赛尔译文 | 基础模型的机遇与风险 (六)
原文:On the Opportunities and Risks of Foundation Models 链接:https://arxiv.org/pdf/2108.07258.pdf 译者:哈工大 SCIR 张伟男,朱庆福,聂润泽,牟虹霖,赵伟翔,高靖龙,孙一恒,王昊淳,车万 翔(所有译者同等贡献) 转载须标注出处:哈工大 SCIR
编者按:近几年,预训练模型受到了学术界及工业界的广泛关注,对预训练语言模型的大量研究和应用也推动了自然语言处理新范式的产生和发展,进而影响到整个人工智能的研究和应用。近期,由斯坦福大学众多学者联合撰写的文章《On the Opportunities and Risks of Foundation Models》,将该模型定义为基础模型(Foundation Models),以明确定义其在人工智能发展过程中的作用和地位。文章介绍了基础模型的特性、能力、技术、应用以及社会影响等方面的内容,以此分析基于基础模型的人工智能研究和应用的发展现状及未来之路。鉴于该文章内容的前沿性、丰富性和权威性,我们(哈工大 SCIR 公众号)将其翻译为中文,希望有助于各位对基础模型感兴趣、并想了解其最新进展和未来发展的读者。因原文篇幅长达 200 余页,译文将采用连载的方式发表于哈工大 SCIR 公众号,敬请关注及提出宝贵的意见!

-
引言 -
能力 -
应用 -
技术 -
社会 -
结论
4.技术
在这一节中,我们讨论基础模型在分布变化鲁棒性中所扮演的角色。一个基础模型在采样自分布 的大量不同的无标签数据集上进行训练,然后可以被适配到许多的下游任务中。对于每一个下游任务 ,基础模型在带标签的从训练分布 中采样的分布内(in-distribution, ID)训练数据上进行训练,然后在分布外(out-of-distribution, OOD)的测试分布 上进行评价。例如,一个贫困地图预测模型 [Xie et al. 2016; Jean et al. 2016] 可以在全世界的无标签卫星数据中学习所有国家的有用特征,然后在带标签的来自尼日利亚的样例上进行微调,最终在缺乏带标签样例的马拉维上进行评价。
我们认为:1)基础模型在鲁棒性方面是一个特别具有前途的方法。现有工作表明了在无标签数据上进行预训练是一种有效的、通用的提高在 OOD 测试分布上准确性的方法,这与限制于有限的分布变化的许多鲁棒性干预措施相反。然而,我们同样讨论了 2)为什么基础模型可能无法总是应对分布变化,例如某些由于伪相关性或随时间改变的分布变化。最后,3)我们概述了几个利用和提高基础模型鲁棒性的研究方向。
我们注意到,基础模型提高下游任务性能的一个方法是为适配模型提供归纳偏置(通过模型初始化),这些偏置是在下游训练数据之外的多种数据集上学习得到的。然而,同样的归纳偏置也可能从预训练数据中编码有害关联,并在分布变化的情况下导致表示和分配危害。关于这些危害和缓解办法的进一步讨论,请阅读§4.6: 数据和§5.1: 公平性。
4.8.1 优势
通过在大量且多种的基础模型训练分布 上学习表征,基础模型可以提高其在下游测试分布 上的准确性。OpenAI 的 CLIP 模型是一个在多种图像和自然语言数据集上训练的基础模型,被证明对于 ImageNet [Radford et al. 2021] 上的一类分布变化具有鲁棒性:例如,CLIP 和标准的 ResNet50 在 ImageNet 上都可以取得 76% 的准确率,但是 CLIP 在ImageNetV2[Recht et al. 2019] 和 ImageNet Sketch [Radford et al. 2021] 上分别取得 6% 和 35%的更高的准确率,这两个数据集都与原始的 ImageNet 训练分布相关但也存在不同。相反,许多其他的鲁棒性干预措施,例如:对抗训练 [Madry et al. 2018]、不变风险最小化 [Arjovskyet al. 2019] 或使用更大的模型,对于这些 ImageNet 任务的有效鲁棒性(指分布内和分布外间的性能差距)影响不大,尤其是在没有关于分布变化的显式知识的情况下 [Taori et al. 2020;Santurkar et al. 2020; Radford et al. 2021; Miller et al. 2021]。
许多其他工作表明,在大规模数据集上的预训练可以提高对于常见图像损坏、标签移位和标签损坏 [Hendrycks et al. 2019a,b]、卫星图像任务中的自然地理变化 [Xie et al. 2021a]、自然语言理解任务中的跨主题变化 [Hendrycks et al. 2020; Fisch et al. 2019; Yogatama et al. 2019] 的鲁棒性。再举一个例子,将基础模型在多语言数据上进行训练(就像 multilingual BERT [Liuet al. 2020b] 中那样)可以显著提高其在没有见过的语言对上的表现。
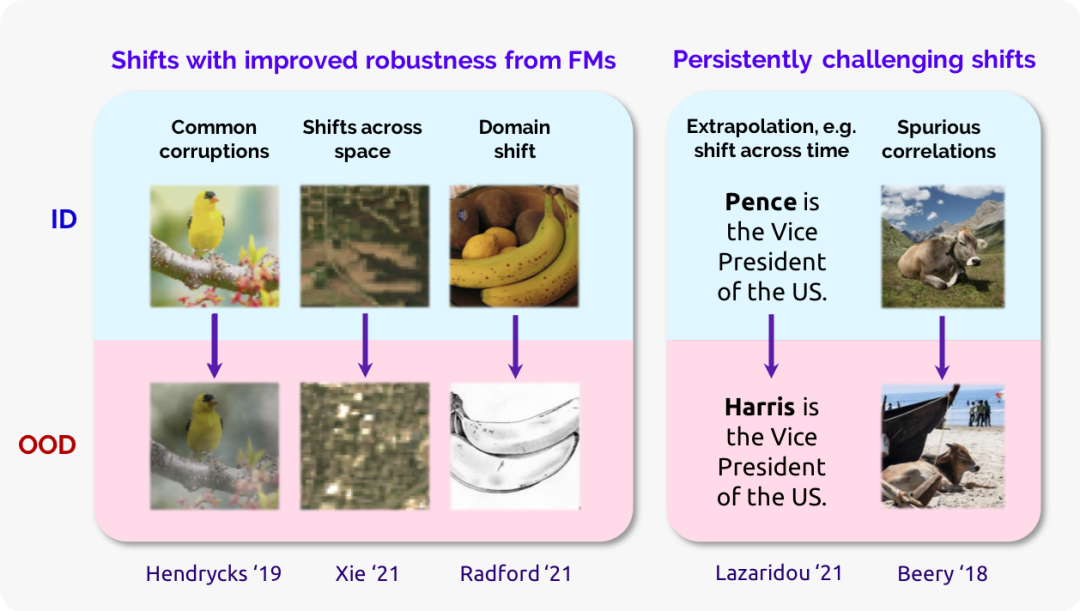
4.8.2 持续的挑战
尽管有显著的迹象表明基础模型将会导致导致鲁棒性的显著提升,我们也预见到基础模型不是解决分布变化的万能钥匙。我们将在两大类分布变化的背景下讨论这一点。
