再见Attention: 建模用户长期兴趣的新范式
本文基于美团2022年的新论文《Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction》有感而发。结合阿里之前ETA的工作,我感到在用户长行为序列建模这一领域,SimHash有望取代Attention,成为新的主力建模工具。本文通过梳理长行为序列建模的发展脉络,对比阿里ETA与美团的SDIM在利用SimHash时的异同,帮助读者快速了解这个建模用户长期序列的新范式。
建模用户长期行为序列的发展脉络
DIN
众所周知,用户行为序列是最能反映用户兴趣的信息来源。以前对用户行为序列,只是简单Pooling。阿里的Deep Interest Network开创性地通过target item对user historical sequence做attention,实现了用户兴趣的“千物千面”,也拉开了研究“如何从用户行为序列中更有效提取用户兴趣”的序幕。
DIN的成功,自然而然地让人联想到,能不能扩大喂入Attention的行为序列的长度,包含更远的用户历史行为?这个想法是非常具有吸引力的:
-
一来,近期、短期的用户行为,可能源自临时起意,需要有更多的历史行为来矫正这些噪声; -
二来,只有长期历史,才能反映出用户一些周期性的行为模式。比如在电商场景下,只有将时间轴拉长到月、季度、甚至是年,用户的一些周期性复购行为才能显现出来。
但是简单将DIN套用到长期行为序列上,有一个无法回避的难题,就是计算量太大。对于一个Batch Size=B的user request,用户的行为序列长度为L,其中每个item embedding的大小是d,target attention的时间复杂度是O(BLd)。如果L达到了千或万这个数量级,这个时间开销是在线实时预测所不能容忍的。
SIM
为了解决target attention耗时太长的问题,阿里又提出了SIM。想法也非常直觉:
-
target attention,是拿target item去衡量每个historical item的重要性。与target item相似的historical item,聚合时的权重就高。这相当于一种“软过滤”。 -
既然软过滤代价太高,就借助离线建立的索引进行“硬过滤”。
SIM是分“两步走”策略:
-
第一步是所谓的GSU(General Search Unit),借助离线建立的索引,拿target item直接从索引中提取与它相似的historical items组成的Sub Behavior Sequence (SBS)。这个过程就对应SIM中的S代表的Search。这个Search过程的时间复杂度是O(log(M))<<O(L),M是一个建立索引时的超参,用来平衡搜索的精度与速度。 -
第二是所谓的ESU(Exact Search Unit),拿target item与GSU返回的SBS做target attention,将SBS压缩成一个向量表示用户的长期兴趣。
至于GSU中要用到的离线索引是如何建立的?
-
可以是SIM hard模式,将同一个用户的user behavior sequence中包含相同category的items集合起来,形成 map<category, itemset>的索引 -
可以是SIM soft模式,拿每个item pre-trained embedding(比如来自粗排)聚类成簇,建立类似FASIS那样的索引
虽然离线索引加快了Search速度,但是也带来了两个“不一致”的问题:
-
目标不一致。GSU建立索引所使用的item embedding是另一个模型pre-trained(比如来自召回或粗排),它所表达的语义未必符合正在训练的精排模型的要求 -
