【机器学习】高斯判别分析

本文介绍了高斯判别分析,首先介绍生成模型,狭义的给出了生成模型与判别模型的一般区别;然后介绍高斯判别分析模型的三个基本假设:1)先验概率服从伯努利分布,2)条件概率服从高斯分布,3)特征的条件概率相互独立(同线性模型中的特征不相关)通过最大似然估计导出模型的参数;最后对比了判别模型中的逻辑回归,一般而言,高斯判别模型的假设条件强于逻辑回归,在模型选择时需考虑数据的分布和模型的适用场景。
作者 | 文杰
编辑 | yuquanle
高斯判别分析
A、生成模型
机器学习模型有一种分类方式:判别模型和生成模型。它们之间的区别在于判别模型是直接从数据特征到标签,而生成模型是从标签到数据特征。形式化的表示就是是否使用了贝叶斯公式:
机器学习模型从概率的角度来看就是最大 的条件概率,判别模型的思想是直接最大化这个概率(Fisher线性判别,线性感知机),生成模型则是通过贝叶斯模型最大后验概率 ,其中 可以看作是从标签生成数据, 则是标签的先验概率。
基本上从标签到数据的模型都是基于对样本的统计,以下的模型都是基于数据的统计(但不全是生成模型),所以笔者将这部分归类到统计概率模型。
B、高斯判别分析
高斯判别分析是一个典型的生成模型,其假设 服从一个高斯分布, 服从一个伯努利分布通过统计样本来确定高斯分布和伯努利分布的参数,进而通过最大后验概率来进行分类。
假设数据在标签为
下,特征为
的条件概率为
服从多元高斯分布
,其中
为均值,
为协方差矩阵。则有:
而先验分布
服从伯努利分布
,当
时,是一元伯努利分布,当
时,同样可以像Logistic推广到SoftMax一样处理多元伯努利分布。下面以一元伯努利分布为例计算完整的高斯判别模型的概率:
最大化后验概率即为:
极大似然函数有:
最大似然估计得到参数如下:
其中
为指示函数,同时假设
,
反映一类数据分布的方差,可以看出最大似然估计的参数值就是基于对样本的一个统计。
下图为一个简单的高斯判别模型示意图:
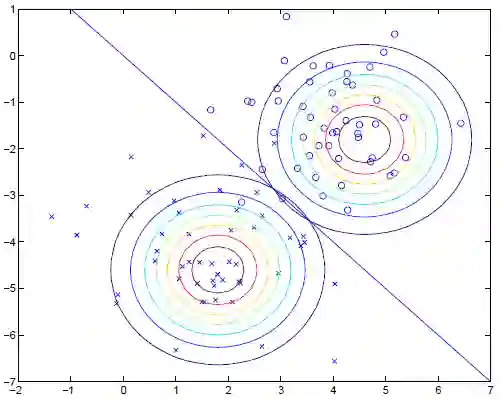
从上图可以看出,高斯判别模型通过建立两类样本的特征模型,对于二分类问题,然后通过比较后验概率的大小来得到一个分类边界。
回过头来再看最小错误贝叶斯决策(Logistic回归)与一维高斯判别模型,有趣的是最后得到的决策函数也类似于sigmoid函数。

C、高斯判别模型与Logistic回归比较
高斯判别模型的假设是 服从一个高斯分布, 服从一个伯努利分布。
Logistic回归的概率解释中可以看出它的假设是 服从伯努利分布。
由高斯判别分析模型可以得到,加上一些推导可以得到,反之不然:
其中, 是参数 的某种函数。也就是说高斯判别模型是Logistic回归模型中的一种特例。
这里我们可以发现高斯判别模型的假设强于Logistic模型,也就是说Logistic回归模型的鲁棒性更强。这就表示在数据量足够大时,跟倾向于选择Logistic回归模型。而在数据量较小,且 服从一个高斯分布非常合理时,选择高斯判别分析模型更适合。
The End

本文转载自公众号:AI小白入门,作者文杰
推荐阅读
赛尔原创 | EMNLP 2019融合行、列和时间维度信息的层次化编码模型进行面向结构化数据的文本生成
Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。






