Attention增强的卷积网络

最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,本文是这个系列的第二十三篇,内容较为深入,需要学习基础的同学点击链接进入文章列表查看基础知识相关文章。
Overall
在Conformer: 卷积增强的Transformer中,我们介绍了如何在Transformer中应用卷积,在本文中,则介绍如何将Transformer中的attention机制应用到卷积神经网络中。
参考文献[1]提出了一种基于二维相对位置的注意力机制,只用这种机制可以达到与卷积类似的效果,与卷积混用则能达到更好的效果。
图像上的自注意力
对于一张图像来说,它的shape一般是[H, W, Fin],一个暴力的方法就是将H和W展平,变成[H * W, Fin],然后在这个矩阵上直接运行attention,得到:
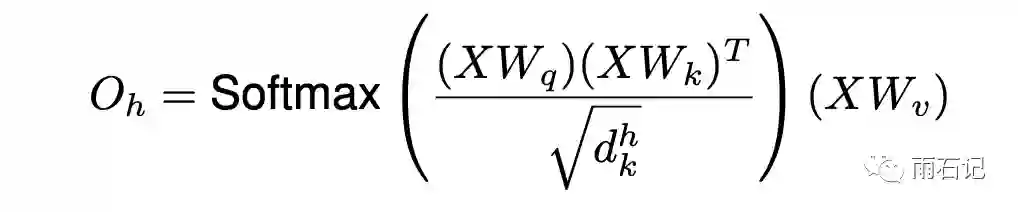