更新频率不一致。大厂的推荐模型都必须能够online learning。但是建立离线索引耗时费力,无法频繁更新。这样一类,精排模型的其他部分都在用最新的数据实时更新,只有GSU部分还在使用过时的索引,成为性能短板。
新趋势:取消离线索引
因为离线索引的以上缺点,最新的发展趋势是取消离线索引,让target item在线直接从user behaivor sequence中找到与自己相似的historical items
-
target item embedding与每个historical item embedding都是最新的,也就没有了更新频率上的gap -
target item embedding与每个historical item embedding都要为精排模型的业务目标负责,也就没有了优化目标上的gap
但是重新走target attention的老路,让target item与每个historical item逐一点积,前面已经说有了,性能上吃不消,那是死路一条。我们只能另辟蹊径,这时SimHash给我们指明了一条新路。
SimHash简介
SimHash是Locality-Sensitive Hashing(LSH)的一种实现,做起来很简单:
-
给定一个随机矩阵 的矩阵,每一行代表一个hash function -
对任意d维的向量x,计算 h(x,R)=sign(Rx),也就是将x映射成m维长的整数向量。因为结果向量的每位只能是0或1,从而h(x,R)可以表示成一个m-bit的整数。h(x,R)可以称为hash signature,或hash fingerprint。
SimHash的优点在于其locality-preserving属性:两个向量 和 ,SimHash后得到 , 。 和 在向量空间中越接近, 和 中相互重合的位数就越多。
这一重要性质,也是SimHash能够被用于Search User Interest的基础保障。
阿里的ETA
阿里2021年发表的《End-to-End User Behavior Retrieval in Click-Through Rate Prediction Model》提出End-to-End Target Attention(ETA),正是利用了SimHash的locality-preserving属性,将其应用于GSU阶段:
-
将target item 'q'经过SimHash,得到m-bit的整数 -
将user behavior sequence "L"中的每个item embedding都经过SimHash,得到 ,每个都是m-bit的整数 -
拿 与每个 计算hamming distance,也就是两个m-bit序列中不相同bit的个数,比如 hamming(11011001, 10011101) = 2 -
选择与 的hamming distance最小的Top-K个historical items作为SBS,交到ESU做target attention。
分析一下ETA的时间复杂度,在线预测时:
-
当一版模型推到线上infer server时,各item embedding也就固定了,每个item embedding的hash signature也就固定了,可以被提前计算好并缓存。平摊下来,这部分SimHash的开销可忽略不计。 -
计算两个m-bit整数的hamming distance可以用XOR来完成,相当于一次原子操作。一个用户的用户行为序列长度为L,他的一次请求中有B个candidate items。所以这个请求中GSU的时间开销为 O(BL)。 -
对每个candidate item,GSU都要筛选出长度为K的SBS,送到ESU去做target attention。这部分的开销是 O(BKd)。 -
所以ETA预测一次请求的时间复杂度为 O(BL+BKd)
美团的SDIM
