AAAI2020-残差新特征学习方式 | 残差持续学习,大大提升分类精度(文末附下载链接)

计算机视觉研究院专栏
作者:Edison_G

关注我们 获取更多资讯
本次介绍一种新的持续学习方法,称为残差持续学习(ResCL)。 该新方法可以防止多个任务的顺序学习中的灾难性遗忘现象,除了原始网络之外,没有任何源任务信息。通过将原始网络的每一层和一个微调网络线性地结合起来,ResCL重新测量网络参数;因此,网络的大小根本不会增加。为了将该方法应用于一般卷积神经网络,还考虑了批归一化层的影响。通过利用类残差学习参数化和特殊的权重衰减,有效地控制了源性能与目标性能之间的权衡。该方法在各种持续学习场景中表现出最先进的性能。


一、背景及介绍

利用人工神经网络进行深度学习是目前最强大的人工智能技术之一。它在计算机视觉等各种机器学习领域表现出最先进的性能。然而,需要大量的训练数据和时间来训练网络结构变得复杂的深层网络。为了缓解这一困难,如 Transfer learning微调,用于利用源任务知识和促进目标任务的训练。
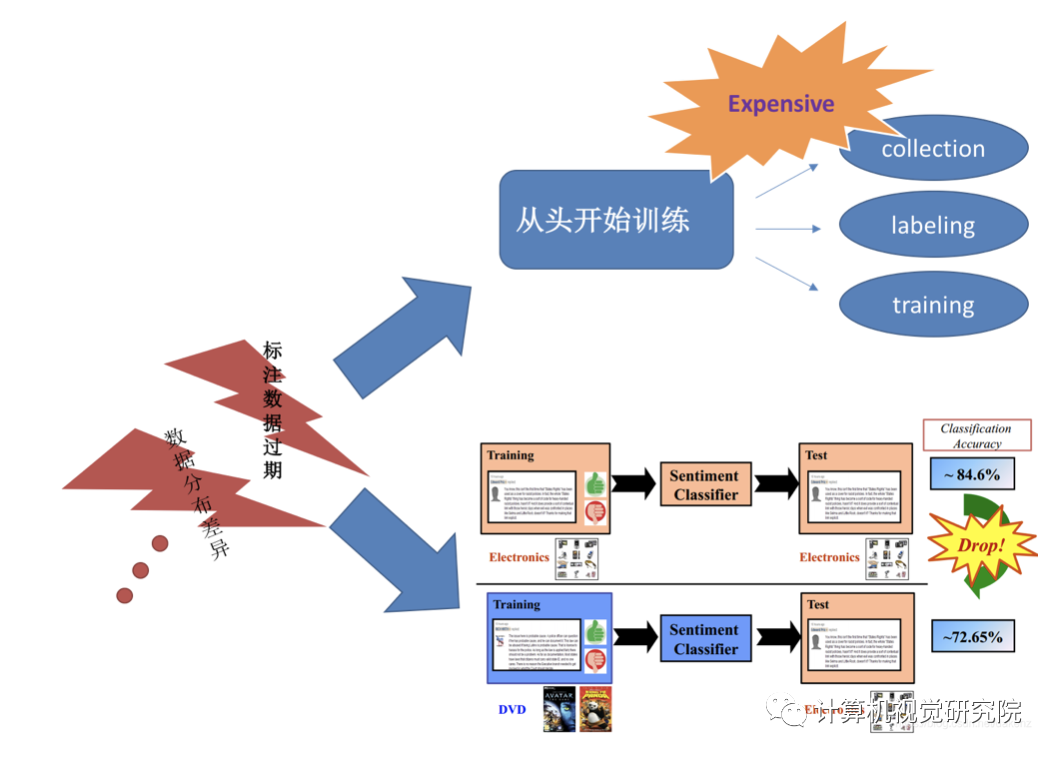
