSimilarity,只要最终的TriggerRelevance * ItemSimilarity高就行。 -
比如,之前用word2vec训练出来的item embedding,和最终业务目标相差甚远。 -
TriggerNet和SimNet,是end-to-end训练出来的。
DC-GNN: Decoupled Graph Neural Networks for Improving and Accelerating Large-Scale E-commerce Retrieval
2022年阿里新文。
整个模型结构还是双塔模型。但是普通双塔模型中,没能像GNN那样融入多跳的邻居信息,因此采取的办法是,将GNN预训练好的embedding喂入双塔。
“预训练好embedding”和“喂入双塔”,分别对应论文中的Pre-training和Deep Aggregation两个阶段。按论文里的说法:
-
Pre-training只是学到了各node(e.g., query, user, ad)的attribute -
Deep Aggregation,才用graph structure来 增强预训练得到的node embedding
我是不认同这种说法的,看了论文,在第一步pre-training时,也没有看到使用query/user/ad的各种side info(比如用户、物料画像等),所以第1步pre-training得到的node embedding也是基于structure学习来的。所以只能说,对用普通GNN学习到的node embedding不满意,在接入双塔之前,又用GNN重新加强了一遍。
第一步,预训练
第一步就是“不太普通”的GNN上做link prediction。看完,有三个问题:
第1个问题。看论文,是一个由query, user, ad三类节点构建成的异构图。但是query是什么?单词吗?预训练user/item我能理解,因为今后能够复用的上?但是我理解query不应该是用户输入的句子吗?那东西能复用吗?不能复用的话,预训练它干嘛?
第2个问题。每个node使用了哪些特征?看论文里没写,我猜没有side info,只用了user id/ad id,或者query id(???什么鬼???)。即便这样,起码要用一个node type吧,让模型好歹知道每个节点对应的是query, user还是ad。
第3个问题,每个node上的embedding是怎么来的?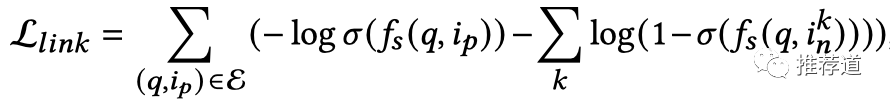
-
怎么得到各node embedding?原始特征是什么?信息如何传递? -
是像传统方法那样, 我的邻居的邻居,先传递给我的邻居,再由我的邻居传递给我 -
还是让后边Deep Aggregation那样, 我的邻居的邻居,直接传递给我;我的邻居,也直接传递给我 -
这可是在一个由三类节点(query, user, ad)组成异构图上,不同节点之间存在不同的边。 怎么处理这种异构性,我的不同类型的邻居,沿着不同类型的边,向我传递过来的信息,让我一视同仁吗?
以上问题,论文里都没有细说,找不到是怎么做的。
第二步,Deep Aggregation
第一步预训练出来的各query embedding, user embedding, ad embedding直接喂入双塔?不行,DC-GNN说里面的structure信息不够,还要再加强。
怎么加强?再上一遍GNN,把节点X的1/2/3阶的邻居信息再向X聚合一遍。但是,如果像传统GNN那样,渐进式的消息传递(e.g., 我的邻居的邻居,先传递给我的邻居,再由我的邻居传递给我),效率太低,速度太慢。
所以,DC-GNN打破中间商,让我的1/2/3阶矩阵直接向消息传递给我,也就是论文里所谓的linear fussion。
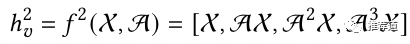
-
X是第1步预训练得到的各node embedding -
A是节点间的邻接矩阵, 和 分别是一个节点的2阶、3阶邻居的邻接矩阵 -
把 4个子向量拼接起来,作为一个node embedding,喂入双塔
看起来蛮好的,但是别忘了,这是在一个三类节点的异构图上。论文里的文字说得不清不楚,图也画得有误导性。
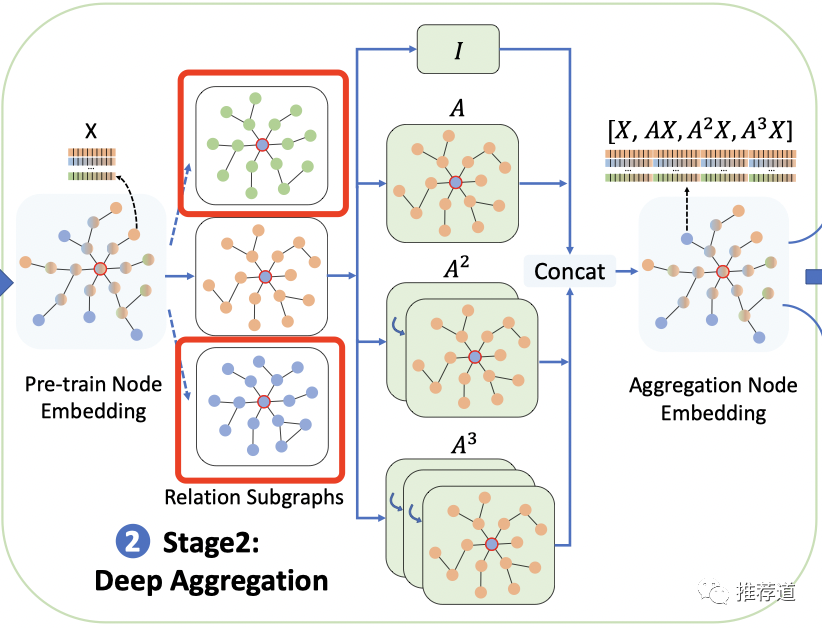
中间所谓的relation subgraph,是将一个节点的邻居分成query neighbor, user neighbor, ad neighbor,再延展出来的子图。看上图,只有中间一类邻居,通过 进行了deep aggregation,那其他两类邻居怎么办?
所以,真实情况是什么?
-
是每类邻居,都通过 deep aggregation一遍? -
然后三类邻居的deep aggregation结果再拼接? -
所以最终喂入双塔的是由12个子向量组成的一个超大向量???
第三步,双塔
本来没啥可说的,但是看到论文里有这么一句话,"We use (query,user)ad clicked results as the positives, and the results impressed but not clicked as negatives".
啥?一个召回,拿曝光未点击做负样本??????
当前,召回时拿随机负采样做负样本,都已经成为了业界常识,甚至挖掘负样本,都已经成为了业界研究热点。唉,我真是无语了。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
SIGIR2022 | 基于Prompt的用户自选公平性推荐算法
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