美团的Sampling-based Deep Interest Modeling(SDIM),沿着ETA的思路,更进一步:
-
target attention的目的是在用户行为序列中找到与target item相似的historical item。而根据SimHash的locality-preserving性质, 如果某个historical item 与target item 'q'很相似,那么q的hash signature 与 的hash signature ,就有很多bits是相互重合的。这也是ETA的理论基础。 -
既然如此, 何不按照hash signature中重合的次序列,来查找与target item相似的historical item? 比如, 的hash signature的从i-th bits到j-th bits组成的子序列 ,与target item的 相同位置上的子序列 完全重合,那么 就是target item 'q'的相似item,就要参与针对q的user interest modeling。
作法
美团的SDIM就是沿着以上思路实现的。首先,把每个historical item embedding先SimHash成m-bit的大的hash signature(比如下图中m=4),再把大的hash signature每隔 个位置分隔成小的hash signature(比如下图中每隔2bits组成黄色和绿色的小方块)。
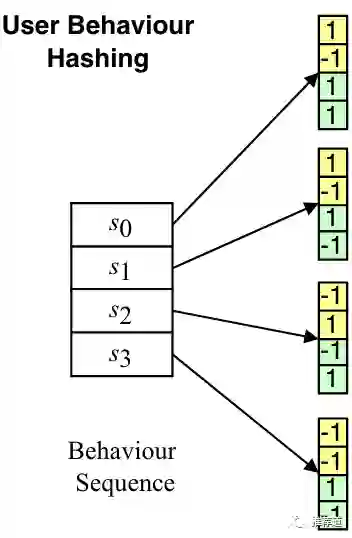
再把相同hash signature的historical item embedding聚合成一个向量。如下图中的
所示,聚合方法就是先按位相加,再做L2-normalization。这样,就把user behavior sequence存储成若干buckets。
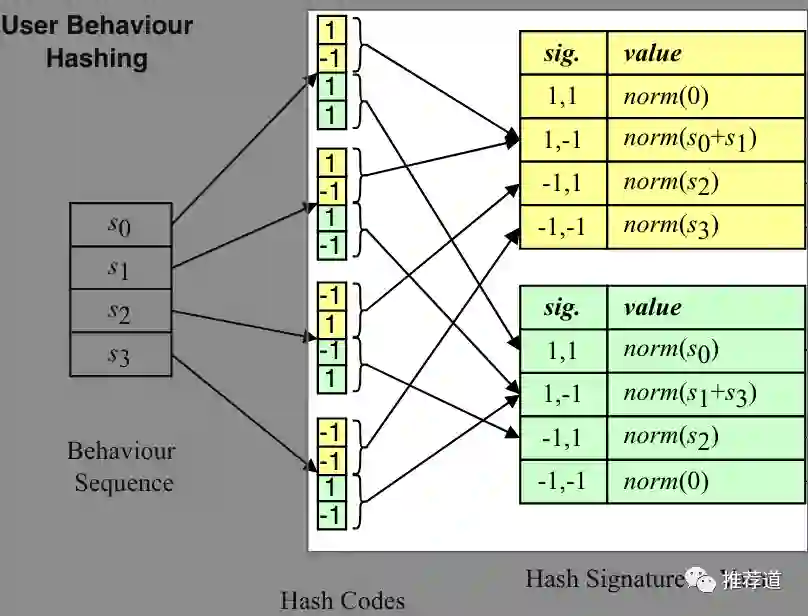
而针对一个target item做target attention时,将target item也先SimHash再拆解成
个hash signature,每个hash signature去上一步得到的buckets提取聚合好的向量。把每个hash signature提取出来的向量再简单pooling一下,就得到了针对这个target item的user interest embedding。

理论依据
以上作法是不是超级简单?但是背后有理论依据吗?美团的大佬们认证指出(我还没有详细看证明过程):由于simhash有一定的随机性,那么target item 'q'与某个historical item '
'的两个hash signature发生碰撞也是一个概率。其中有
个位置重合(i.e., hash collision)的概率,在很大时,趋近于如下公式。
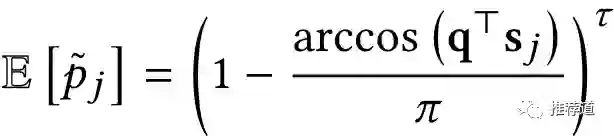
那么historical item 对构建针对target item q的用户兴趣的贡献,如下所示。从形式上看,是不是与target item非常相似,比如都和 点积相关。
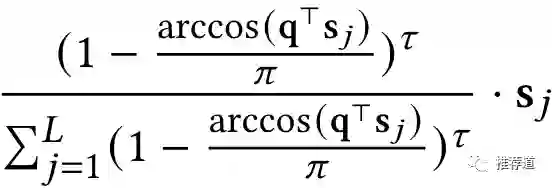
所以美团认为他们的作法就相当于在原始、完整的长期用户行为序列上做target attention,被称为Hash Sampling-based Attention。
部署&性能
DSIM的实时性能肯定是迄今为止最好的。DSIM线上预测时的部署要拆分成两部分:
-
提取用户最新的长期行为序列,把每个historical item embedding先SimHash再拆解成 个hash signature,再把具有相同hash signature的historical item embedding聚合一起,组成buckets。这部分工作单独部署成 Behavior Sequence Encoding (BSE) Server。 -
