都说 AllenNLP 好用,我们跑一遍看看究竟多好用

本文为雷锋字幕组编译的技术博客,原标题Deep Learning for text made easy with AllenNLP,作者为Déborah Mesquita 。
翻译 | 汪宁 徐玮 整理 | 凡江

良好学习过程的关键原则之一,就是让学习的内容略高于当前的理解。如果该主题与你已知的内容太过于相似,那么你就不会有很大的进步。另一方面,如果这个主题太难的话,你就会停滞不前,几乎没有进展。
深度学习涉及很多不同的主题和很多我们需要学习的东西,所以一个好的策略就是开始研究人们已经为我们构建好了的东西。这就是为什么框架非常棒的原因。框架使我们不必太过于关心如何构建模型的细节,使得我们可以更多地关注我们想要完成的任务(而不是专注于如何实现)。
对于构建深度学习中的NLP模型,AllenNLP框架使得任务变得十分有趣。这对我来说是一个惊喜,因为我之前在深度学习中的NLP的学习经历是痛苦的。
处理NLP任务需要不同类型的神经网络单元,因此在开始学习如何使用AllenNLP框架之前,我们先快速回顾这些单元背后的理论。
当简单的神经网络不够时
在简单的工作中,阅读文本的任务包括构建我们之前阅读的内容。举个例子,如果之前你没读过这个句子你可能就不懂这个句子的意思,所以创建这些神经网络单元背后的想法是:
“人类为了理解接下来会发生什么,把他们以前读过的东西找出来,也许我们在模型中使用这种机制,他们就能更好地理解文本,对吧?”
递归神经网络
为了使用考虑时间的网络,我们需要一种表示时间的方式。但我们如何做到这一点?
处理具有时间范围的模式的一种显而易见的方法是通过将模式的序列顺序与模式向量的维度相关联来显式的表示时间。第一时间事件由模式向量中的第一个元素表示,第二个时间事件由模式向量中的第二个位置表示,依此类推。 - Jeffrey L. Elman
问题是这种方法有几个缺点,例如:
[...] 移位寄存器对模式的持续时间施加了一个严格的限制 (因为输入层必须提供最长可能的模式),并且建议所有输入向量具有相同的长度。这些问题在语言等领域特别麻烦,因为在这些领域中,人们希望具有可变长度模式的类似表示。语言的基本单位(拼音段)与句子一样也是如此。
Jeffrey L. Elman讨论了论文中发现的其他缺陷。本文介绍了 Elman网络,这是一个三层网络,增加了一组“上下文统一”。
如果你对神经网络完全陌生,那么阅读我写的另一篇文章可能是个好主意。但简单地说,神经网络是有机会被激活的或者不是被输入的。
Elman根据Jordan(1986)提出的方法开始他的工作。Jordan引入递归连接。
递归连接允许网络的隐藏单元看到自己以前的输出,以便随后的行为可以被以前的响应所决定。这些递归的连接是网络存储器的功能。紧接着Elman添加了上下文单元。这些上下文单元作为一个时钟来说明什么时候我们应该放弃以前的输入。但是这又如何呢?上下文单元也具有调整权重的机制,就像其他神经网络单元一样。
上下文单元和输入激活神经网络隐藏单元。 当神经网络“学习”时,这意味着它有一个表示所有输入网络处理的模式。上下文单元记住以前的内部状态。
如果这些都没有意义,不要担心。只要想一想,现在我们有一个神经网络单元,它将先前的状态考虑在内以产生下一个状态。
“现在我们有一个神经网络单元,它考虑到以前的状态来产生下一个状态。”
当 RNNs 不够时:LSTM
正如Christopher Ola 在另一篇文章解释的那样 (如果你想了解更多关于LSTM的信息,这篇文章是很棒的),有时我们需要更多的上下文,也就是有时我们需要存储很久以前看到的信息。
考虑尝试预测“我在法国长大......我会说流利的法语 ”中的最后一句话。最近的信息表明,下一个词可能是一种语言的名称,但如果我们想要缩小到具体是哪种语言,我们需要从法国出发来考虑更长远的东西。缩小相关信息与需要变得非常大的点之间的差距完全可能 - Christopher Ola
LSTM单元解决了这个问题。它们是一种特殊的RNN,能够学习长期的依赖关系。我们将只使用LSTM单元,而不是构建它们,因此对于我们而言,可以将LSTM单元看作具有不同架构并能够学习长期依赖性的单元。
