NLP 界乔碧萝事件:没想到你是这样的爱丽丝
在 XLNet 与 RoBERTa 还未高高挂在 GLUE 榜首的前 XLNet 时代,除了靠着一系列奇技淫巧,比如预训练后精调前加一多任务预训练(Multi-Task Pretraining),还有用集成模型作为老师的知识蒸馏(Knowledge Distillation),位居榜首的 MT-DNN,然后就是紧跟着我们人类的表现,之后便是此次事件的主角,来自阿里达摩院的 ALICE 模型。

因为一直没开源和发布论文,只在其他论文上看到其被提起,便一直很好奇。爱丽丝,嗯... 是什么样呢😏,这个?

这个?

不过既然在 GLUE 榜上估计和芝麻街脱不了干系,于是一搜果然搜出了个芝麻街爱丽丝。
当然,因为好奇达摩院能搞出什么黑科技,一直都想知道 ALICE 到底是什么机制,还根据缩写瞎猜了一通。结果突然看到篇阿里文章,StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding,结果看见一行字。
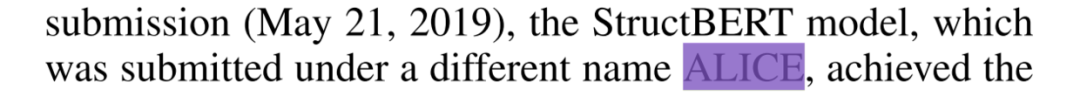
what?这就是 ALICE ?!哪里爱,哪里丽,哪里丝了,抠脚大汉好嘛。百度都还硬凑出了一个 Enhanced Representation through kNowledge IntEgration (ERNIE)好嘛。
闲话少说,StructBERT(ALICE)最主要提出,能否在预训练中学习句子文本的结构,分为句内结构以及句间结构。于是需要对预训练目标进行加强:
句内结构提出新的训练目标,恢复一定范围内词序。
句间结构加强原有 NSP 目标,不光预测前后句关系,还预测后前句关系。
句内结构:词级别结构
首先,按照 BERT 原模型,随机遮盖(Mask)掉一些词,然后输入 BERT 模型预测原词,可以称之为 MLM(Maksed Language Model) 损失。
对于词级别结构学习,实际上就是打乱词序,然后让模型恢复。具体做法是随机从句中挑 5% 的 tri-gram,之后打乱它们的顺序,最后用打乱后位置的词输入模型,预测原来那个词。

于是,举个例子,对一句话进行这样的处理:it [MASK] raining outside → it [MASK] outside raining. 因此,打乱的是后面那个 tri-gram,然后用打乱的词预测对应原词:[MASK] outside raining → [MASK] raining outside。
具体打乱操作,我猜测只需要交换局部位置向量就可以。
最后将这个损失和前面的 MLM 损失加起来反向传播就可以了。
句间结构:句级别结构