BSE Server将long-term user behavior sequence压缩成若干buckets,传输给CTR Server。 -
CTR Server中,将每个candidate item embedding也先SimHash再拆解成 个hash signature,再去接收到的buckets提取向量。所有 个hash signature提取完毕后,将提取出来的向量pooling一下,就得到了针对当前candidate item的long-term user interest embedding,再和其他特征一起喂入上边的DNN。
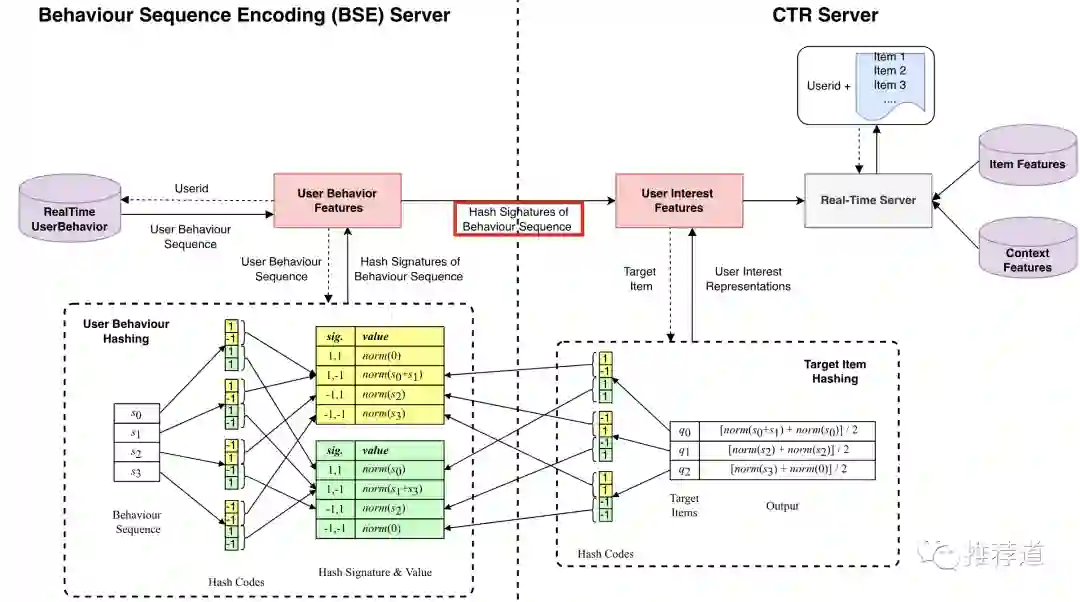
先看BSE Server这边的性能:
-
一个d维的向量,SimHash成m-bit的整数向量,时间复杂度为 O(md)。有近似解法,可以在O(mlog(d))内完成。 -
对于一次用户请求,将该用户L长的用户行为序列做SimHash,耗时 O(Lmlog(d))。而且只需要做一次,也candidate items的多少无关。 -
需要注意的是,当某版本的模型在infer server部署完毕后,每个item embedding也就固定了,每个item embedding的 个hash signature也就固定了。可以缓存起来,无需重复计算。 -
所以BSE的主要工作,就是从缓存里提取每个historical item的hash signature,再分桶,再聚合。 由于计算量大头的SimHash,已经被之前的计算缓存过了,所以BSE的开销是非常小的。 -
而且由于以上工作都与candidate items无关,可以 在进入精排之前提前进行(比如与召回、粗排并发进行),更进一步提高了计算效率。
再看CTR Server这边的性能:
-
CTR server要把batch size=B个candidate items,逐一先SimHash再拆解成 个hash signature。由于同样 可以被缓存,这部分的开销也不大。 -
接下来,就是用hash signature从BSE server发来的buckets中提取向量,再pooling。 也就是一个embedding lookup,开销也不大。
注意与ETA的区别,
-
ETA中,GSU筛选出来的SBS还要再交给ESU做Attention,还要再耗费 O(BKd)的时间 -
美团SDIM这里是一步到位,CTR server从buckets中提取出来的基本上就是attention结果了,而不是SBS。步骤更少,速度更快。
结论
目前来看,美团的DSIM,方法简单,开销又少,效果还最好(反正谁家的论文都这么夸自己),是非常promising和attractive的。
但是,我也还有疑问。比如,m个hash function之间并没有顺序关系,那么拆解成 个hash signature时,为什么是顺序的?为什么是[0,1]和[2,3]组成hash signature,而不能是[0,3]或[1,2]呢?换句话说,为什么要拆解成 个,而不是 个hash signature?
另外,根据我多年的踩坑经验,越是看上去简单的东西,实操起来坑越多。比如,SimHash时如何生成随机矩阵?m和 是多少?恐怕都要反复试错上几个回合,才能调出好效果。
无论如何,阿里的ETA与美团的DSIM,在建模用户长期兴趣这个热点领域,为我们在Attention之外开辟了SimHash这条新路。向我的阿里和美团同行们的探索精神与努力致敬,salute !!!
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