由于Transfer learning方法只考虑训练过程中的目标任务性能,因此大部分源任务性能被称为灾难性遗忘现象的副作用而丢失。如果源任务和目标任务都需要高性能,这是一个严重的问题。应采用连续学习的方法来解决这一问题。
本次分享的技术,作者就是在保持源任务性能的同时,实现良好的目标任务性能。具体来说,专注于卷积神经网络(CNNs)的图像分类任务。此外,为这个问题强加了两个实际条件。
首先,作者假设在目标任务训练期间没有源任务信息可用。在许多实际应用程序中,源数据往往太攀大,很难消化学习,无法处理或没有public license。如果有,联合训练源数据和目标数据将是一个更好的解决方案。

此外,作者还假设不仅没有源数据,而且也没有包含源任务信息的任何其他形式。最近关于持续学习的研究没有直接使用源数据,但它们经常引用有关源数据的部分信息,例如以生成对抗性网络的形式或Fisher信息矩阵,这在某种程度上稀释了持续学习的最初目的。
第二,网络的规模不应增加。如果没有这种条件,网络可以扩展,同时保持整个原始网络。这种网络扩展方法在源任务和目标任务中都表现出良好的性能,但在实践中很难将它们与深度神经网络一起使用,因为随着任务数量的增加,网络的规模变得更大。
主要特点如下:
Residual-learning-like reparameterization allows continual learning, and a simple decay loss controls the trade-off between source and target performance;
No information about source tasks is needed, except the original source network;
The size of a network does not increase at all for inference (except last task-specific linear classifiers);
The proposed method can be applied to general CNNs including Batch Normalization (BN) (Ioffe and Szegedy 2015) layers in a natural way;
二、新方法
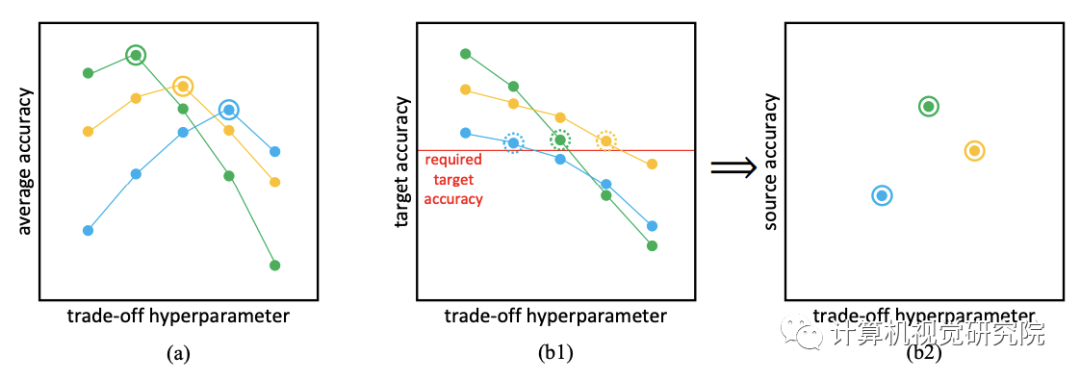
