论文解读者:北邮 GAMMA Lab 博士生 纪厚业
![]()
题目:
Large-scale Comb-K Recommendation
1 简介
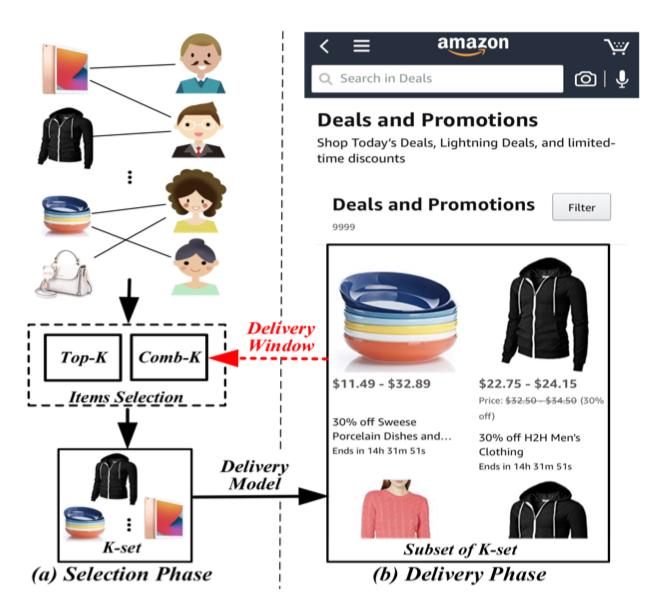
在信息爆炸的时代,推荐系统已经成为一种高效发现用户偏好的手段。多种多种的推荐范式也不断涌现。作为一种新颖的推荐范式,促销推荐可以很好的刺激用户购买欲望进而最大化收益。不同于传统的推荐(如商品推荐和组推荐), 促销推荐(如图1所示)旨在在选择阶段考虑所有用户的偏好来选择一组K个商品并最大化投放阶段的收益。尽管上述两个阶段高度关联,现有的算法通常只关注于商品选择阶段,极大的忽略了投放阶段进而导致次优的结果。为了更好的解决促销推荐问题,我们提出了一种Comb-K推荐模型,一种带约束的组合优化问题。通过精心设计的一些约束,Comb-K可以无缝的整合选品与投放两个阶段,进而达到最优的投放效果。特别的,即使我们在选品阶段选择了K个商品构成了K-set,用户来投放阶段也只能看到K-set中的W个。而只有被用户看到的商品才可能真正的产生投放收益。尽管上述2个阶段高度相关,但是现有的算法并没有很好的考虑它,进而导致了次优的结果。
![]()
为了解决促销推荐问题,我们提出了Comb-K推荐模型,一个带约束的组合优化问题来实现更佳的选品效果。受益于精心设计的约束(尤其是投放窗口W的约束),Comb-K推荐能够综合考虑选择阶段和投放阶段的情况。当选择K个商品时, Comb-K能够考虑所有用户的偏好来搜索最优的K个商品的组合。首先,我们设计异质图卷积来学习用户偏好并求解用户级别的Comb-K问题。进一步的,为了解决大规模组合爆炸的问题, 我们将海量用户聚集为少量人群,并在人群级别求解Comb-K问题。这里,我们提出了一个异质图池化模型来进行人群聚类和人群偏好估计。除此之外,我们还设计了一个快速求解策略RNHS来加速Comb-K的求解过程。最后,在大规模数据上验证了我们模型的有效性。
2 Comb-K推荐建模
2.1 用户级别Comb-K
给定用户
在商品
上的偏好
,用户级别Comb-K旨在求解一组最佳决策变量:商品选择
和商品投放