其中,X就是H和W展平后的矩阵。多头注意力的结果要拼接起来。
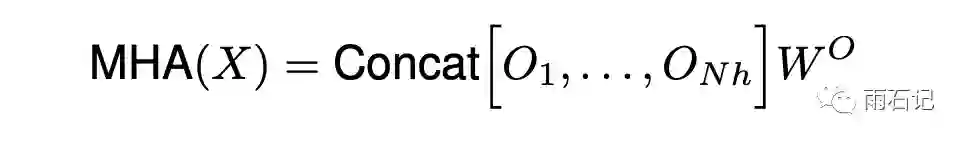
位置编码
但上面的计算方式完全忽略了位置信息,就导致如果对图像上的各个像素的位置做一个混排,再进行attention也能得到一样的结果,即:
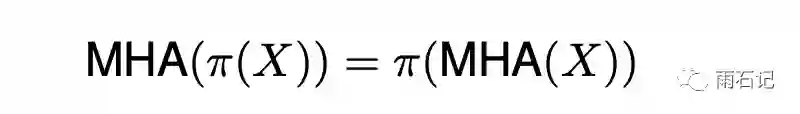
其中,π就是一种排列方法。
而我们知道,卷积之所以能在图像上大获成功,跟它能捕捉结构信息有很强的关系。所以位置信息无法丢弃。因此,和Transformer中相对位置编码中描述的1维相对位置类似,这里,我们使用2维的相对位置编码。
更具体的,位置(ix, iy)和位置(jx, jy)之间计算注意力的logits的时候,公式如下:
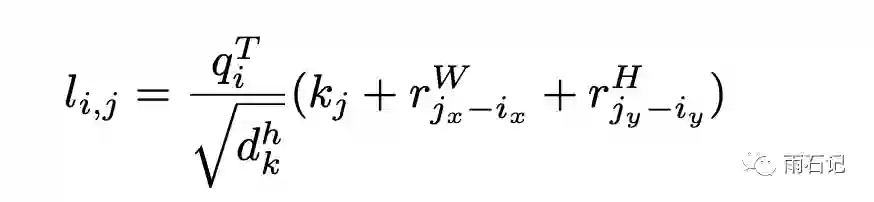
注意到,这里分别为x维和y维定义了一个相对位置编码。因而,计算attention的公式就变成了