伪相关 伪相关指特征和标签仅在训练分布上具有统计相关性,而在测试分布上却不存在 [Heinze-Deml and Meinshausen 2017; Arjovsky et al. 2019; Sagawa et al. 2020a]。广为人知的例子包括目标检测中对于背景颜色的依赖 [Xiao et al. 2020]、医疗诊断中的手术标记物 [Winkler et al. 2019]、众包数据中的标注者偏差 [Tsuchiya 2018; Gururangan et al. 2018;Poliak et al. 2018; Geva et al. 2019] 以及人口统计偏差 [Abid et al. 2021; Nadeem et al. 2021;Gehman et al. 2020]。基础模型之所以会学习到这些伪相关主要是由于基础模型的训练和适配数据中显示出了这种偏差 [Nagarajan et al. 2020; Gehman et al. 2020],该问题无法通过使用更大的模型简单地解决 [Sagawa et al. 2020b]。
基础模型可能会加剧或者减轻伪相关的影响,但这取决于特定下游任务的性质以及其与基础模型训练数据和算法的关系。通过在多种数据集上进行训练,基础模型可以提高其对于仅出现在部分训练数据上的伪相关的鲁棒性,例如:目前的研究发现预训练的语言模型可以通过快速学习伪相关的反例从而避免伪相关 [Tu et al. 2020]。然而,基础模型也可能由于训练数据中的偏差而加剧伪相关问题,例如在 GPT-3 和其他 NLP 模型中观测到人口统计偏差 [Abid et al. 2021; Nadeem et al. 2021; Gehman et al. 2020]。而且,仅仅通过大规模训练仍然无法做到找出并避免依赖那些仅存在于训练数据而不存在于测试数据的特征。[Heinze-Demland Meinshausen 2017]。为了解决这些挑战,我们需要理解并管理来自于模型训练的归纳偏差,并开发出对伪相关有抵抗力的适配算法。
外推与时间漂移 最后,基础模型的小样本和零样本学习能力意味着它们将越来越多地被应用在训练分布之外。虽然大规模的基础模型训练有助于外推到特定形式的新分布中 [Papadimitriou and Jurafsky 2020],但基础模型的外推能力可能仍然存在限制。例如,现存的语言模型如果不经过重新训练就无法应对世界知识或语言的改变 [Lazaridou et al. 2021;Dhingra et al. 2021],CLIP 的零样本迁移在卫星图像领域效果很差 [Radford et al. 2021],在ImageNet 上的预训练无法显著提高大模型在医学影像上的表现 [Raghu et al. 2019; Ke et al.2021]。我们认为不能假设基础模型可以自动地外推到给定模态(例如:所有的图像),定义和区分哪些外推形式能够通过基础模型实现以及哪些仍然不能变得越来越重要。尽管现存的对于分布变化的分类标准比较笼统 [Quiñonero-Candela et al. 2009; Ye et al. 2021],充分理解和定义基础模型能够应对的分布变化类型是鲁棒性研究的一个主要开放问题。
4.8.3 机遇
基础模型作为应对分布变化的通用鲁棒性干预措施具有重大的前景,其也为鲁棒性研究开辟了道路。我们接下来概述其中的一些机遇和开放问题。
理解基础模型表示 现存的关于基础模型鲁棒性的研究大多是基于经验的,对于鲁棒性提升背后的原理知之甚少。Sun et al. [2019b] 等人认为预训练表示使得不同的域(例如 ID 和 OOD分布)彼此靠近,这反过来提高了从带标签的 ID 数据到 OOD 数据的泛化表现 [Ben-Davidet al. 2010]。测量使用和不使用预训练的域表示间的距离的受控实验可以证明这一作用。在表征基础模型训练(例如:作为图谱分解的对比学习 [HaoChen et al. 2021a])及其归纳偏差 [Saunshi et al. 2020a; Lee et al. 2020a; Zhang and Hashimoto 2020; Xie et al. 2020] 方向上取得了初步的成果。然而,这些理论是受限的,且不适用于其他经验上有效的基础模型,例如完全生成式的语言模型(例如:GPT3 [Brown et al. 2020] 和 image-GPT [Chen et al. 2020d])。对于归纳偏差在分布变化下如何起作用的进一步理解将会使得关于基础模型如何提高鲁棒性的理论(§4.10: 理论)更加完备。
基础模型训练中的数据增强 尽管不使用下游任务知识训练基础模型可以避免某些特定任务偏差并往往能够提高鲁棒性,然而源于基础模型训练方式的统计偏差可能仍然存在。举一个具体例子,许多现代的自监督算法严重依赖于选择合适的数据增强集合 [Chen et al. 2020c],这反过来在适配阶段赋予基础模型不同类型的鲁棒性:Xiao et al. [2021] 证明了用于视觉的基础模型在旋转增强上进行对比学习训练可能会提高其在具有旋转不变性的适配任务上的OOD 表现,但对于需要其他不变性的 OOD 泛化任务可能无法提高鲁棒性。更进一步的研究关于哪些类型的数据增强可以广泛提高下游任务的鲁棒性——包括从数据中学习的数据增强 [Wong and Kolter 2020; Tamkin et al. 2021b] 或可以普遍使用的跨模态数据增强 [Vermaet al. 2021]——将会带来更好的基础模型训练算法 (§4.2: 训练)。
基础模型训练中的编码结构 一般而言,探索对数据中的已知结构和不变性的新编码方式是基础模型发展的重要路径。许多现实世界的任务具有额外的元数据(例如:空间位置坐标、贫困地图中的来自辅助卫星的气候信息),这或许能够为在 OOD 上的泛化提供了额外信息(例如:跨地理区域)[Xie et al. 2021a; Koh et al. 2021]。例如,Xie et al. [2021a] 证明了元数据可以被用作预训练目标来提高下游 OOD 上的准确率。在语言领域,对 HTML 数据中的标签进行建模提供了额外的下游任务相邻监督信号,这使得新的提示形式(例如:填写 <title>标签来获得标题建议)成为可能,并提高了数据有效性 [Aghajanyan et al. 2021]。尽管目前的数据增强方法对手工构造的知识进行编码,但像利用元数据这样的其他的方法可以提供一个更加自动的方式来决定哪些结构和不变性应该被包含到基础模型训练中。