,来最大化其在所有用户上的累积偏好:
其中,
代表每个用户只能看到K-set中的W个商品,
代表只有被选择的商品才会投放给用户。
例如,
代表商品
被选择了但没有投放给用户
。
可以看出,用户级别Comb-K综合建模了商品选择和投放过程。
但是,在大规模数据上,Comb-K会发生组合爆炸进而变得无法求解。
直观的想,具有相似偏好的用户应该属于同一个人群。
如果我们能把M个用户聚类为P个人群(M远大于P),并且在人群级别建模Comb-K推荐。
那么,其复杂度会大幅度降低并可以在实际大规模场景下求解。
具体的,给定人群
对商品
的偏好
和人群权重
,人群级别Comb-K旨在求解一组最佳决策变量:商品选择
和商品投放
,来最大化其在所有人群上的累积偏好:
其中,
表示商品
是否会被投放给人群
,
代表人群
中的每个用户只能看到W个商品。
为了估计用户偏好,需要首先学习用户及商品的表示,然后预测它们的匹配程度。
以用户
的表示为例,本文首先将其特征表示拼接起来作为初始用户表示
。
其中,
代表用户
的第
个特征的表示。
本文设计了异质图神经网络
聚合多种邻居信息来学习多个用户表示
。
具体来说,对于用户
和特定关系
,我们可以聚合其在该关系下的邻居来学习用户的表示。
为了综合考虑多个关系下的结构信息,本文进一步将
进行了融合,如下所示:
其中,
是用户
的最终表示,
是拼接符号。同样的,我们可以得到商品
的表示
。然后,我们可以通过一个神经网络
来预测用户对商品的偏好
。
3.1.2 人群偏好估计
进一步的,我们可以将海量用户聚类为少量人群并估计人群偏好。这样可以大幅度缓解Comb-K的组合爆炸问题。
具体来说,我们设计了一个异质图池化网络
,其输入为M个用户的表示
,输出为P个人群的表示
:
直观的想,即使用户具有相似的偏好并属于同一个人群,其偏好程度也会有所差异。因此,我们初始化P个人群中心
,然后计算用户
到人群
的相似度
,如下所示:
然后,我们对其进行归一化,并利用归一化系数
来更新人群的表示
。
其中,
代表人群
的偏置向量。最后,我们可以根据人群表示和商品表示来估计其偏好
,如下所示:
最后,我们可以根据相应的损失函数来优化模型。用户偏好的损失函数为
3.2 组合优化求解
