李开复:从 1983 到 2017,我的幸运与遗憾

作者:李开复
来源:李开复(ID:kaifu)
IT桔子已获得转载授权
下面这篇文章,是李开复对从1983 到 2017 那段经历的回忆。
(1)
今天跟大家讲个故事。
1983-1988 年,我正在卡内基·梅隆大学读计算机博士。
我正忙着暑期教书,秋天投身奥赛罗人机博弈(黑白棋游戏,那是机器第一次真正意义上打败人类冠军的比赛)。
我的导师瑞迪教授(Raj Reddy,图灵奖得主、卡内基梅隆大学计算机系终身教授、美国工程院院士)从美国国防部得到了 300 万美元的经费,用来做不指定语者、大词库、连续性的语音识别。
也就是说,他希望机器能听懂任何人的声音,而且可以懂上千个词汇,懂人们自然连续说出的每一句话。
这三个问题都是当时无解的问题。
而瑞迪教授大胆地拿下项目,希望同时解决这三个问题。他在全美招聘了 30 多位教授、研究员、语音学家、学生、程序员,以启动这个有史以来最大的语音项目。
我也在这 30 人名单之内。

当时的科研背景是,业界已经有类似今天深度学习的算法,但一直没有实现数据标准化,数据量也不足够大。
美国几大语音识别实验室(如 MIT、 CMU、 SRI、 IBM、贝尔实验室)都是各用各的数据库,测试数据不同,训练数据不同,使用的语言模型不同,测试的词汇量也不同。所以都各称业界第一,大家莫衷一是。
而每个大公司都有自己的商业需求,比如说在语音识别方面,当年做打字机的 IBM 想做语音打字机,垄断美国电信的 AT&T 要求贝尔实验室识别电话号码,所以大公司并没有动力来帮助小公司或学校。而小公司和学校,往往只有资源做些较小的数据集,结果通常也不如大公司的好。
不仅如此,数据不标准对 AI 研究而言是致命的,最后导致很多问题,包括:
1、因为测试语料库不同,最后识别结果,大家无法复制,也无法验证。彼此不认可,而且因为数据没有打通,算法就更不可能打通了。
2、因为每家做的领域不同,最后的结果都不可比。有些领域词汇量小,比较容易,但是做出结果也可能不能通用。有些领域词汇量大,但是约束很多,所以能说的内容不多,导致比较容易识别,也不能通用。
3、因为每家训练集不一样大,而训练集越大,一般结果越好。所以,有可能结果做的好,被认为并不是靠算法,而是靠数据量大。
4、对于学术单位来说,最大的问题来自于没有足够的资源(也没有兴趣)收集、清洗、标注大量的语料。对于小公司来说,语料和计算力都是问题。
最后,瑞迪教授计划采用「专家系统」来完成项目,因为这个方法需要的数据有限。
专家系统是早期人工智能的一个重要分支,你可以把它看作是一类具有专门知识和经验的计算机智能程序系统,一般采用人工智能中的知识表示和知识推理技术来模拟通常由领域专家才能解决的复杂问题。
但我不认同。
(2)
之前参加过的奥赛罗的人机博弈,让我对统计概念有了充分的理解,我对瑞迪教授的研究方法产生动摇。
我相信建立大型的数据库,然后对大的语音数据库进行分类,有可能解决专家系统不能解决的问题。
另外,在 1985 年,美国标准局 (NationalInstitute of Standards and Technology) 也意识到数据不标准会影响科研进步。所以在语音识别问题上,标准局设定了标准的语音和语言的训练集、测试集。要求每个学校的每个团队都用同样的训练集来训练模型,可以自己调好系统参数,比赛最后一天大家拿到数据,有一天时间跑出结果,大家评比。
我从这个标准数据集和测试看到机会。
再三思考后,我决定鼓足勇气,向瑞迪教授直接表达我的想法。我对瑞迪说:「我希望转投统计学,用统计学来解决这个『不特定语者、大词汇、连续性语音识别』。」