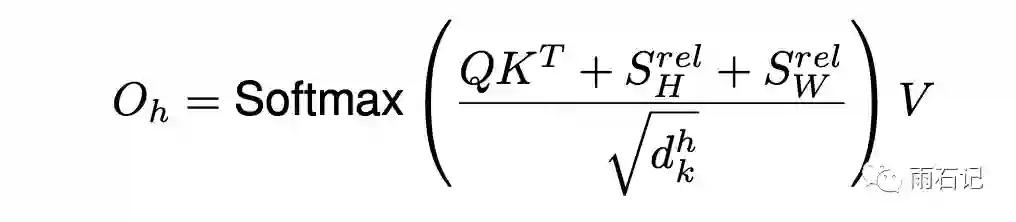
其中,SHrel[i, j] = qirjx-ixH,SWrel同理。
跟一维相对位置类似,相对位置的embedding只看相对位置差,和绝对位置无关。
卷积和自注意力的拼接
为了同时利用卷积和自注意力,这里将它们的输出拼接在一起。如下图:
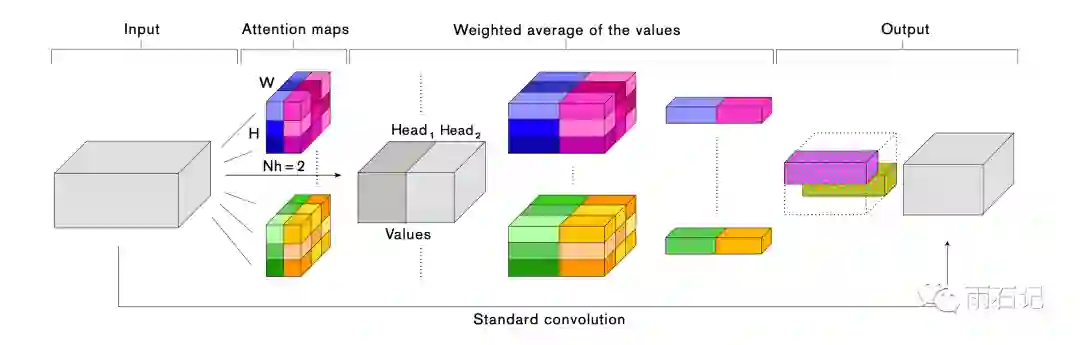
公式如下:

假设原来的卷积层的参数为 kernel_size = k, 输入通道 = Fin, 输出通道 = Fout。这里再定义两个参数:
v = dv / Fout, 其中dv是attention计算中value的维度。这个参数控制着拼接结果中attention和卷积结果的比例,这个比例越大,卷积的比例就越低。
k = dk / Fout, 其中dk是attention计算中key的维度,这个参数控制着注意力权重的计算。
参数量