Comb-K推荐可以利用经典的组合优化算法进行求解,但是求解效率不够。因此,我们设计了一种快速求解策略,叫做限制邻居搜索策略。具体来说,其主要步骤包括:
-
-
以top-K所求解的K个商品作为初始解,以top-K~2K的商品作为候选解;
-
在初始解和候选解之间进行元素交换,直到最大化收益。
尽管上述求解策略只能发现局部最优解。但是,在实际验证中,我们发现其的效果与精确求解差距不大,但效率大幅度提升。
4 实验
4.1 数据集和对比算法
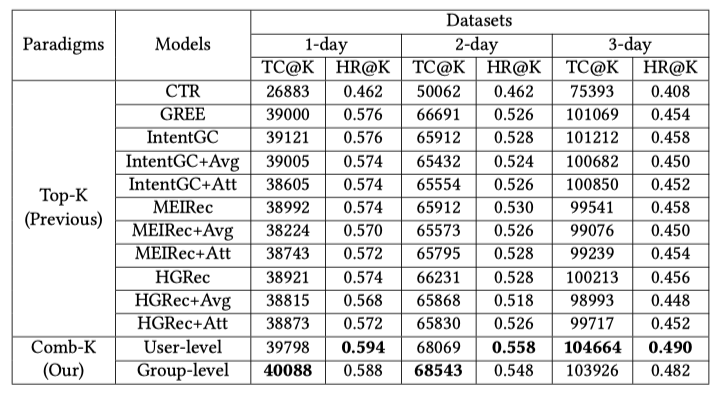
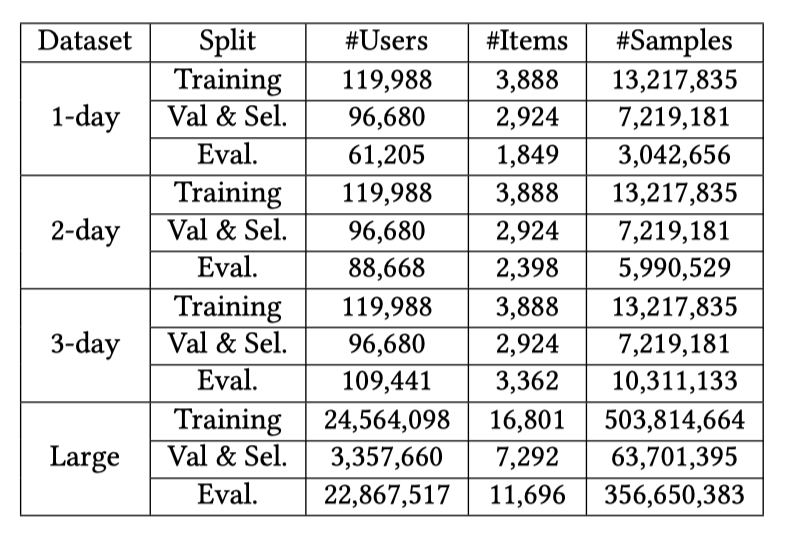
我们在4个不同规模的Taobao数据集进行了验证。
![]() 对比算法为经典的Top-K算法,具体包括DNN,GREE,MEIRec,IntentGC,HGRec。
同时,我们对现有算法进行了扩展,使其更好的实现选品过程,如MEIRec+Avg/Att,IntentGC+Avg/Att 和 HGRec+Avg/Att。我们的算法主要是用户级别和人群级别的Comb-K算法。评价指标为总点击量和命中率:
其中,
代表了商品
的点击量,
和
分别代表选出的K个商品和点击量最高的K个商品。
对比算法为经典的Top-K算法,具体包括DNN,GREE,MEIRec,IntentGC,HGRec。
同时,我们对现有算法进行了扩展,使其更好的实现选品过程,如MEIRec+Avg/Att,IntentGC+Avg/Att 和 HGRec+Avg/Att。我们的算法主要是用户级别和人群级别的Comb-K算法。评价指标为总点击量和命中率:
其中,
代表了商品
的点击量,
和
分别代表选出的K个商品和点击量最高的K个商品。
4.2 有效性实验
这里我们首先对比了之前的top-K算法来验证comb-K推荐的优势。在3个数据集上,无论是用户级别还是人群级别,comb-K均取得了明显的提升。
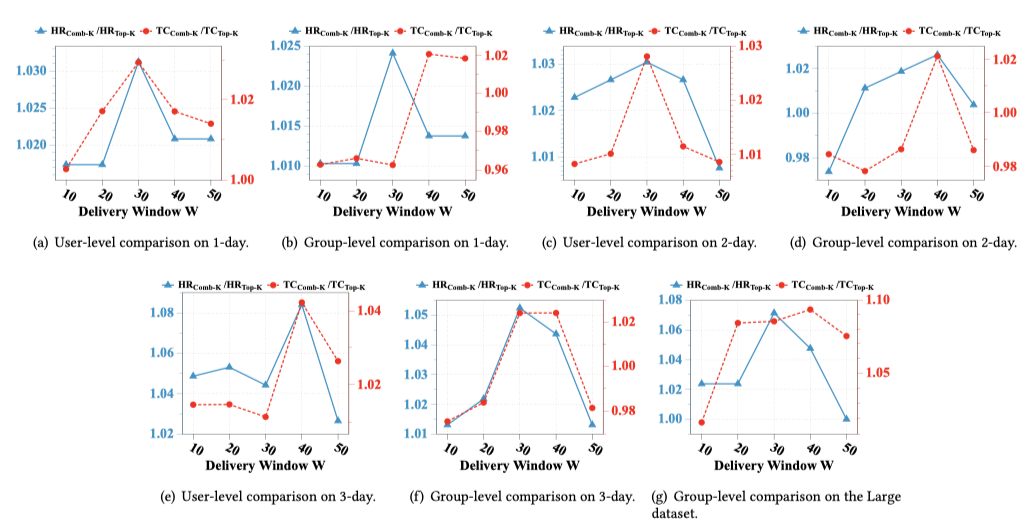
投放窗口作为一个核心超参数,极大的影响着模型的效果。
我们在用户和人群级别分别探索了不同窗口大小下模型的效果。
