谷歌联手DeepMind提出Performer:用新方式重新思考注意力机制

新智元报道
新智元报道
编辑:QJP
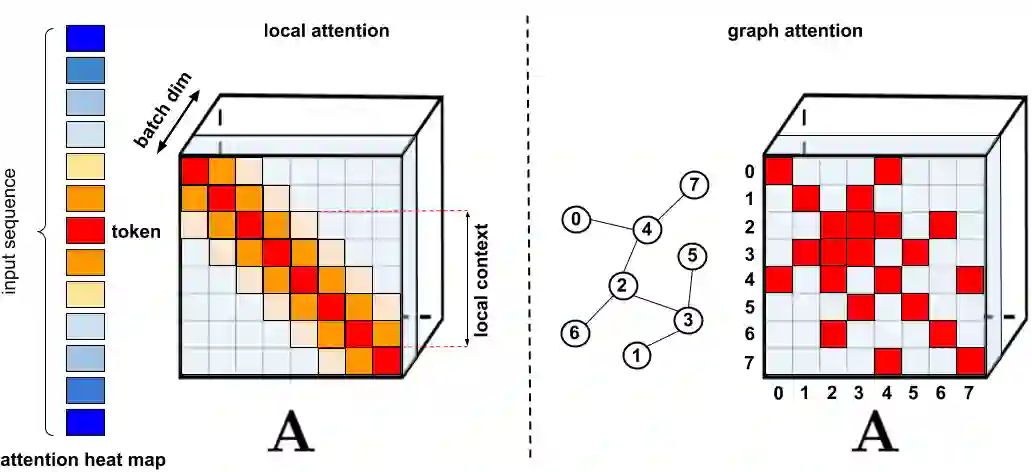
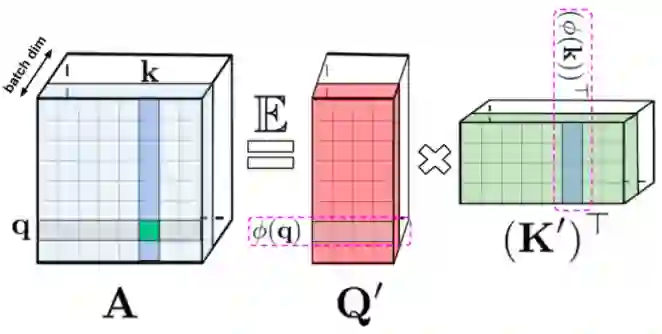
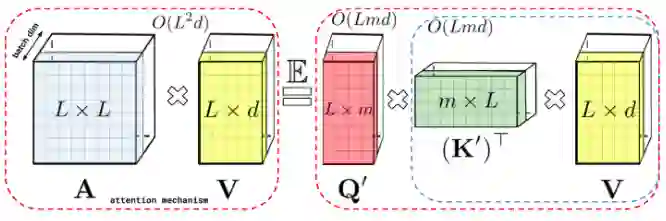
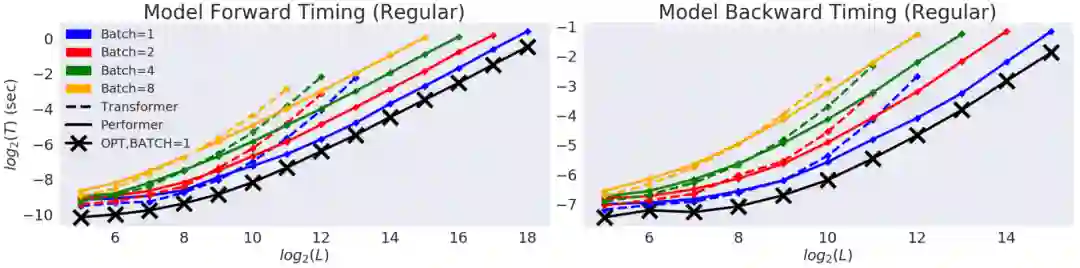
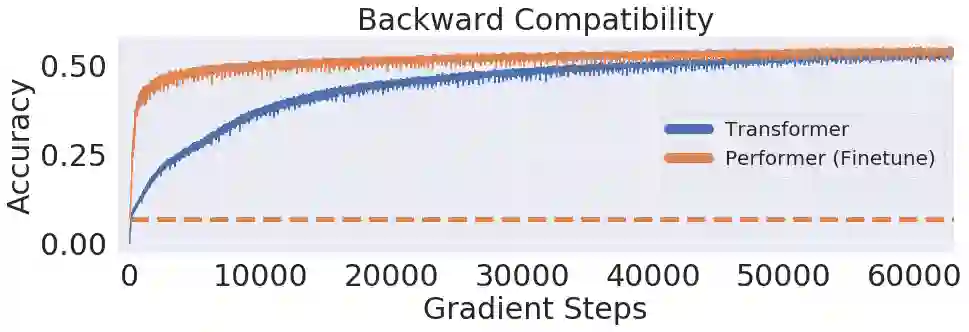