专门化 vs 基础模型训练数据中的多样性 对基础模型训练数据的选择会对下游任务产生影响——在更多的数据集上进行预训练得到的基础模型的下游任务表现并不总是强于一个更加专门化的基础模型 [Cole et al. 2021; Chalkidis et al. 2020](更详细的讨论见§4.3: 适配)。在一些诸如卫星影像和专门文本话题的领域中,在专门领域上进行连续预训练可以显著提高下游任务的表现 [Reed et al. 2021; Gururangan et al. 2020]。这是矛盾的一个来源:一方面,我们希望在更大且更多的数据集上训练基础模型以提高其面对分布变化的鲁棒性,而另一方面,我们又需要使基础模型专门化来提高其在下游任务上分布内和分布外的表现。如果我们能够更好的理解专门化是如何影响基础模型在分布和分布外表现的,那么我们就可以设计和收集更加有效的基础模型训练集。
适配方法 尽管基础模型提供了一个良好的起点,适配方法如何利用预训练信息将影响鲁棒性。例如,针对语言模型的轻量调整方法(例如:适配器/前缀/提示调整 [Houlsby et al.2019; Li and Liang 2021; Lester et al. 2021]),其在将模型适配到新任务时只优化一小部分参数(如一个连续的提示),同时保持模型的其他的参数不变,这看起来会使 OOD 的表现受益(§4.3: 适配)。Xie et al. [2021b] 用一个特例对此进行解释:用一个冻结的基础模型作为整体模型的一部分可以降低整体模型的复杂度,从而同时提高在 ID 和 OOD 上的泛化能力。然而,总的来说对于为什么冻结的参数可以提高 OOD 表现的理解还不够。最后,虽然当前的适配方法可能足以得到好的 ID 泛化,但是它们并没有显式的考虑分布变化。作为第一步,我们可以研究像领域适配、领域泛化、半监督学习这样的针对分布变化的方法如何与基础模型的适配过程相结合。这些方向上的进展将使得适配方法可以更好的利用基础模型实现鲁棒性。
4.9 AI 安全
Authors: Alex Tamkin, Geoff Keeling, Jack Ryan, Sydney von Arx
人工智能(AI)安全领域关注先进 AI 模型可能导致的意外、危害和风险,尤其是社区或社会所面临的大规模风险。目前的基础模型可能距离造成这样的风险还很远,然而,它们的能力和可能的应用范围的广度是惊人的,这也是相较于之前机器学习范式的明显转变。尽管 AI 安全在 AI 研究的历史上一直处于边缘位置,但目前向基础模型的过渡以及基础模型的通用性为 AI 安全的研究者提供了一个机遇,他们可以从新的角度重新审视该领域的核心问题,并重新评估这些问题在现在或不久的将来的相关性。2
2 浏览Amodei et al. [2016] 和Hendrycks et al. [2021d] 从而以更开阔的角度看待 AI 安全中的开放问题
4.9.1 AI 安全领域的传统问题
AI 安全的重要分支之一关注先进 AI 系统可能带来的影响,包括那些在可能在各种认知任务上达到或超过人类水平的系统 [Everitt et al. 2018]。3在该背景下的安全研究的核心目标是降低由先进 AI 发展所带来的大规模风险。4这些风险相比起§5.2: 滥用、§4.8: 鲁棒性和§4.7: 安全性中讨论的风险更加具有推测性。然而,它们的规模要大得多,且至少原则上是由未来的高能力系统导致的。其中尤其令人担忧的是全球灾难性风险:粗略地来说,就是那些作用范围是全球或者跨代的,能够导致死亡或以其他形式显著影响人类福祉的风险(例如:核战争或快速的生态崩溃)[Bostrom and Cirkovic 2011]。AI 安全研究就是一系列的项目,它们旨在找出由先进 AI 发展带来灾难性风险,并开发出合理的技术解决方案来降低这些风险的发生概率或带来后果的严重性。从人工智能的角度来看,最佳情况是找到一种控制问题的解决方案:如何开发一个先进的 AI 系统,使得我们在享受其带来的计算收益的同时让我们拥有足够的控制权,从而避免系统的部署带来全球性的灾难 [Bostrom and Cirkovic 2011]。然而技术解决方案不足以确保安全性:我们能够确保安全的算法是那些已经被应用到现实世界系统的算法,为了保证那些未被部署的系统的安全性可能需要额外的社会技术评估与制度。强化学习研究针对奖励优化的决策代理,是 AI 安全研究过去十年的焦点。其中的问题在于如何为 AI 指定并实例化一个与人类价值观一致的奖励函数,且在最小意义上不能造成全球灾难性威胁。5这个问题被称为价值对齐(value alignment)[Gabriel 2020; Yudkowsky2016],其第一眼看上去可能显得微不足道,但人类的价值观是多样的、6无形的且难以定量捕捉的。因此,一个突出的问题就是奖励入侵(reward hacking),即 AI 为人类福祉找到一个未被预见的策略来最大化代理奖励,但错误的指定会导致重大的损害。7针对价值对齐问题的许多努力集中在最大化可纠正性,即系统一旦运行就可以纠正系统设计中的错误[Soares et al. 2015]。这可能听上去不怎么直观——在强化学习中,具有特定目标的代理会通过物质激励来禁止修改目标的尝试,因为任何对目标修改的尝试对于目标的实现来说都可能是次优化的 [Omohundro 2008]。