当窗口大小设置为30-50的时候,comb-K通常可以取得明显的提升。
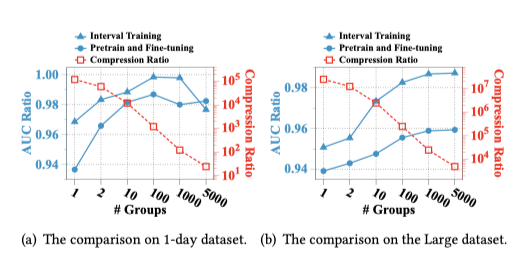
本节旨在评估人群偏好和用户偏好的差异,如下图所示。这里我们测试了不同P和训练策略对模型效果的影响。可以看出,当P足够大的情况下,人群偏好的效果非常接近用户偏好的效果。
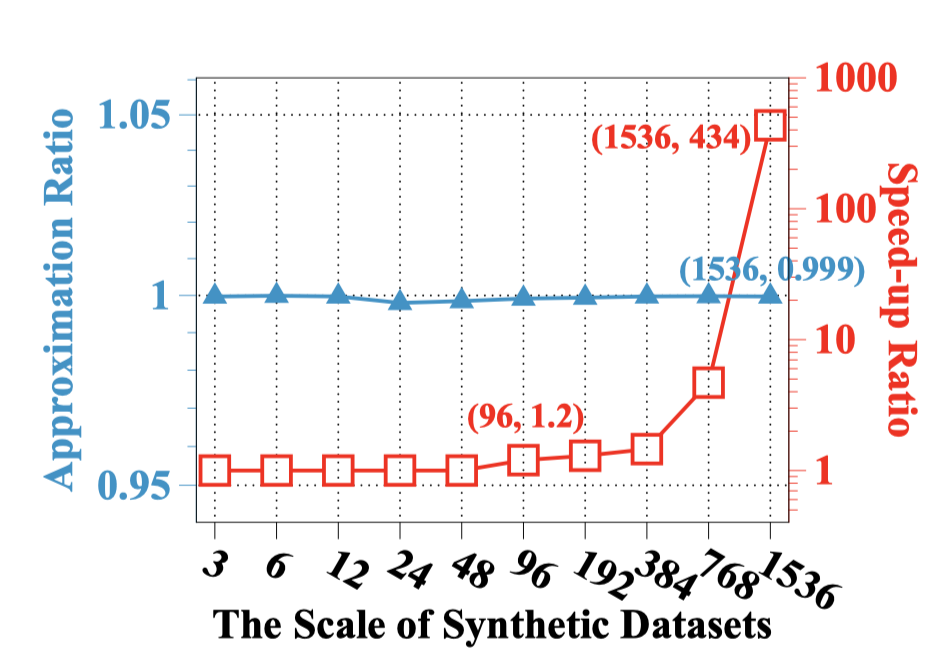
4.5 限制邻居搜索策略评估
最后,我们评估了快速求解策略的有效性和效率。我们在不同规模的仿真数据上进行了验证。可以看出,在不同规模问题上,限制邻居搜索策略都可以保持高精度的求解。随着问题规模的增大,限制邻居搜索策略的加速比会大幅度提升。
![]() 5 总结
5 总结
本文针对淘宝的聚划算业务建模了Comb-K推荐,其是一种带约束的组合优化推荐问题。具体而言,Comb-K推荐同时建模了商品选择和商品投放过程,进而最大化聚划算的真实收益。为了求解Comb-K问题,我们首先估计了用户偏好并设计了RNHS算法来求解组合优化问题。进一步的,为了解决海量用户带来的组合爆炸,我们将用户聚类为人群并在人群级别进行Comb-K问题的求解。最后,大规模真实数据集上的实验验证了Comb-K的有效性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源

 对比算法为经典的Top-K算法,具体包括DNN,GREE,MEIRec,IntentGC,HGRec。
同时,我们对现有算法进行了扩展,使其更好的实现选品过程,如MEIRec+Avg/Att,IntentGC+Avg/Att 和 HGRec+Avg/Att。我们的算法主要是用户级别和人群级别的Comb-K算法。评价指标为总点击量和命中率:
对比算法为经典的Top-K算法,具体包括DNN,GREE,MEIRec,IntentGC,HGRec。
同时,我们对现有算法进行了扩展,使其更好的实现选品过程,如MEIRec+Avg/Att,IntentGC+Avg/Att 和 HGRec+Avg/Att。我们的算法主要是用户级别和人群级别的Comb-K算法。评价指标为总点击量和命中率: