【论文解读】“推荐系统”加上“图神经网络”
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要5分钟
跟随小博主,每天进步一丢丢


什么是协同过滤?如何用协同过滤做推荐?
NGCF是如何构图的?NGCF在基础的GNN上有哪些改动?如何用NGCF做推荐?
协同过滤
 、物品
、物品
 的交互矩阵
的交互矩阵
 。
。
 、物品的特性
、物品的特性
 ;2. 通过用户的口味、物品的特性去近似交互历史
;3. 给用户
推荐交互得分最高的物品
。
;2. 通过用户的口味、物品的特性去近似交互历史
;3. 给用户
推荐交互得分最高的物品
。
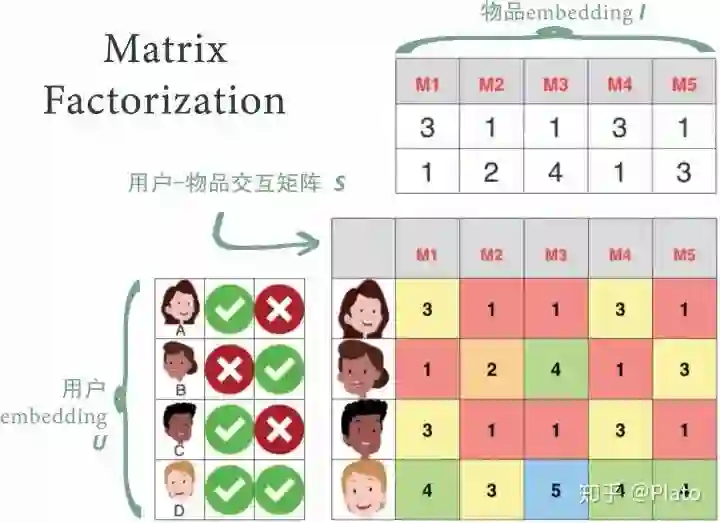
将用户看成矩阵
,物品看做矩阵
,
为embedding长度
使用矩阵的乘积
去近似交互矩阵
,使用梯度下降法最小化
,求解






 。过程如下:
。过程如下:
使用交互历史构图;
在图上,使用GNN学习embedding
;
和MF类似,使用矩阵的乘积
去近似交互矩阵
。
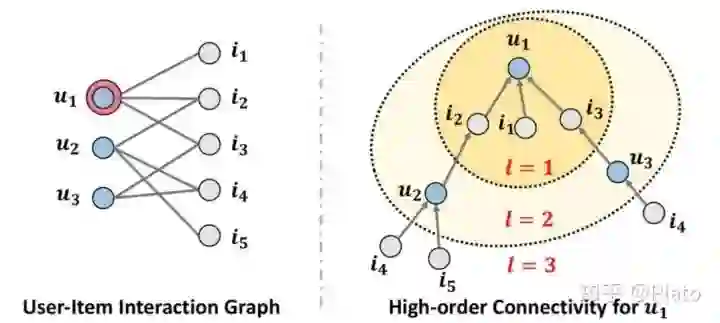
NGCF如何构图?
 展开,获得该点的『高阶历史信息』。
展开,获得该点的『高阶历史信息』。
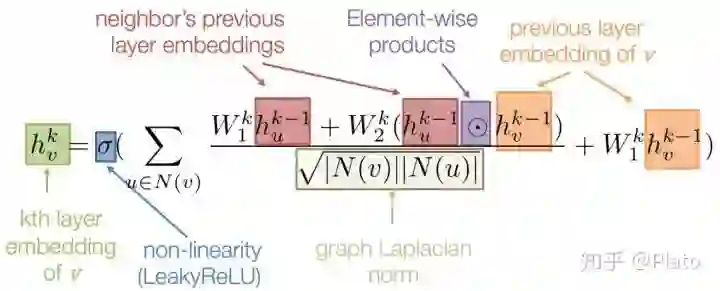
GNN如何获得节点embedding?
 ,获得新一层的
,获得新一层的
 。
。

GNCF的整体网络架构

将每个用户
所有layer的embedding连接起来作为用户最终embedding
将每个物品
所有layer的embedding连接起来作为物品最终embedding
将点积
作为最后的模型预测值
使用了推荐系统常用的pairwise BPR loss,能对正样本和负样本加上不同的权重,使正样本能特别体现用户的口味,负样本能少量体现用户的口味



学到的embedding效果如何?
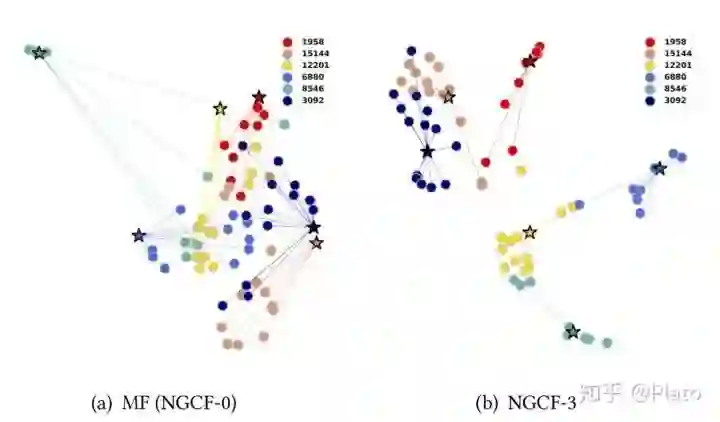
参考
[1] How does Netflix recommend movies? Matrix Factorization https://www.youtube.com/watch?v=ZspR5PZemcs
[2] https://arxiv.org/abs/1905.08108
[3] https://github.com/xiangwang1223/neural_graph_collaborative_filtering


登录查看更多
相关内容

协同过滤(英语:Collaborative Filtering),简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人透过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。协同过滤又可分为评比(rating)或者群体过滤(social filtering)。其后成为电子商务当中很重要的一环,即根据某顾客以往的购买行为以及从具有相似购买行为的顾客群的购买行为去推荐这个顾客其“可能喜欢的品项”,也就是借由社群的喜好提供个人化的信息、商品等的推荐服务。除了推荐之外,近年来也发展出数学运算让系统自动计算喜好的强弱进而去芜存菁使得过滤的内容更有依据,也许不是百分之百完全准确,但由于加入了强弱的评比让这个概念的应用更为广泛,除了电子商务之外尚有信息检索领域、网络个人影音柜、个人书架等的应用等。




相关VIP内容
相关资讯
相关论文