持续学习本质上是在两个任务之间达到一个很好的中点。一个简单的想法是将每一层源网络和目标网络线性地结合起来,以获得它们之间的中间网络,其中源网络是对源任务进行训练的原始网络,目标网络是从原始网络中为目标任务进行微调的网络。通过将它们结合起来,我们可以获得位于源和目标任务解决方案之间的网络。这个基本思想类似于IMM。
然而,线性组合网络的性能没有得到保证,因为神经网络不是线性的或凸的。因此,在两个网络组合后,对组合网络有一个额外的训练阶段,以确保它能够正常工作。由于额外的训练会损失源知识,所以在组合网络中应该冻结原始权重。在下文中,经常把源网络称为原始网络。
Linear Combination of Two Layers
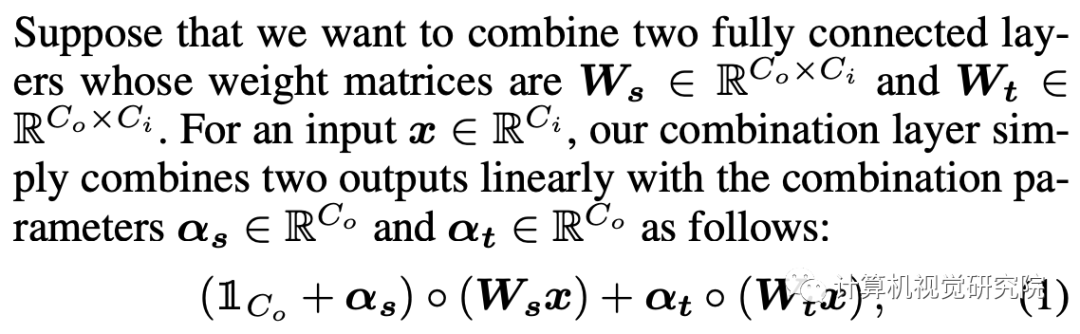
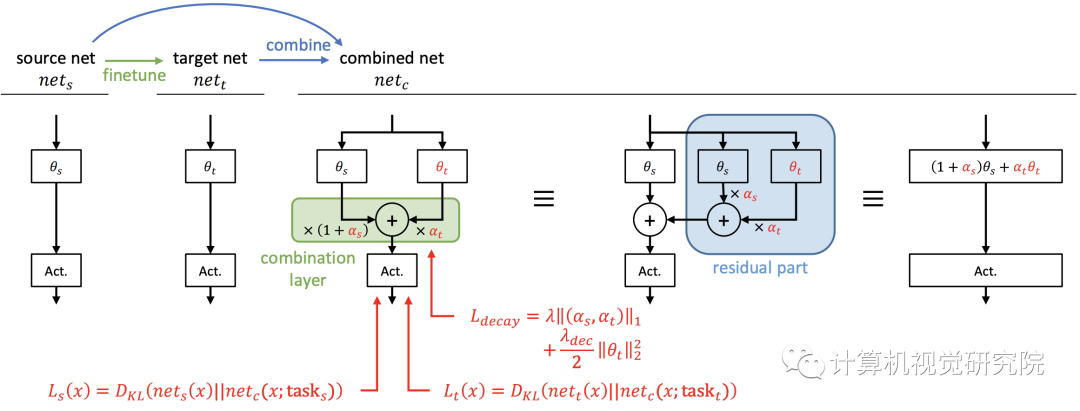
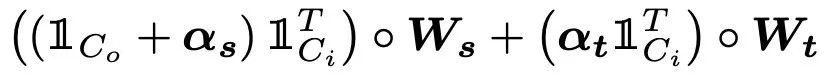
因为它们的线性,这就是为什么我们可以称新方法为一种类型的重新参数化;因此,一旦训练完成,网络的大小就不会增加用于推理。任何非线性层,如sigmoid或ReLU,不应包括在组合中,如上图和下图所示,否则,这些层不能合并为一个层;然后,随着任务数量的增加,网络大小增加。
