KDD 2021 | Neural Auction: 电商广告中的端到端机制优化方法
▐ 导读
论文下载:https://arxiv.org/abs/2106.03593
▐ 1 摘要
▐ 2 问题建模
2.1 多利益方博弈视角下的多目标电商广告机制设计
2.2 基于Value Maximizer的电商广告主建模
Definition (Value Maximizer). A value maximizer optimizes value while keeping payment below her maximum willing-to-pay ; when value is equal, a lower is preferred.
-
Monotonicity(单调分配):广告主上报了更高的报价不能拿到更差的分配结果; -
Critical Price(最小扣费):胜出广告的计费应为其拿到相同坑位的最低报价。
▐ 3 模型设计
-
集合编码器(Set Encoder),学习整个竞价队列的上下文信息,输出一个定义在竞价队列上的特征。 -
上下文评分函数(Context-Aware Rank Score Function),以单个广告的特征和竞价队列特征作为输入,学习每个广告的排序分数,并保障广告主的 IC/IR 性质。 -
可微排序引擎(Differentiable Sorting Engine),以竞价队列所有广告的排序分数为输入,以可微的形式进行排序操作,并进一步计算在当前排序分状态下的其他估计指标。
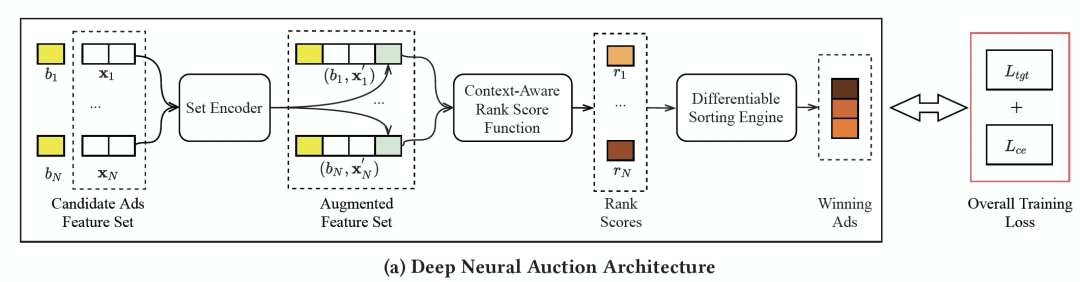
接下来将详细介绍这三部分模型设计和整体的训练方法。
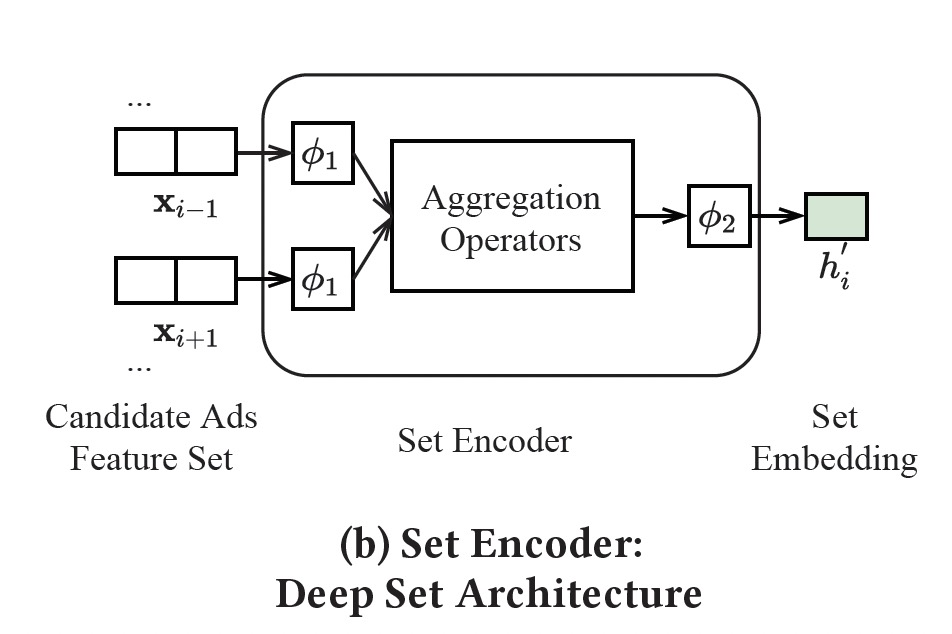
3.1 集合编码器(Set Encoder)
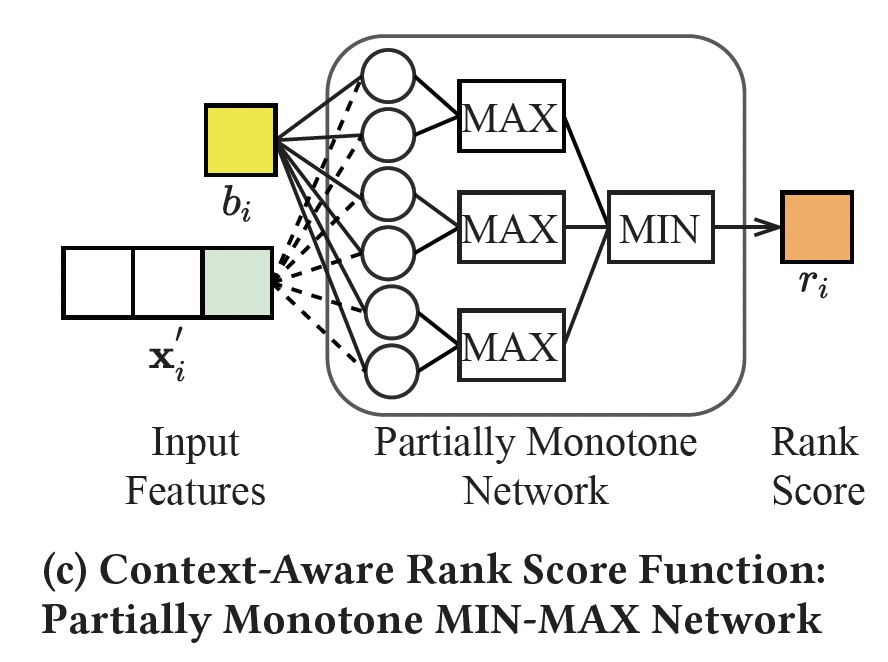