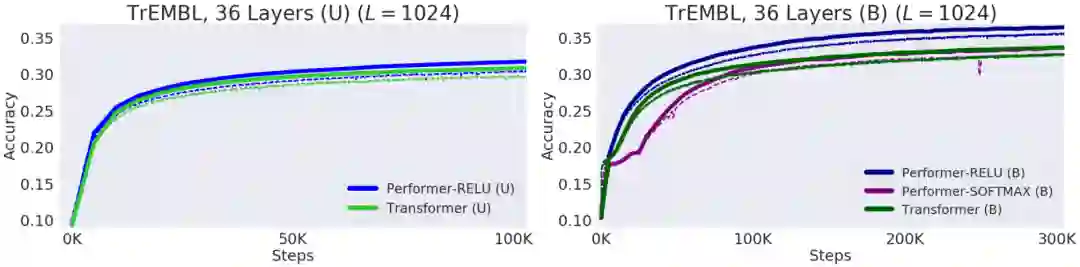
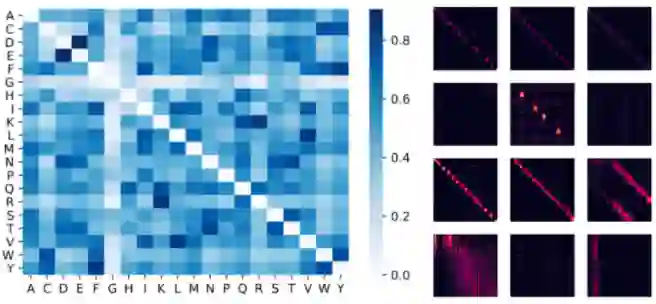
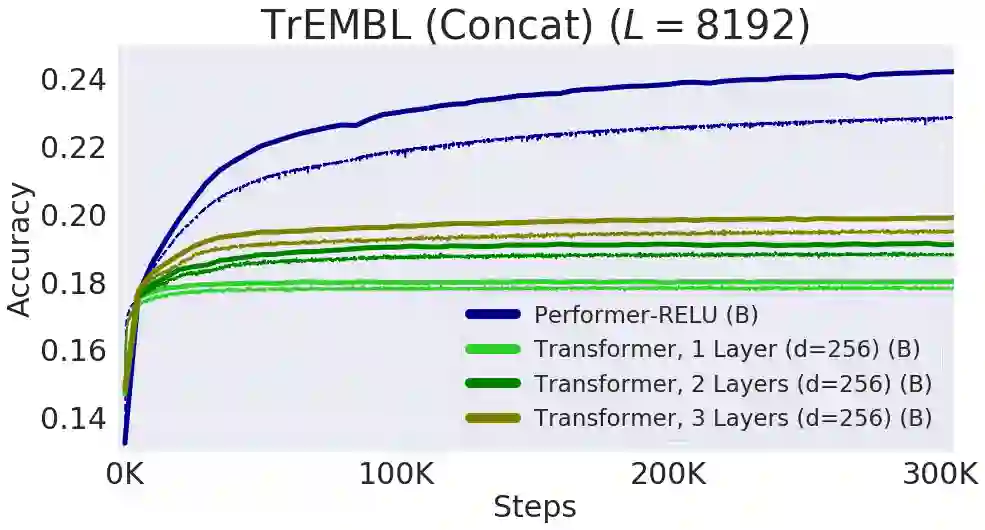
【新智元导读】谷歌、 DeepMind、艾伦图灵研究院和剑桥大学的科学家们提出了「Performer」,一种线性扩展的人工智能模型架构,并在蛋白质序列建模等任务中表现良好。它有潜力影响生物序列分析的研究,降低计算成本和计算复杂性,同时减少能源消耗和碳排放。



登录查看更多
相关内容



相关VIP内容
相关资讯