3 这也被一些人称为 AGI 或通用人工智能,尽管使用的术语不同 [例如:见 Karnofsky 2016]
4 请注意,这不需要认为构建特定类型的先进 AI 是追求的目标,甚至不需要认定其是可实现的
5 阅读Hubinger et al. [2019] 来了解关于奖励指定和奖励实例化间阈值所带来的挑战的讨论
6 阅读Gabriel [2020] 来了解关于人类多样性、伦理以及价值对齐问题的拓展讨论
7 阅读这个电子表格来了解现实世界中的奖励侵入案例列表, 其中包含一个飞机着陆算法,其利用模拟器的漏洞取得了最高的得分
然而,纯粹的强化学习并不是实现先进 AI 的唯一理论路线。基础模型也可以通过下一标记预测(next-token prediction)这样简单的(自)监督目标进行训练,无论是否有额外的强化学习训练,都可以以交互和目标导向的方式被使用。此外,这些方法中有许多可以直接通过增加计算、参数量和数据集大小来提高能力 [Hestness et al. 2017; Kaplan et al. 2020]。在更加广阔的基础模型背景下,价值对齐和可纠正性在一些方面与在纯粹的强化学习情况下不同,因此必须小心的构建理论。
4.9.2 目前的基础模型和 AI 安全
强化学习背景下的许多风险来自于为了实现目标而进行的模型优化。然而,近期关于基础模型的 AI 安全研究的核心挑战是尽管没有明确针对目标进行优化,但仍可能会出现目标导向行为(另请参阅§4.2: 训练)。例如,大型的语言模型可能在语料库上进行训练,其中代理以目标导向的方式使用语言,例如有说服力的文本。为了能够很好地预测下一个标记,模型可能会获得推理和产生论据的一般能力,这可能会出现在合适的上下文中。在其他种类的人类数据上进行训练的基础模型可能会捕捉到其他类型的目标导向的行为。例如,被训练来模仿人类的机器人代理,其训练数据中如果包含拳击比赛的视频,则有可能会尝试击倒它们的人类操作员。近期的工作还尝试直接训练代理来产生目标导向的行为;例如,DecisionTransformer 在带有返回值的轨迹上训练一个序列模型 [Srivastava et al. 2019; Schmidhuber2019; Chen et al. 2021b]。然后就可以通过高回报“提示”模型以获得高回报轨迹,这也提出了与强化学习中奖励侵入类似的问题。
然而,针对目标导向的模型在安全研究中的主要目标是对于代理所追求的行为有原则性的控制且可以做出解释,而不是依赖于黑箱神经网络做出的不可预测的决策。8这使得目前的基础模型成为了 AI 安全研究的一条令人兴奋的道路,因为将它们对齐可能是将更先进模型对齐的有用的前驱 [Christiano 2016; Cotra 2021; Kenton et al. 2021]。其中的一个挑战是基础模型的训练目标与预期行为的错位;例如,一个语言模型在训练阶段会不考虑真实性地在所有文档上预测下一个单词,但是用户可能希望模型只输出真实且有帮助的文本。引导目标导向的代理朝向期望行为的一种可能的方法是在它们训练的过程中引入对于行为的自然语言描述——这在使用语言来引导它们的同时也使得它们可以输出可解释的语言来描述它们所“相信”的自身正在执行的任务,这与用于可控生成和来源归属 [例如:[Keskaret al. 2019],另请参见:§2.3: 机器人学、§2.5: 交互和§4.11: 可解释性] 的方法类似。然而,还需要更多的进展来确保这些模型在自然环境下的可靠性和自洽性(§4.8: 鲁棒性),以及对这些模型的运作方式有更加机械学的理解 [[Cammarata et al. 2020],另请参见:§4.11: 可解释性]。即使未来的基于自然语言控制的基础模型使得更好的任务说明和监控成为可能,模型也可能会从人类数据中习得欺诈或其他的不良行为——识别并中和这种行为是未来研究的另一个重要方向。
8 关于理解和语义的更多关联,请阅读 §2.6: 哲学
尽管上一段描述的自监督训练目标使得基础模型从数据中捕捉人的行为,新的训练范式可能会产生能够在复杂环境中执行各种任务的目标导向的基础模型,并在不同领域展示出相较于人类的优越性 (参见§4.2: 训练)。例如,目标导向的基础模型可以在类似于 AlphaGo的开放式自我对弈设置中或者大量多任务单代理的强化学习设置中进行训练。这可能会导致新兴能力的出现,通过复杂的尝试使得代理达成目标,尤其是许多代理与丰富的世界模拟程序一起训练,这激励了欺骗、误导、伪装、说服以及战略规划能力的发展。除了抑制欺骗行为外,如何有效的评估和控制强大的模型的行为也尚不明确,这被称为可扩展的监督或对齐(scalable oversight or alignment)[Amodei et al. 2016; Leike et al. 2018];例如,对化学基础模型提出的新反应进行打分(参见:§4.4: 评价)。因此,用于训练、引导、监控和理解这些模型的新的人在回路(human-in-the-loop)方法也是令人激动的未来研究方向。
最后,即使是在任何更加先进的能力涌现之前,近期 AI 安全的一个重要研究领域是表征和预测目前自监督基础模型的能力。有三个方面使得其具有挑战性。第一,基础模型的一般性意味着它们可以以无数的未被预见的方式在应用中被使用。枚举使用基础模型的目前的和计划的应用不足以捕捉基础模型的所有可能的应用方式。第二,即使对于特定的应用来说,基础模型的能力也在不断涌现:随着模型的扩展,它们以意想不到的方式增加和改变。例如,通过“提示”来控制 GPT-3 就是一种涌现的现象,这在较小的 GPT-2 模型中只能看到最明显的一瞥 [Radford et al. 2019; Brown et al. 2020]。未来的基础模型会涌现出什么样的属性是未知的。第三,即使限定了应用和模型规模,模型的能力也是难以表征的。例如,一旦将逗号加入到输入中,GPT-3 做加法的能力就会显著提升 [Branwen 2020; Brockman 2020]。同样的,对于提示的小的改写可以对下游任务产生很大的影响。由于提示的空间是无法穷举的,明确断定任何任务在当前基于提示的基础模型处理范围之外都是具有挑战性的——这也是推断基础模型所带来的可能的灾难性风险中的主要挑战。