更进一步的,attention引入的参数为Wq, Wk和Wv,所以相当于做了一个1x1的卷积,输入通道为Fin, 输出通道数目为2dk+vv = Fout(2k+v)
实验
使用ResNets、MNasNet在Cifar100, ImageNet和COCO数据集上分别做了实验验证。
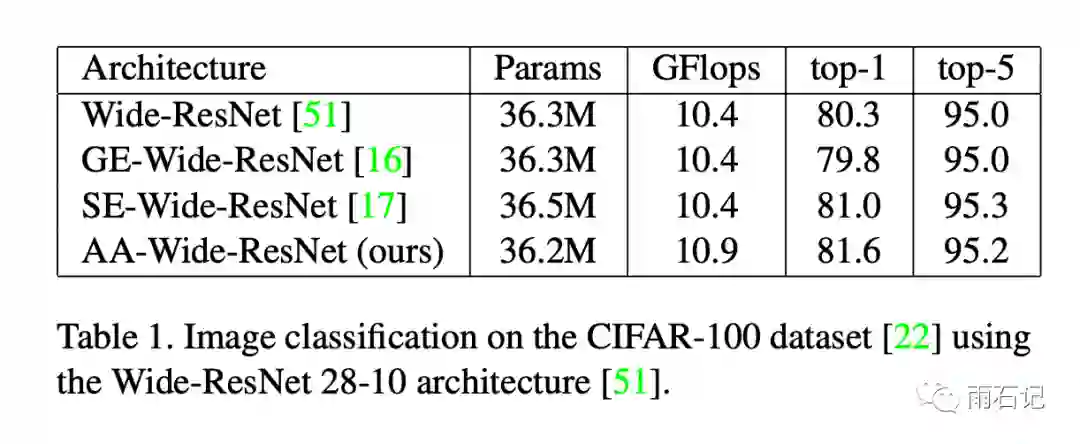
其中在Cifar100上,对Wide-ResNet-28-10结构进行了增强,在每个残差块的第一个卷积层用了注意力增强。
注意力使用8个头,k=2v=0.2,每个头的embedding至少20。同时,还将Squeeze-and-Excitation(SE)和Gather-Excite也进行了实现,结果如下,可以看到注意力增强效果比Excitation方法要好。
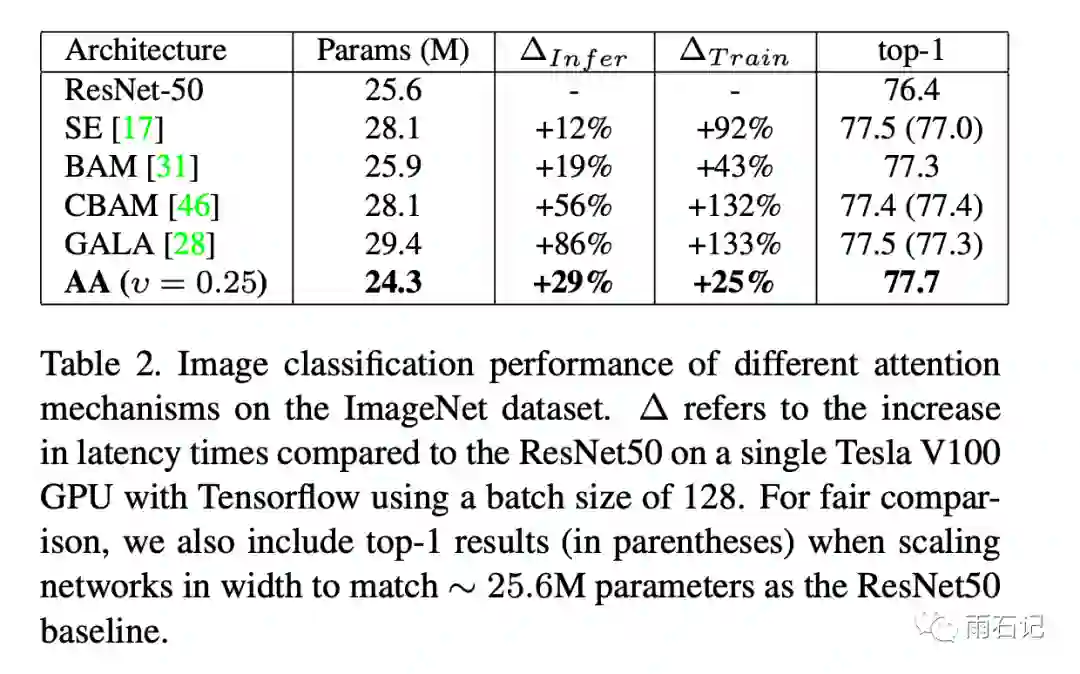
类似的,在ImageNet上,结果如下:
如果完全使用attention,也可以达到卷积类似的效果。如下图, k=v=1.0时效果和ResNet-34类似。