我以为瑞迪会有些失望,没想到他一点都没有生气,他轻轻地问:「那统计方法如何解决这三大问题呢?」
瑞迪教授耐心地听完我激情的回答后,用他那永远温和的声音告诉我:「开复,你对专家系统和统计的观点,我是不同意的,但是我可以支持你用统计的方法去做,因为我相信科学没有绝对的对错,我们都是平等的。而且,我更相信一个有激情的人是可能找到更好的解决方案的。」
那一刻,我的感动无以伦比。因为对一个教授来说,学生要用自己的方法作出一个与他唱反调的研究。教授不但没有动怒,还给予充分的支持,这在很多地方是不可想象的。
统计学需要大数据库,我们如何才能建立起大的数据库呢?
瑞迪教授看到我愁眉不展的样子,再一次给了我支持。他说,「开复,虽然说我还是对你的研究方法有所保留,但是,在科学的领域里,其实也无所谓老师和学生的区别,我们都是面临这一个难题的攻克者,所以,如果你真的需要数据库,那么,让我去说服政府帮你建立一个大的数据库吧!」
瑞迪教授后来说服了美国政府部门和美国标准局收集并提供了大量数据。我用美国标准局提供的标准大数据,跟多家拿国家钱的机构数据,后来一些不拿国家钱的单位(如:IBM,AT&T)也参与进来,我可使用的数据越滚越大。
除了大数据,统计学的方法还需要非常快的机器,瑞迪教授又帮我购买了最新的 Sun 4 机器。此后每次有新的机器,他都会说:「先问问开复要不要。」做论文的两年多,我至少花了他几十万美元的经费。
瑞迪教授的宽容再次让我感觉到一种伟大的力量,这是一种自由和信任的力量。
(3)
在导师的支持下,我开始了疯狂的科研工作。
当时,我带着另一位学生一起用统计的方法做语音识别。同时,其他 30 多人用专家系统做同样的问题。从方法上来说,我们在竞争,但是在瑞迪教授的领导下,我们分享一切,我们用同样的样本训练和测试。
在 1986 年底,我的统计系统和他们的专家系统达到了大约一样的水平,40% 的辨认率。这虽然还是完全不能用的系统,但毕竟是学术界第一次尝试这么难的问题,大家还是比较欣喜和乐观的。
1987 年 5 月,我们大幅度地提升了训练的数据库,采用了新的建模方法,不但能够用统计学的方法学习每一个音,而且可以用统计学的方法学习每两个音之间的转折。针对有些音的样本不够,我又想出了一种方法(generalized triphones)来合并其他的音。这三项工作居然把机器的语音识别率从原来的 40% 提高到了 80%!后来又提高到 96%。
统计学的方法用于语音识别初步被验证是正确的方向。
大家都相信了我用的机器学习方法和隐马可夫模型算法,并且抛弃了不可行的专家系统(专家系统只达到 60% 的识别率)。在我的博士论文基础上,后来的 Nuance,微软、苹果等公司做出了业界最领先的产品。
1988 年 4 月,我受邀到纽约参加一年一度的世界语音学术会议,发表学术论文。
这个成果撼动了整个学术领域。这是当时计算机领域里最顶尖的科学成果。
语音识别率大幅度提高,让全世界语音研究领域闪烁出一道希望的光芒,从此,所有以专家系统研究语音识别的人全部转向了统计方法。
会后,《纽约时报》派记者 John Markoff 来到匹兹堡对我作了采访,文章发表于 1988 年 7 月 6 日,占了科技版首页的整个半版。在这篇文章里,马可奥夫大力报道了我的论文的突破。当时,我只觉得在和一个和蔼可亲的记者聊天,事后,我才知道这是一名才华横溢的著名记者,三次提名普利策奖,并在斯坦福兼教。