4.9.3 未来基础模型带来的潜在的灾难性风险
目前模型广泛且快速增长的能力表明了尝试从更加先进的系统中表征可能的灾难性风险是有好处的。我们发现基础模型至少可以通过两种方式导致灾难性的风险。
灾难性的鲁棒性故障 §4.8: 鲁棒性中讨论了模型在面对新类型的数据时可能会有出乎意料的或有害的表现 [Amodei et al. 2016; Yudkowsky et al. 2008]。如果重要的系统集成了基础模型,并利用模型的能力来适配不同的任务和情况,那么这种故障的后果将尤为严重。如果故障发生在战争系统(导致不必要的武器发射,可能引发冲突)、关键基础设施(关键能源或农业功能的意外破坏)、经济活动(意外失败可能会导致生活水平突然崩溃和政治不稳定;另请参见:§5.5: 经济)中,那么将会是灾难性的。实际上,灾难性的鲁棒性故障的风险相比起其他种类的人工智能,特别与基础模型相关。这是由于基础模型由单一模型组成并在许多场景中使用,因此模型习得的统计关联中的鲁棒性故障在原则上可以在多个领域以相关联的方式显现出来。如果同一个基础模型被集成到了多个关键的职能部门中,那么缺乏鲁棒性的模型可能会导致跨越多个职能部门的相关故障。
错误指定的目标 基础模型的使用可能会导致“优化一个错误但容易描述的目标”这一风险提高,这通常被称为 GoodHart 定律 [Kenton et al. 2021; Goodhart 1984]。一个当前的例子是这些风险对于某些推荐系统产生了负面影响(例如:两极分化、媒体成瘾),其简单地对用户参与度这一指标而不是更难衡量的社会和消费者的福祉进行优化 [Burr et al. 2018; Milanoet al. 2020]。未来的机构可能会利用无法解释的基础模型来最大化利润或 GDP 这样的简单指标,因为基础模型具有解决这些指标所依赖的许多不同的子问题的能力。然而,在更大规模中优化这些代理指标而不是为全人类福祉设计全面的目标将会在无意中导致对环境和地缘政治的损害 [Gabriel 2020; Creel and Hellman 2021]。
4.9.4 结论
大体上,我们认为目前的以及未来可能涌现的基础模型的属性使其成为了 AI 安全领域的成熟的研究对象。我们鼓励未来对于基础模型能力和风险的准确表征和预测的研究;鼓励设计新的方法来将基础模型与人类价值观和良好行为对齐;鼓励各州、研究实验室、企业进行主动的协作来缓解突出的风险。
4.10 理论
Authors: Aditi Raghunathan, Sang Michael Xie, Ananya Kumar, Niladri Chatterji, Rohan Taori, Tatsunori Hashimoto, Tengyu Ma
严谨的数学理论在许多工程与科学学科中扮演着基础角色(例如:电气工程中的信息论),我们认为基础模型理论对于引导技术决策和创新都非常有帮助,因为基础模型的实验与庞大的计算开销相关。此外,理论的见解有助于阐明基础模型的局限性并解释令人吃惊的经验现象。然而,尽管近期取得了很多进展,目前社区对于基础模型理论方面的理解仍十分有限 [Arora et al. 2019b; HaoChen et al. 2021a; Wei et al. 2021, 2020b; Zhang andHashimoto 2021; Saunshi et al. 2020b; Dao et al. 2019; Tosh et al. 2020, 2021; Cai et al. 2021; Leeet al. 2020a; Zimmermann et al. 2021; Bansal et al. 2020; Wang and Isola 2020; Tsai et al. 2020; Tianet al. 2020a,b; Tripuraneni et al. 2020; Du et al. 2020]。
深度神经网络构成了基础模型的支柱,即使是在已经被充分研究的有监督学习的设定下(训练和测试场景具有相同分布),目前仍然有很多围绕深度网络的开放问题,例如理解非凸优化、优化器的隐式正则化效果和表达能力。基础模型带来的问题远远超出了深度监督学习设定。从理论上分析基础模型的关键问题是:理解为什么在一个分布上使用无监督/自监督损失进行训练可以导致在不同下游分布和任务上的良好表现。9
9 基础模型的理论与迁移学习紧密相关的同时也超出了迁移学习(迁移学习本身也是未被充分探索的领域):基础模型可以使用无标签数据进行训练,并适配到许多甚至全部的自然任务中,而典型的迁移学习研究有标签的源任务和固定数量的目标任务
我们将采用直观的模块化方法分析基础模型,其揭示了监督学习和基础模型之间的联系、具体且核心的技术问题,以及一些有前途的解决这些问题的技术工具。这些新的核心问题可以提供对于基础模型的有用见解,且可以与有监督的深度学习理论并行研究。尽管我们集中于分析下游任务的表现,我们提出的模块化方法和工具对于分析其他的感兴趣的指标也是非常有用的,例如对分布变化的鲁棒性(§4.8: 鲁棒性)和安全性(§4.7: 安全性)。
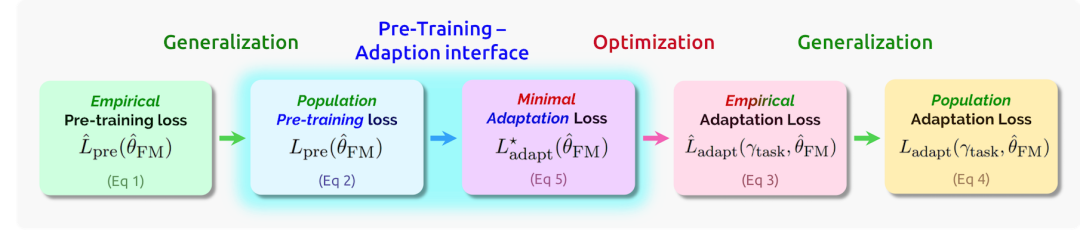
4.10.1 理论公式和模块化