3.2 上下文评分函数(Context-Aware Rank Score Function)
3.3 可微分排序算子(Differentiable Sorting Engine)
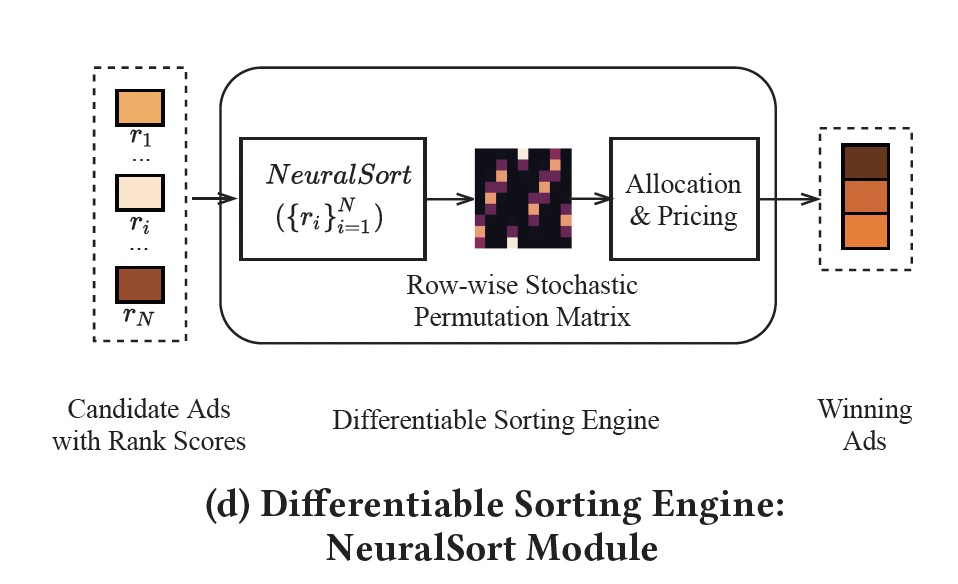
3.4 训练流程
3.4.1 样本构造:
3.4.2 训练 Loss
▐ 4. 实验效果
4.1 离线实验
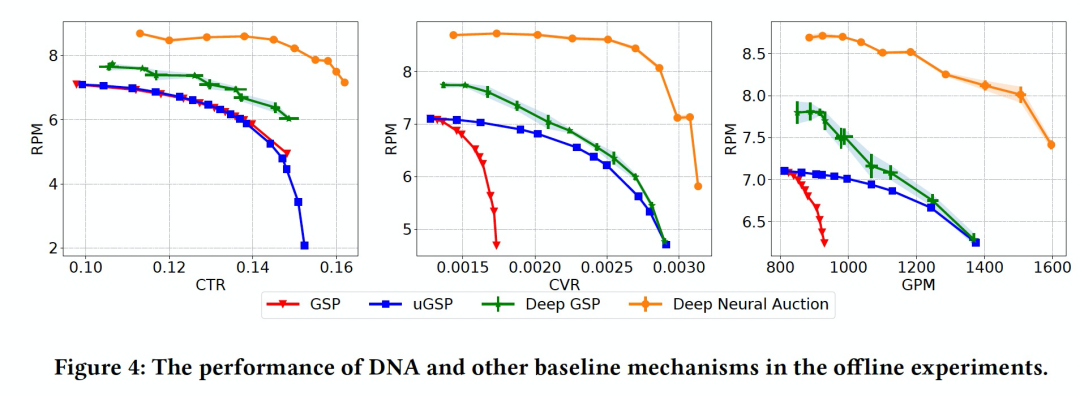
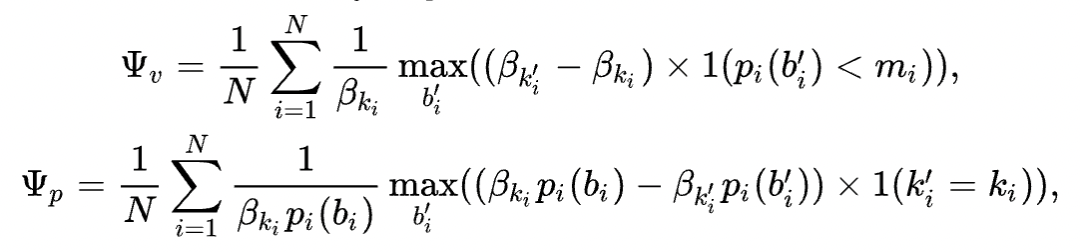
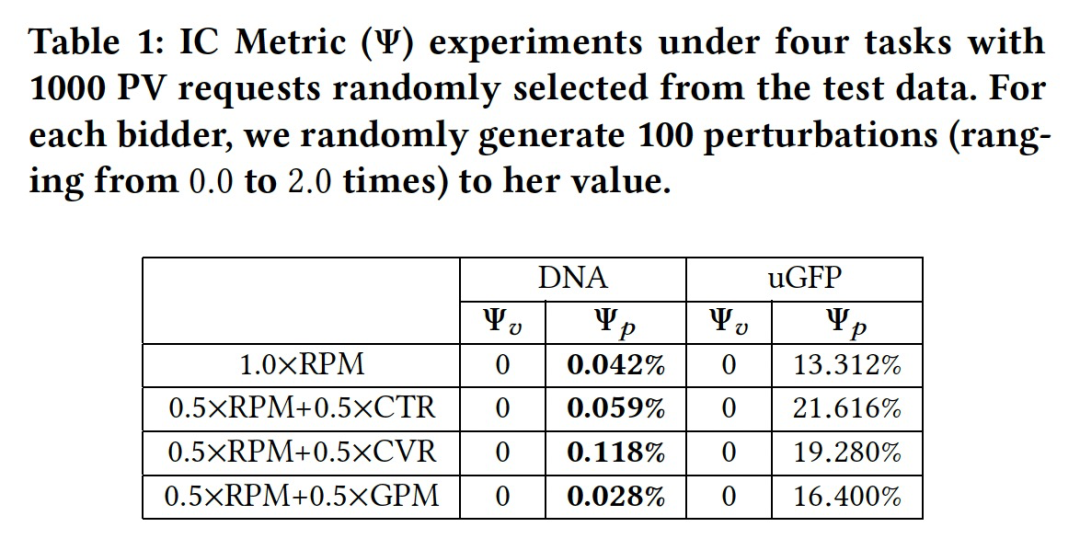
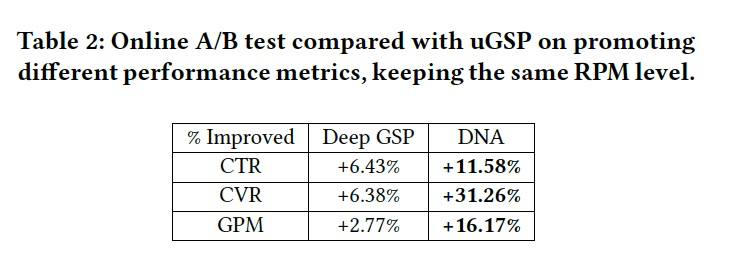
4.2 在线实验

▐ 5 总结与展望

登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文