构建一个文本分类的高级模型
好了,有了足够的理论,现在让我们进入有趣的部分,并建立模型。
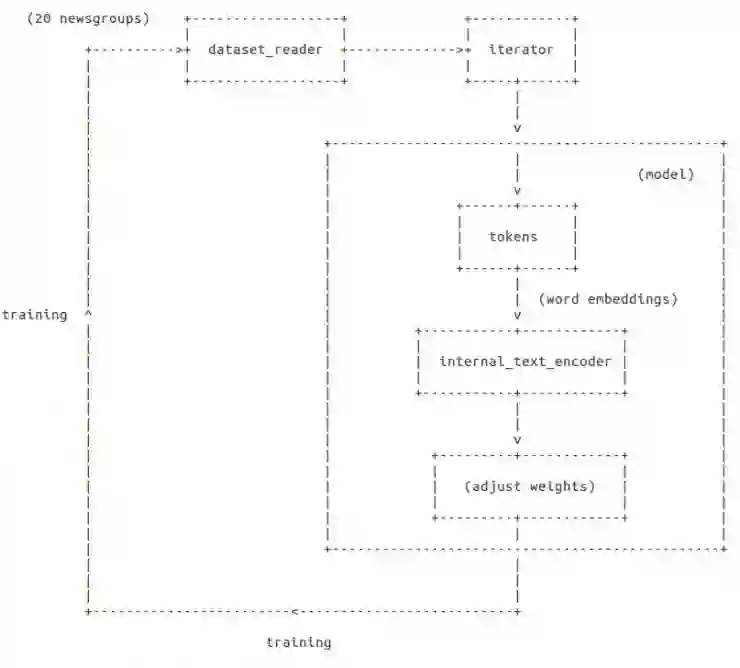
训练过程
上面的图片向我们展示了我们如何设置一切。首先我们得到数据,然后将它编码为模型将理解的格式('tokens'和'internal_text_encoder'),然后我们用这些数据来训练网络,对比标记并调整权重。在这个过程结束时,模型已经准备好做出预测了。
现在我们终于会感受到AllenNLP的魔力!我们将用一个简单的JSON文件指定上图中的所有内容。
{
"dataset_reader": {
"type": "20newsgroups"
},
"train_data_path": "train",
"test_data_path": "test",
"evaluate_on_test": true,
"model": {
"type": "20newsgroups_classifier",
"model_text_field_embedder": {
"tokens": {
"type": "embedding",
"pretrained_file": "https://s3-us-west-2.amazonaws.com/allennlp/datasets/glove/glove.6B.100d.txt.gz",
"embedding_dim": 100,
"trainable": false
}
},
"internal_text_encoder": {
"type": "lstm",
"bidirectional": true,
"input_size": 100,
"hidden_size": 100,
"num_layers": 1,
"dropout": 0.2
},
"classifier_feedforward": {
"input_dim": 200,
"num_layers": 2,
"hidden_dims": [200, 100],
"activations": ["relu", "linear"],
"dropout": [0.2, 0.0]
}
},
"iterator": {
"type": "bucket",
"sorting_keys": [["text", "num_tokens"]],
"batch_size": 64
},
"trainer": {
"num_epochs": 40,
"patience": 3,
"cuda_device": 0,
"grad_clipping": 5.0,
"validation_metric": "+accuracy",
"optimizer": {
"type": "adagrad"
}
}
}
让我们来看下这段代码。
1 数据输入
为了告诉AllenNLP输入的数据集以及如何读取它,我们在JSON文件中设置了“dataset_reader”键值。
DatasetReader从某个位置读取数据并构造Dataset。除文件路径之外的读取数据所需的所有参数都应
递给DatasetReader的构造器。 — AllenNLP documentation
数据集是 20个新闻组,我们将在稍后定义如何读取(在 python 类中)。先来定义模型的其余部分。
2 模型
我们先设置'model'键值来指定模型,在'model'键值中还有三个参数:'model_text_field_embedder','internal_text_encoder'和'classifier_feedforward'。
我们先来看一下第一个,其余的两个将在稍后说明。
通过'model_text_field_embedder',我们告诉AllenNLP数据在传递给模型之前应该如何编码。 简而言之,我们希望使数据更“有意义”。 背后的想法是这样的:如果可以像比较数字那样比较文字会怎么样?
如果5 - 3 + 2 = 4 , 国王-男人+女人=女王,又何尝不对呢?
用词嵌入我们可以做到这一点。 这对模型也很有用,因为现在我们不需要使用很多稀疏数组(具有很多零的数组)作为输入。
词嵌入是自然语言处理(NLP)中的一组语言建模和特征学习技术的总称,其中来自词汇表的单词或短语被映射为实数向量。 从概念上讲,它涉及从每个单词一个维度的空间到具有更低维度的连续向量空间的数学嵌入。— Wikipedia
在我们的模型中将使用GloVe:用于词汇表征的全局向量。
GloVe是一种用于获取单词向量表征的无监督学习算法。 对来自语料库的汇总的全局单词共现统计进行训练,表征结果展示了单词向量空间的有趣的线性子结构。— Glove
如果还是难以理解,只要将Glove看作是一种将单词编码为向量的模型。我们将每个嵌入向量的大小设置为100。
Glove把单词编码为向量
这就是'model_text_field_embedder'所做的。
3 数据迭代器
像往常一样,我们将分批分离训练数据。 AllenNLP提供了一个名为BucketIterator的迭代器,通过对每批最大输入长度填充批量,使计算(填充)更高效。 要做到这一点,它将按照每个文本中的符号数对实例进行排序。 我们在'iterator'键值中设置这些参数。
4 训练器
最后一步是设置训练阶段的配置。 训练器使用AdaGrad优化器作10代训练,如果最后3代的验证准确性没有提高,则停止。
为了训练模型,我们只需要运行:
python run.py our_classifier.json -s /tmp/your_output_dir_here
另一个很酷的事情是,通过框架我们可以停止并在稍后恢复训练。 但在此之前,我们需要指定dataset_reader和模型python类。
编写 AllenNLP Python 类
dataset_reader.py
我们将使用scikit-learn提供的20个新闻组。 为了引用JSON文件中的DatasetReader,我们需要注册它:
@DatasetReader.register("20newsgroups")
class NewsgroupsDatasetReader(DatasetReader):
你将实施三种方法:其中两个为read()和text_to_instance()。
read()
read()从scikit-learn获取数据。通过AllenNLP,你可以设置数据文件的路径(例如JSON文件的路径),但在我们的例子中,我们只需像Python模块一样导入数据。 我们将读取数据集中的每个文本和每个标签,并用text_to_instance()包装它。
text_to_instance()
此方法“进行任何符号化或必要的处理,来把文本输入转为Instance”(AllenNLP Documentation)。在我们的实例中意味着这样做:
@overrides
def text_to_instance(self, newsgroups_post: str, label: str = None) -> Instance:
tokenized_text = self._tokenizer.tokenize(newsgroups_post)
post_field =
fields = {'post': post_field}
if label is not None:
fields['label'] =
return Instance(fields)
我们将来自20个新闻组的文本和标签包装到TextField和LabelField中。
model.py
我们将使用双向LSTM网络,该网络是第一个循环层被复制的单元。 一层按原样接收输入,另一层接收输入序列的反向副本。 因此,BLSTM网络被设计为捕获顺序数据集的信息并保持过去和未来的上下文特征。 (来源:中文分词双向LSTM循环神经网络)
首先我们来定义模型的类参数
vocab
因为在你的模型中经常会有几种不同的映射,所以Vocabulary会追踪不同的命名空间。 在这种情况下,我们为文本设置了“符号”词汇(代码中未显示,是在背后使用的默认值),以及我们试图预测的标签的“标签”词汇。—— Using AllenNLP in your Project)
model_text_field_embedder
用于嵌入符号与作为输入的TextField。 返回单词的 Glove向量表征。
internal_text_encoder
我们用来把输入文本转换为单个向量的编码器(RNNs,还记得吗?)。 Seq2VecEncoder是一个模块,它将一个向量序列作为输入并返回一个向量。
num_classes — 要预测的标签数量
现在我们来实现模型类的方法
forward()
前向法做的是
模型所做的第一件事是嵌入文本,然后将其编码为单个矢量。 为了对文本进行编码,我们需要获得掩码来表示符号序列的哪些元素仅用于填充。
然后,将它经过前馈网络以获得类别逻辑回归。 将逻辑回归经过softmax来获得预测概率。 最后,如果我们获得了标签,我们可以计算损失并评估我们的度量。— Using AllenNLP in your Project
正向法基本上是在做模型训练任务。 如果你想多了解一些,可以看这个。现在我们来谈谈模型类参数的一个重要部分:classifier_feedforward。
我们需要Model.forward来计算损失。 训练代码将查找由forward返回的字典中的损失值,并计算该损失的梯度以更新模型的参数。— Using AllenNLP in your
decode()
decode有两个功能:它接收forward的输出,并对其进行任何必要的推理或解码,并将整数转换为字符串以使其便于人类阅读(例如,用于演示)。— Using AllenNLP in your
运行代码
正如我之前所说,通过命令行来训练模型,可以使用以下命令:
python run.py our_classifier.json -s /tmp/your_output_dir_here
我还创建了一个笔记本,以便我们可以在Google Colaboratory上运行实验并免费使用GPU,以下是链接:https://colab.research.google.com/drive/1q3b5HAkcjYsVd6yhrwnxL2ByqGK08jhQ
你也可以在这查看代码:this repository
我们建立了一个简单的分类模型,但可能性是无限的。 该框架是为我们的产品创建奇特的深度学习模型的绝佳工具。
博客原址 http://deborahmesquita.com/2018-03-19/deep-learning-for-text-made-easy-with-allennlp-62bc79d41f31
更多文章,关注雷锋网(公众号:雷锋网)
添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be an AI Volunteer !


4 月 AI 求职季
8 大明星企业
10 场分享盛宴
20 小时独门秘籍
4.10-4.19,我们准时相约!

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
如何在 NLP 领域干成第一件事?
▼▼▼