基础模型在大量的原始数据(§4.2: 训练)上进行训练然后被适配到具体的任务(§4.3: 适 配)中,因此可以很自然的被分解为训练阶段和适配阶段。我们确定了这两个阶段之间的交界面,并将基础模型的特定部分与需要标准深度学习理论的部分分开,使得它们可以被单独分析。我们引入了一个模块化的分析框架,该框架也被隐式或显式的应用在了最近的工作中,例如: Arora et al. [2019b]; HaoChen et al. [2021a]; Wei et al. [2020b]; Tripuraneni et al.[2020]。该模块化分析的核心组件是预训练-适配交界面。我们首先描述模块化方法,然后讨论为什么我们认为这种模块化是有前途的以及其存在的一些局限性。
我们将训练阶段明确地称为“预训练”来与适配阶段区分,因为在适配阶段也会在来自特定任务的少量样本上进行训练。
预训练阶段 基础模型的预训练阶段通常包括:数据分布 (例如:自然的文本分布)、模型参数 和用于衡量模型对于输入 的损失的预训练损失函数 (例如:GPT-3 中的语言建模损失)。我们用 表示来自 的大量独立样本的经验分布。
预训练在 上最小化损失 ,我们称之为经验预训练损失,然后得到模型 :
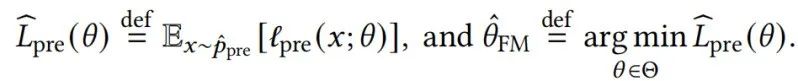
我们将在总体分布 上的相应损失称为总体预训练损失,并将其作为一个中心概念:
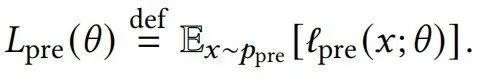
基于优化的适配阶段 我们将适配阶段框架化为一个依赖于 的一般约束优化问题,抽象出那些基于优化的特定损失函数的适配方法(参见,如 [Houlsby et al. 2019; Li and Liang2021; Lester et al. 2021],和§4.3: 适配),例如:微调和提示调整。
由于不同的适配方法可能会修改模型不同部分的参数,我们用 来表示适配模型的参数空间。对于给定的下游任务分布 (例如:特定领域的问答任务)以及一些从 中采样的经验样本 ,我们将适配阶段建模为在 上最小化关于适配参数 的某个适配损失 :
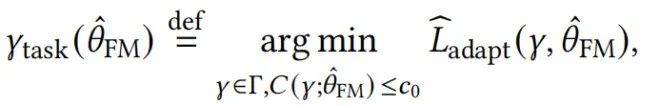
其中
我们列出了一些常见的适配方法以及相应的适配参数 和约束 。
(1) 线性探测:用基础模型的上层表示训练一个线性分类器。这里的 是一个线性分类器的集合,其中的每个分类器对应的一个 维表示,而 可以是 的 或 范数。
(2) 微调:通过几个步骤来优化一个随机初始化的线性层,且其他的所有参数 来自 的初始值。这里的 是 与线性头的参数的并集。这样的过程可以对应于 对被 捕获的初始值 的某些隐式正则化。 的精确项将取决于使用的优化算法,这样的关于优化的隐式正则化的表征是一个活跃的研究领域 [例如:Gunasekar et al. 2017; Soudry et al. 2018; Gunasekar et al. 2018; Arora et al. 2019a;Blanc et al. 2019; Woodworth et al. 2020; Wei et al. 2020a; HaoChen et al. 2021b; Damianet al. 2021, and references therein]。10
10 我们并不一定总是能够通过显式约束 来表征适配的归纳偏差。我们提出模块化方法对于这些情况同样适用,但是为了符号的简洁性,我们关注那些能够通过显示约束来逼近的隐式正则化情况。
(3) 提示微调:优化一个很小的任务特定的连续向量的集合,这些向量被追加到任务的输入中。这里的 是连续提示向量,且通常维度较低,我们可以选择性地对 的范数进行约束。
一个值得注意的局限性是,该公式不包括在适配阶段没有“训练”(即:对某些经验适配损失的最小化)的适配方法,如语境学习 [Brown et al. 2020]。我们将在§4.10.3: 理论-语境中讨论该局限性以及其他的局限性。
适配阶段的两个中心量是总体适配损失
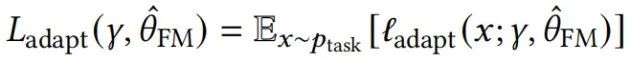
和最小适配损失
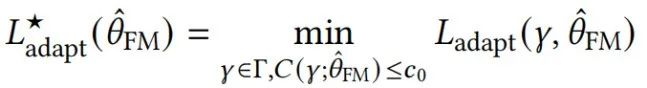
模块化阶段的单独分析 现有的关于标准有监督学习的泛化理论旨在证明 和 。专门为深度网络解决这些问题是一个活跃的研究领域。我们也可以利用标准学习理论分解来通过过量泛化误差和最小化的适配误差界定最终的下游任务损失,如下所示:
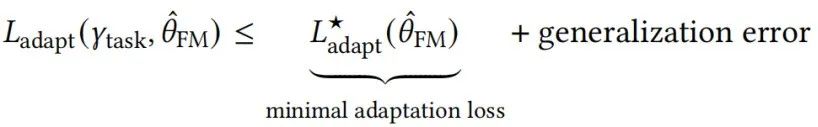
其中泛化误差捕捉了 和 的接近度。这些关键量的分解和它们之间的关联展示在了图2中。泛化和优化箭头,就像上面讨论的那样,很大程度上使深度学习理论处于有监督设定中。目前所剩下的就是我们要面对的基础模型的主要挑战,即理解为什么最小适配误差 会随着预训练总体损失的减少而减少,我们将在§4.10.2: 理论-交界面中深入讨论。
Arora et al. [2019b] 的工作在对比学习的设定中通过使用 界定 率先对这个问题进行了讨论,然后 HaoChen et al. [2021a]; Tosh et al. [2020, 2021] 放宽了数据假设。其他的预训练方法成功隐式或显式地被该框架分析,包括语言模型 [Wei et al. 2021]或自监督 [Lee et al. 2020a]、自训练算法 [Wei et al. 2020b; Cai et al. 2021] 以及多个有监督任务 [Tripuraneni et al. 2020; Du et al. 2020] 的预训练。
4.10.2 为什么预训练-适配交界面是引人注目的?
如图2所示,超出标准学习理论的主要缺失环节是:
在什么条件下小的总体预训练损失 会导致小的最小适配损失 ,以及为什么?