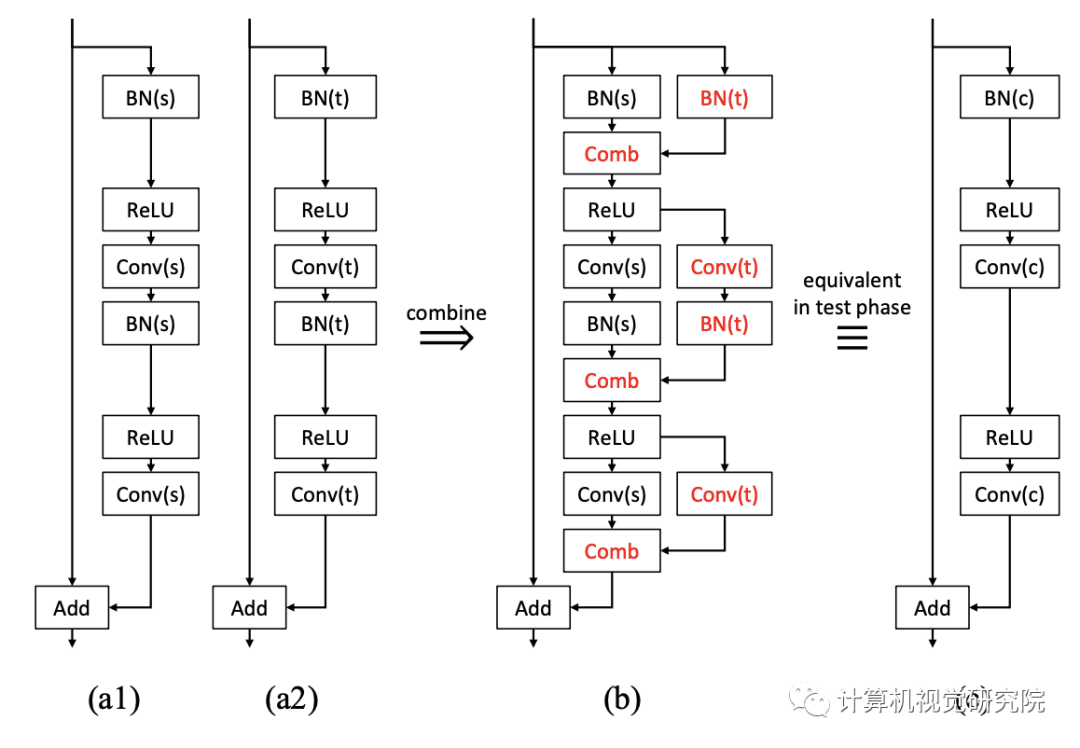
Train

Convolution and Batch Normalization
新提出的方法可以自然地应用于BN层。我们不需要担心分布的变化,因为每个子网都有自己的BN层来完成自己的任务。具体地,上图中的原始BN层应在额外的训练和测试阶段使用其源任务的统计。否则,一些源知识就会丢失,因为联合网络在额外的训练中无法看到和利用原始统计数据。具有组合层的两个BN和两个卷积层在训练后也可以合并成一个等效卷积层,因为BN层在推理阶段是确定性的线性层,卷积也是线性运算。
三、实验

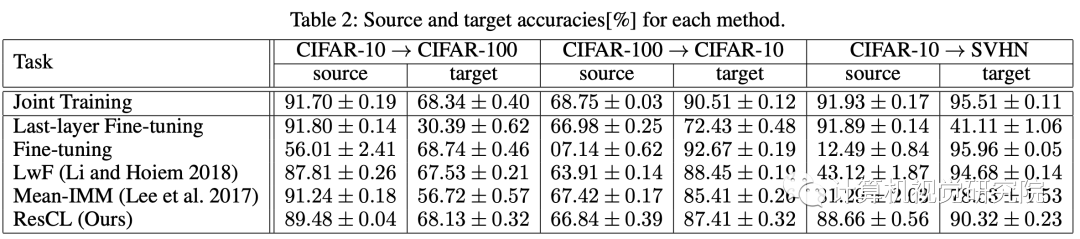
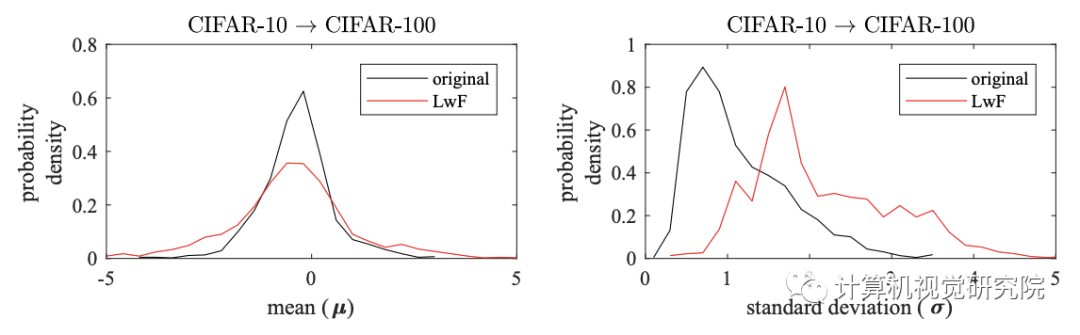
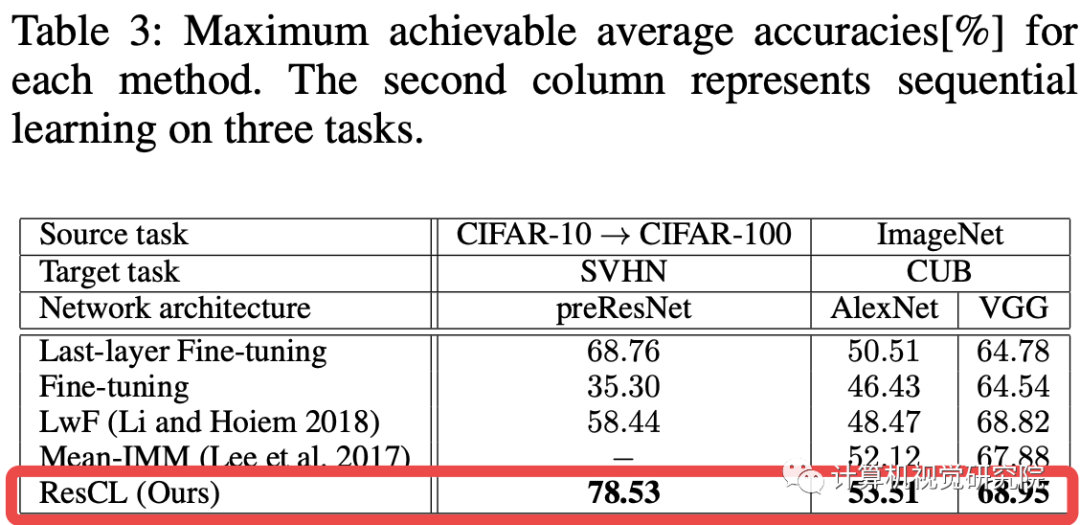
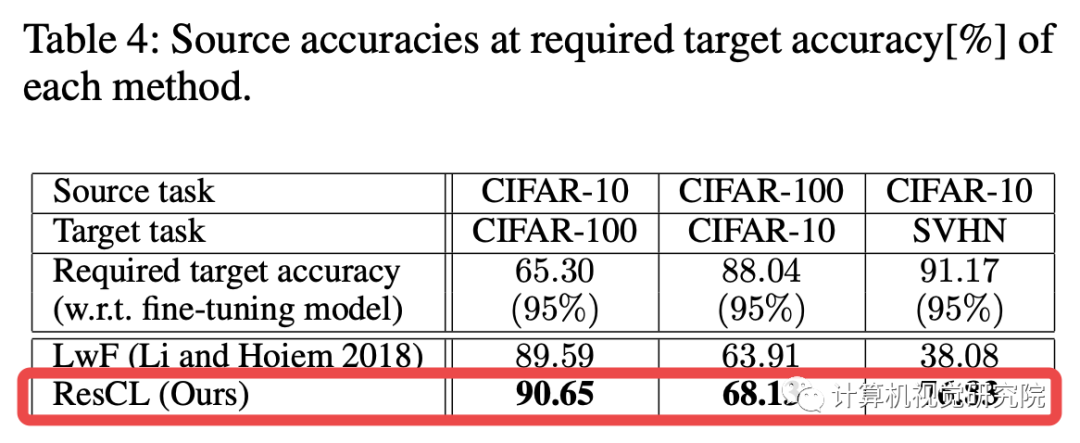
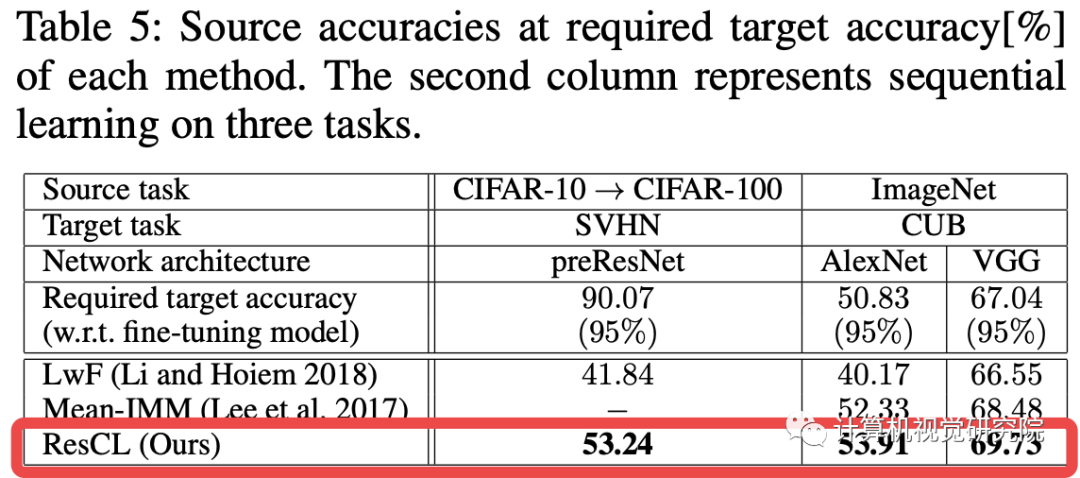
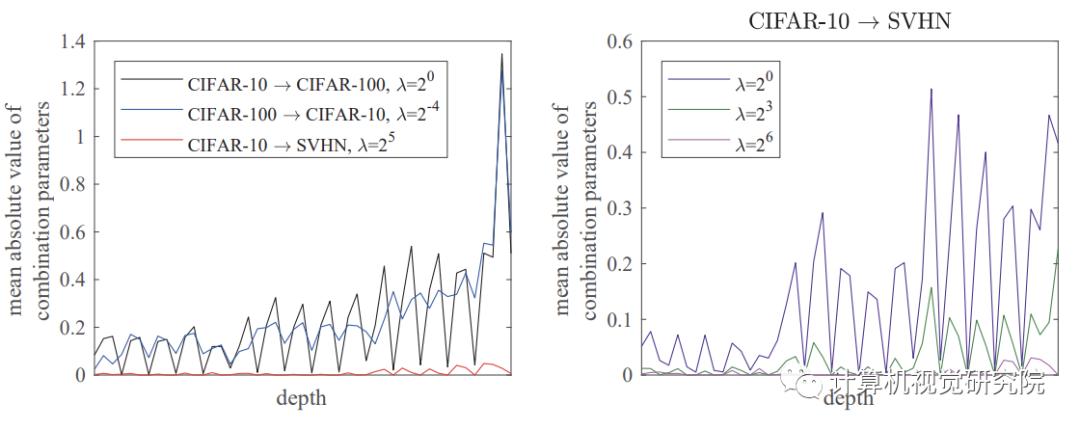
四、总结
/End.
关注我们 获取更多资讯