(这是 1988 年,《纽约时报》对我博士论文的报道)
后来,《商业周刊》把我的发明选为 1988 年最重要的科学发明。年仅 26 岁初出茅庐的我,第一次亮相就获得这样的成功,让我感到很幸运,也让我有了继续向科技高峰攀爬的动力。
而我也因此拿到了卡内基·梅隆大学的计算机博士学位,这离我 1983 年入学只有 4 年半的时间。在卡内基·梅隆大学的计算机学院,同学们平均 6 年以上才能拿到博士学位,我用这么短的时间拿到博士学位,是一项新的纪录。
我也因此破格留校,成为一名 26 岁的助理教授。
(4)
遗憾的是,虽然我找到了方向和基本方法,但以当时的数据量级和计算水平,语音 AI 研究很难有商业化机会。我最终还是离开科研界,进入商界,用产品改变世界。
30 年过了,AI 发展的土壤终于肥沃起来。
伴随互联网和移动互联网而来的大数据、高效的计算机运算能力等条件都齐备了。科研人员需要的数据集不再那么难以触碰,只是需要有人牵头让更多的公司参与进来。这在 30 多年前,我还是一个 AI 科研人员的时代,能接触到真实世界里如此海量的数据,是个遥不可及的梦想。
我当年受惠于瑞迪教授的帮助和指导,今天也非常希望能给更多和我一样的年轻人,创造研究机会和条件。
所以,创新工场、搜狗、今日头条联合发起「AI Challenger 全球 AI 挑战赛」。三家公司分别投入大量资金、也拿出千万量级高质量开放数据集与宝贵 GPU 资源。



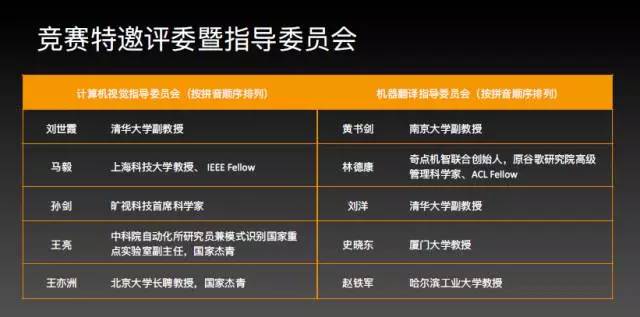
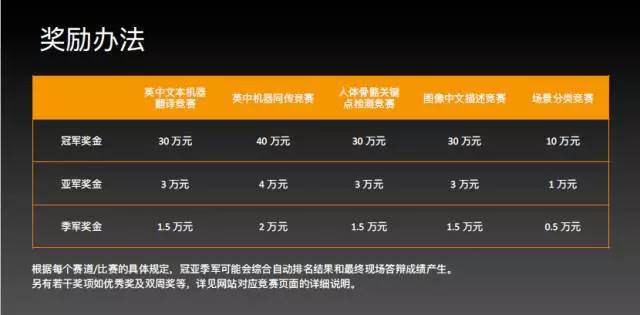
同时,我也倡导商界和科研界能采用大量的数据和标准的测试方法,也欢迎更多的数据公司能够参与到这个平台里。
希望我们推出的 Challenger.ai,可以帮助到中国 AI 人才成长。
在我看来,这次 AIChallenger 绝对不只是一个活动,也绝对不只是一个奖金 200 万、年底就结束的竞赛,这是推进中国 AI 人才成长的重大催化剂。
希望 3 年或 5 年后,我们再来回顾这一段时光,我们发现中美 AI 人才之间没有落差了,还能想到 AI Challenger 在这样重大过程中扮演了一个小小角,我就感到这一切都有价值。
·End·
推荐阅读
点击下方图片即可阅读

▲ 不会技术、不懂销售都没有关系,创业者最必备的能力是——讲好故事 | 经验

▲ 不可错过的科技浪潮:会聊天的机器人?他们能做的事超乎你想象

▲ 《中美AI创投研究报告》发布,解读AI创投浪潮的十大真相