成功的交界面可能依赖于一些条件,例如:预训练和适配的分布、目标函数、训练方法以及模型的结构。这个问题超出了标准泛化理论的范围,但它确实也使我们发现了特定于基础模型的一些重要因素,并且捕捉了各种基础模型的重要开放问题的本质,我们将在下面对此进行讨论。
第一,我们注意到该交界面处理的总体量涉及两个不同的分布。因此,交界面的成功条件可能包含分布的特殊性质,例如,预训练分布的多样性以及预训练和适配数据间的结构变化。这使得交界面分析富有挑战性(如在§4.10.4: 理论-工具中所讨论的),因为我们需要对这两个分布如何彼此关联进行仔细地建模假设。然而,这也表明了为分析该交界面而开发的工具和技术对于理解分布变化的影响和预测基础模型的鲁棒性何时能够提高也可能是有用的。
第二,总体损失和可能的交界面成功条件取决于模型结构。这提出了如何“打开“黑箱神经网络这一挑战。在特定分布上的小的预训练损失能够告诉我们什么样的中间层的性质?这样的分析能够指引我们设计一种能够更加仔细地利用不同中间表示的适配方法。
第三,小样本学习或适配阶段的采样有效性可以被最小适配损失中的对于复杂度度量 的约束所捕捉,我们需要正式地表示这些复杂度度量(例如:通过理解适配过程的隐式正则化效果),并进一步理解为什么小的总体预训练损失将导致低复杂度的适配参数 。如果能够得到该问题的满意答案,那么我们就有可能能够提高下游适配中的采样有效性。
最后也是最重要的,交界面的关键组件是对于预训练和适配损失的选择。我们想要理解如何最好的将预训练和适配目标结合,从而得到成功的适配结果。能够保证最好的适配结果的预训练目标与预训练阶段的明确的最小化目标有可能是不同的——上面的交界面允许我们在预训练分布上使用任意的替代总体目标。此外,被证明在广泛任务上可以取得良好适配结果的新的替代的目标可以阐明那些能够使基础模型更加成功的基本方面。
总而言之,交界面排除了泛化问题并允许我们正式地对某些预训练和适配阶段的重要量之间的交互进行推理,这是指导实践的重要方式。
4.10.3 挑战:语境学习和其他涌现行为分析
GPT-3 [Brown et al. 2020] 展示了语境学习的强大功能,这是一种不需要任何参数优化的适配方法。在适配阶段,预训练语言基础模型接收一个提示(连接了任务的输入-输出示例的词序列)和一个测试样本,然后在给定已知序列(提示加测试样本)的条件下直接生成测试样本的标签。换句话说,模型参数没有显式地训练或更改。模型的运行仅依靠简单地将示例作为输入,那么其从不同示例中“学习”的机制是什么?前文的模块化并不适用于此,因为我们在适配过程中没有获得新的模型参数,而是仅在结构化设计的输入上运行基础模型以使用其生成能力。更广泛地说,前文提出的模块化提供了一个良好的框架,有助于在上文讨论中获取对基础模型的有益的理论理解。但是,某些涌现行为(如语境学习和其他尚未发现的功能)可能需要相比于模块化来说更深层的理解。
4.10.4 挑战:适当的数据假设和数学工具
相比于传统的有监督学习,预训练和适配之间的接口理解需要对数据分布进行更加仔细的研究。这是因为预训练和适配任务的分布本质上是不同的。根据定义,基础模型是在原始数据上训练的,这些原始数据通常是极其多样化且任务无关的,而适配数据严重依赖任务。类似地,语境学习旨在学习如何生成接近预训练分布的数据,因此理解语境学习需要仔细对预训练数据建模。因此,回答基础模型的核心问题需要现实、可解释且适合分析的假设。近期工作要么假设总体数据的某些属性,例如HaoChen et al. [2021a]; Wei et al. [2020b] 中的扩展属性,或者总体数据是从具有某种结构的隐变量模型生成的 [Saunshi et al. 2020a; Weiet al. 2021; Arora et al. 2016; Lee et al. 2020a; Zhang and Hashimoto 2020; Tosh et al. 2021]。
能将基础模型的属性与总体数据分布的结构相关联的数学工具较为罕见。HaoChen et al.[2021a] 应用谱图理论来利用总体分布中的内部类连通性。对于隐变量模型,可以通过概率和分析推导对 进行更精确的表征,但目前仅限于相对简单的模型。能解决该问题的更系统、更通用的数学工具对社区来说是大有裨益的。
简单的小型案例可以方便理论家精确地比较和分析不同工具的优势,因此这些案例的定义是很受欢迎的。例如,HaoChen et al. [2021a] 和 Wei et al. [2020b] 考虑了流形混合问题,这可能是视觉应用的一个很好的简化测试平台。对于 NLP 等离散域,我们需要更多有趣的测试平台。我们相信,捕捉真实数据集相关属性的易处理的理论模型是基础模型迈向坚实理论基础的关键一步。
4.11 可解释性
Authors: John Hewitt*, Armin W. Thomas*, Pratyusha Kalluri, Rodrigo Castellon, Christopher D. Manning
与大多数其他机器学习模型相比,基础模型的特点是训练数据和复杂性的大幅增加以及未预见能力的涌现:基础模型能够完成未预见的任务,并以未预见的方式完成这些任务。基础模型应用量的增长也随之带来了理解模型行为的期望、需求和前所未有的挑战的增长。
与任务限定模型相比,基础模型在庞大且高度不同的数据集上进行训练,可能跨越多个领域和模态(参见 §4.2: 训练)。通过这种训练,基础模型学习了非常广泛的行为,这些行为在任务和领域之间可能会有很大差异,这体现在它们能够适应许多不同类型的下游任务并展示针对每个任务的特定行为(见§4.3: 适配)。以 GPT-3 为例,它是一个被训练来简单地预测文本中的后继词的大模型。虽然这是一项非常具体且易于定义的学习任务,但 GPT-3 与包含所有类型网络文本的大规模训练数据集相结合而获得的能力,让人们很难将其关联到后继词预测。因此,当提供很少的训练样本时,GPT-3 现在可以适配明显超出其原始训练任务范围的行为,例如简单的算术和计算机编程。这表明,即使是关于基础模型的看似最简单的问题也很难回答:它有哪些功能?