主要是对 NSP (Next Sentence Prediction)任务的加强,BERT 原模型中的 NSP 任务即两句拼接判断是否是前后句。然而该任务被多篇论文发现有问题,比如 XLNet、SpanBERT、RoBERTa 里面都有提。详情参考[引用]
其中原因可能是 NSP 带来收益,还没其带来噪音损失大。
而这篇论文里,则认为 NSP 过于简单(很容易就上 97%-98% 准确率),所以应该加强此任务。
于是对原有的 [CLS] S1 [SEP] S2 [SEP] 结构中的 S2,就不光只取后一句了,而是 1/3 概率挑后一句,1/3 概率挑前一句,1/3 概率随机。之后,三分类任务判断属于哪一种。
比较疑惑的是,其中位置向量是怎么加的,按照原样直接加,还是考虑当 S2 为前一句时,位置标号从 S2 开始。
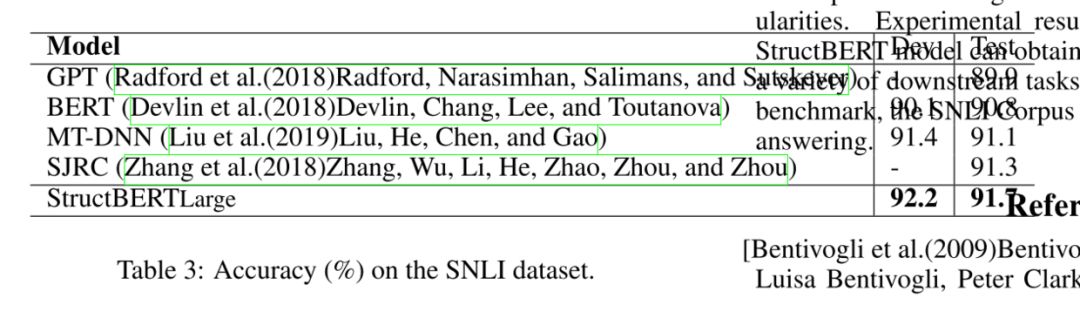
结果与对比
其实大部分实验结果不用提了,早已不是 SOTA 了,可以看看里面的消融实验。主要是分别去掉上面两个策略后的模型和完整模型还有 BERT 模型的对比。
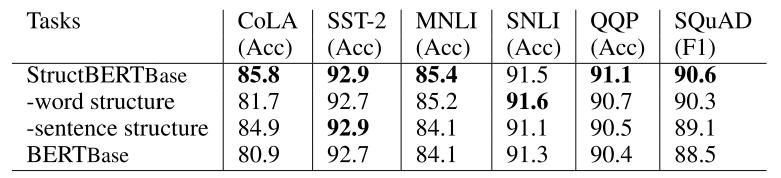
大概可以得出两个结论:
去掉句内结构任务,对 CoLA 以及 SST-2 这样的单句任务影响很大;
去掉句间结构任务,对 MNLI,SNLI,QQP,SQuAD 这样的句子对任务影响比较大。
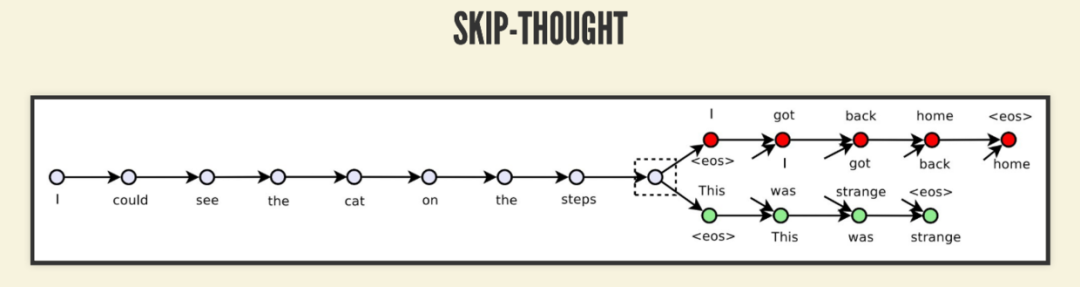
对于 StrucBERT 中的句间结构任务,有点像 Skip-Thoughts 模型的任务了,同时预测前句和后句。其实关于 BERT 中的 NSP 也是有道理的,因为有论文发现 Skip-Thoughts 没必要加预测前句,光预测后句就够了。
关于句间结构,还想到的一个是 ERNIE 2.0 中的 Structure-aware Pre-training Tasks (结构意识预训练任务),其实和这里的 structure 指的差不多,不过里面两个任务是这样做的:
Sentence Reordering Task:文档分成一定数量 m 段,之后取所有组合,shuffle,然后让模型对这些组合进行分类在 ;
Sentence Distance Task:也是三分类,0 表示句子相邻,1 表示不相邻在同一文档,2 表示来自不同文档。
虽然因为 ERNIE 2.0 没有展示任何消融实验的结果,我也无法断言这两个任务的效果,但凭我个人直觉,我会觉得 Sentence Reordering 任务的效果非常值得怀疑,Sentence Distance 都还好些。
相比之下会更喜欢 StructBERT 里这个,因为比较简洁。
还需要吐槽一下论文的格式,不知道可能是之前没用 latex 写过论文还是什么,论文中很多格式错误。
本文转载自公众号:安迪的写作间,作者:Andy
推荐阅读
AI界最危险武器 GPT-2 使用指南:从Finetune到部署
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。