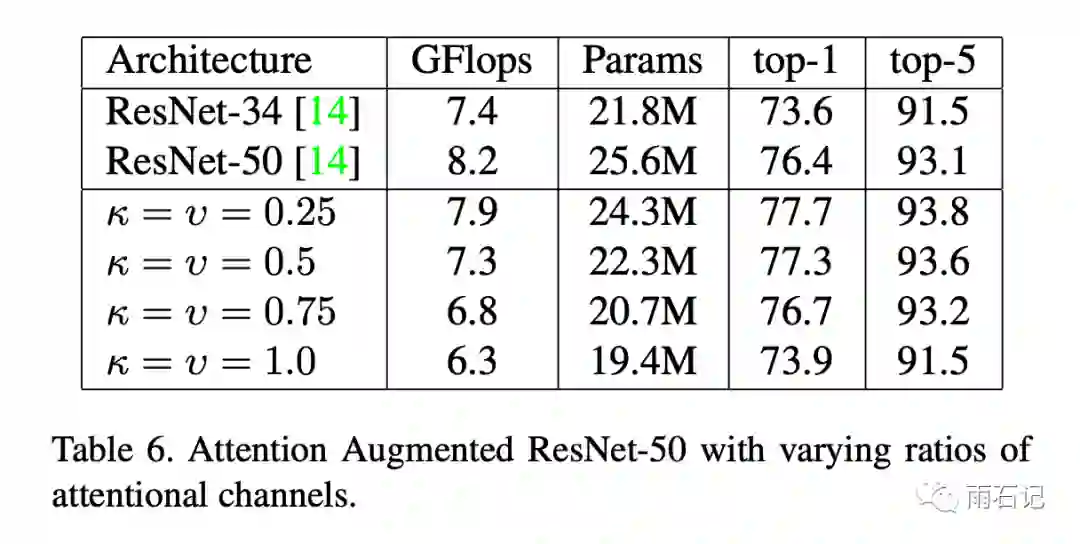
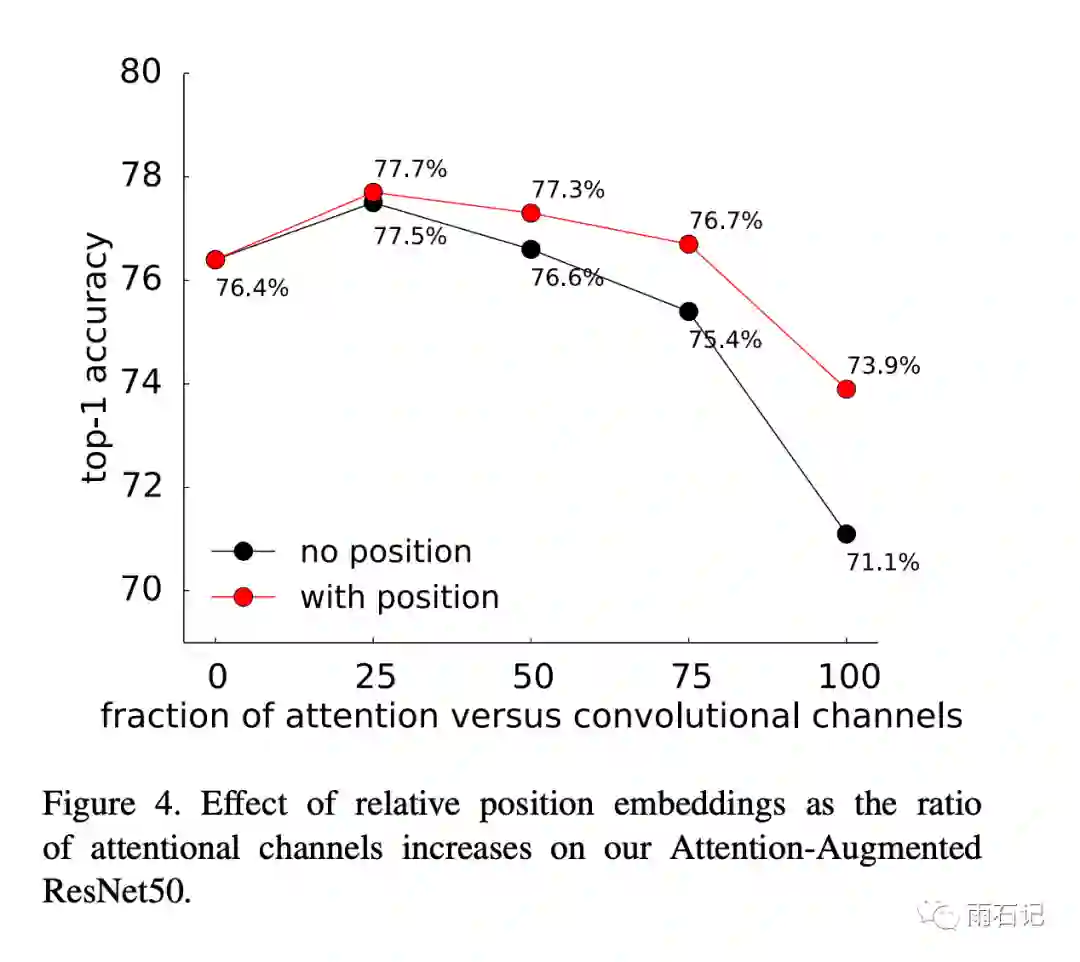
在消融实验中,发现相对位置编码非常重要,如下图,在完全使用注意力的时候,可以提升效果2.8%。
和其他网络的比较如下:
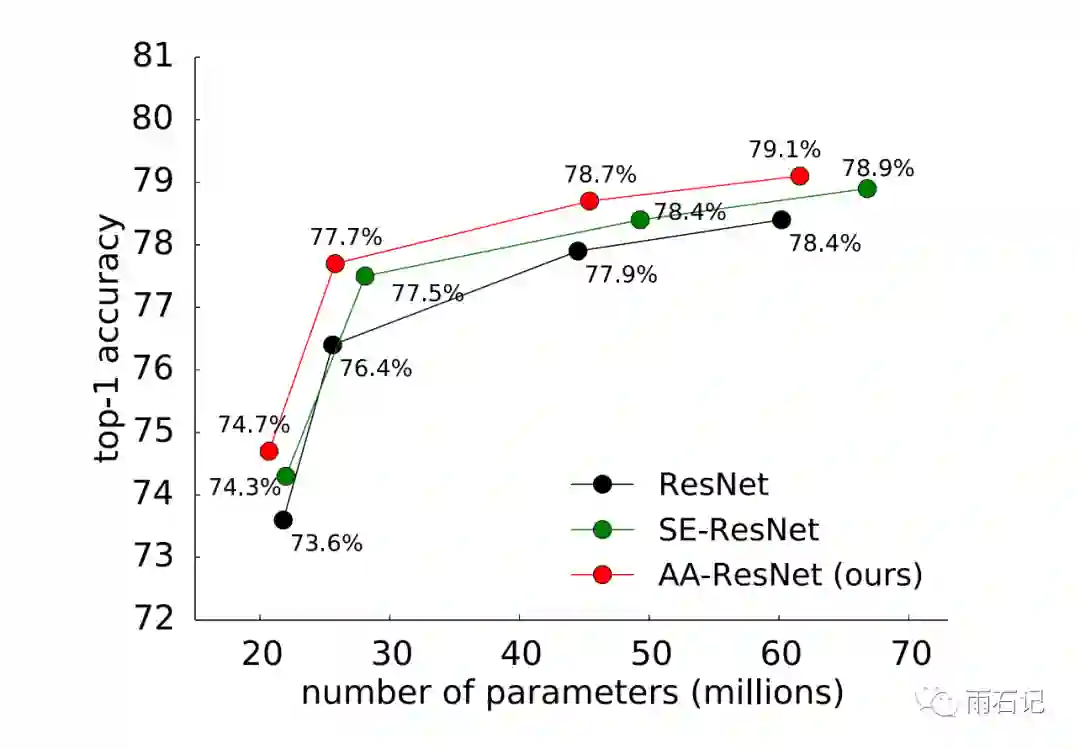
更多实验结果可以参考论文。
Bert系列计划写50篇相关文章,欢迎感兴趣的同学关注公众号【雨石记】
参考文献
-
[1]. Bello, Irwan, et al. "Attention augmented convolutional networks." Proceedings of the IEEE International Conference on Computer Vision. 2019.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


