语义相似性算法演化论文,29页pdf,Evolution of Semantic Similarity - A Survey

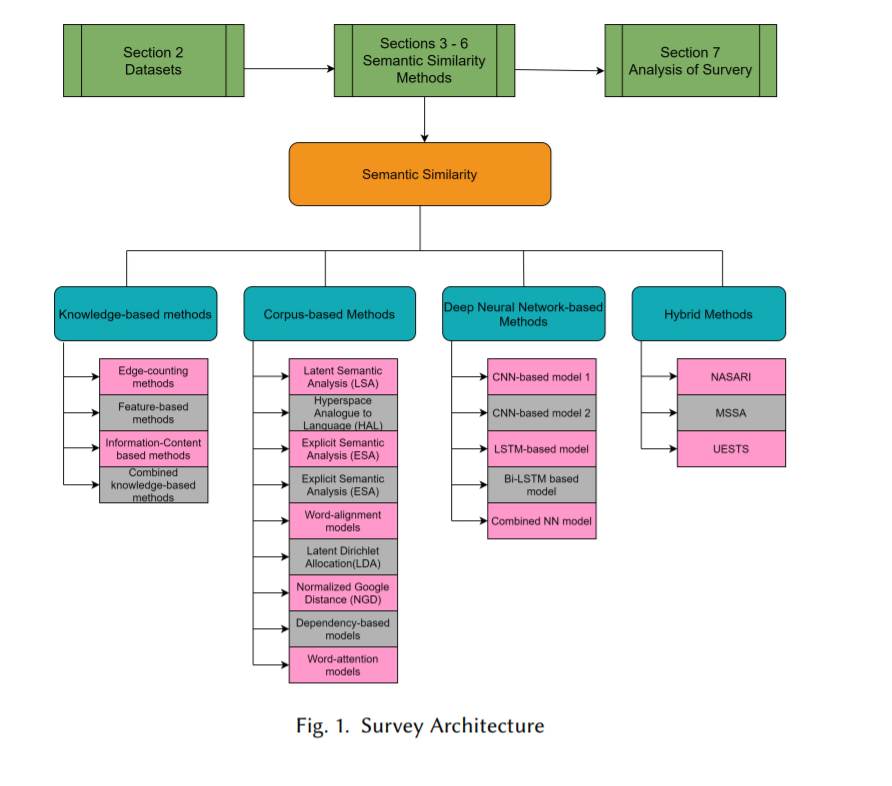
文本数据间语义相似度的估计是自然语言处理领域的一个具有挑战性和开放性的研究课题。由于自然语言的通用性,很难定义基于规则的方法来确定语义相似性度量。为了解决这一问题,多年来人们提出了各种语义相似方法。这篇调查文章追溯了这些方法的发展,根据它们的基本原则将它们分类为基于知识的、基于语料库的、基于深度神经网络的方法和混合方法。通过讨论每种方法的优缺点,本调查提供了现有系统的全面视图,以便新研究人员进行试验和开发创新思想来解决语义相似的问题。
https://arxiv.org/abs/2004.13820
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SS29” 就可以获取《语义相似性算法演化论文,29页pdf,Evolution of Semantic Similarity - A Survey》专知下载链接



登录查看更多
相关内容
专知会员服务
93+阅读 · 2019年11月15日



相关VIP内容
专知会员服务
93+阅读 · 2019年11月15日
相关资讯
相关论文