此外,这些不同的功能在多大程度上依赖于独立或共享的模型机制(类似于模型中的算法构建模块)仍是一个开放性问题。一方面,基础模型可以被解释为单模型,它利用一些可泛化的模型机制在跨任务跨领域中获得良好的效果。在这种情况下,可以通过识别和表征这些机制来全面了解他们的行为。另一方面,基础模型针对不同任务采取截然不同的行为的能力表明,它们也可以被理解为大量独立专家模型的集合,每个模型针对特定任务而定制。例如,GPT-3 用于算术的模型参数似乎不太可能与用于将英语翻译成法语的参数有很大关系。因此,在这种情况下,一项任务中模型行为的解释不一定能提供有关其他任务中行为的信息。我们将此称为基础模型的单模型-多模型性质(参见图3),并认为了解基础模型在单模型到多模型频谱之间的位置是理解它们行为的核心。
为了系统化这个研究领域,我们提出并讨论了理解基础模型的三个层次 [受 Marr 1982 启发]:简单来说,我们首先讨论了理解模型能够做的是什么的挑战和机遇,然后是为什么它输出了特定的行为,最后是它如何做到的。具体来说,“是什么”的问题旨在表征模型可以在不“窥视”内部的情况下执行的行为类型,而“为什么”的问题旨在提供模型行为在数据中的潜在成因的解释,“如何”的问题旨在了解产生这些行为的内部模型表示和机制。在介绍了所有三个级别之后,我们最后通过讨论由基础模型的不可解释性和可解释性导致的潜在后果进行概括总结。
4.11.1 表征行为
对技术最简单的理解普遍被认为是了解技术做的是什么?由于基础模型能够执行无数未预见行为和任务,这个看似简单的问题对于这些模型来说仍是一个巨大的挑战。
任务限定的神经网络模型被训练用以在单领域中执行单个任务,例如图像分类。因此,它们的任务以及输入和输出域是明确的;然而,即使对于这些模型,在给定特定输入的情况下,确切知道模型将要做什么也可能具有挑战性:例如,对于两个感知上相似的输入 [Gargand Ramakrishnan 2020; Jin et al. 2020] 或相同数据的两个子总体(例如,按种族或性别划分 [Hovy and Søgaard 2015; Blodgett et al. 2016; Tatman 2017; Buolamwini and Gebru 2018]),模型行为可能出乎意料地大不相同。
对于基础模型而言,模型行为表征的这一挑战被放大了许多倍。模型能够执行的任务的空间通常很大且未知,输入和输出域通常是高维和庞大的(例如语言或视觉),并且模型较少局限于特定领域的行为或失败模式。例如,在大规模语料库上训练后,GPT-3 可进一步开发出计算机程序主要功能片段生成的惊人能力。因此,基础模型行为表征的一个关键挑战是确定其具有的能力。对于基础模型可以执行的每项任务,即使该任务限定的模型更简单,其行为理解都面临着上述挑战,更何况任务数量可能非常多甚至无限多。
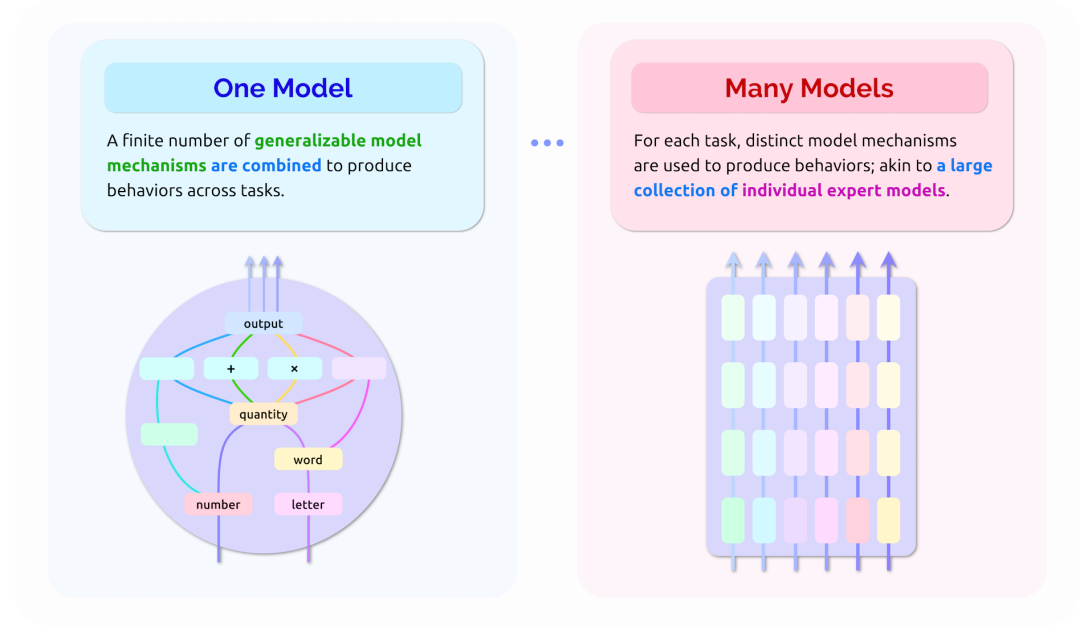
基础模型可以执行的“任务”的表征由于单模型-多模型性质而变得更加复杂(参见图3)。再次以 GPT-3 为例,现已证实它可以通过简单的提示(参见 §4.3: 适配)针对许多任务进行定制。然而,一个任务的制定可以通过多种可能的提示实现,提示的细微变化可能会导致模型行为发生实质性的变化。例如,电影评论情感分类任务的制定,可通过在电影评论前加入“她对电影的情感是……”或“我的总体感觉是这部电影是……”来实现;尽管这些提示所提出的任务看起来是密切相关,但 GPT-3 对每个提示都会表现出不同的响应精度 [Zhao et al. 2021]。上述观察引出了关于提示特征与由此产生的模型行为之间关系的重要问题。具体来说,近似提示的不同响应是由相同模型产生的还是由高度不同的模型机制产生,并且在一项任务中表征基础模型(或其适配变体)的行为是否真正有助于表征模型的其他可能的适配行为?
研究人员可以利用受控评价识别基础模型拥有和缺少的功能。这里,领域专家可以针对特定能力设计必要的提示,然后研究模型正确响应这些提示的能力 [Papadimitriou and Jurafsky2020; Lu et al. 2021a; Kataoka et al. 2020; Wu et al. 2021c; Xie et al. 2021a; Koh et al. 2021]。例如,语言心理学家设计的提示要求语言模型在语法正确的句子和具有特定语法错误的相同句子之间进行选择;了解模型是否始终倾向于语法正确的句子而不是语法错误的句子,可以告诉我们模型是否具有识别这种错误所需的特定语法能力 [Linzen et al. 2016]。
鉴于基础模型具有数量庞大的潜在能力,且目前我们尚缺乏一种通用方法来先验地确定基础模型是否具有给定的能力,上述定制评价变得尤为重要。它们使得探索基础模型能实现的行为范围成为可能,同时需要相对最少的模型权限:我们只需要呈现模型输入和接收输出,不必依赖于对模型实现或参数的访问。考虑到基础模型可能(或无法)执行无数的期望/未知的任务、子任务和行为,表征模型行为和能力将变得越来越具有挑战性和重要性。我们相信,将该类分析扩展到更多行为的测试上是更重要的,相较于依赖少数专家来制定和测试可能的行为,我们一方面要向多样化社区和多学科专家开放这一探索路线,同时还要增加这些评价的机会和规模。
4.11.2 解释行为
除了表征基础模型做的是什么之外,还可以尝试根据数据中的潜在原因对这些行为提供解释,以此来表征为什么模型执行某些行为。虽然当前(提供上述行为解释)的解释方法可以揭示影响模型响应的输入的质量,但它们通常需要模型的全部权限,并且在阐明通用模型机制(在基础模型中用以响应众多输入、任务和领域)方面其能力往往非常有限。
当前的解释方法通常可以被理解为不同的模型,这些模型旨在提供对另一个黑盒模型特定行为的解释。值得注意的是,这些方法与行为被分析的模型是分离的,这些方法本身是不可解释的。这种分离也可能存在问题,因为所提供的解释可能缺乏可信度 [Jacovi andGoldberg 2020]、提供的行为原因不可靠或具有误导性 [c.f. Rudin 2019]。更进一步,不合理的解释会诱使人们更加信任不合理的模型(有关对人工智能的信任的详细讨论,请参阅 Jacoviet al. [2021])。随着任务限定模型到广泛采用的基础模型的过渡,这类担忧还会进一步加剧,因为基础模型的行为会更加复杂。
当前解释方法对模型行为提供的解释大体可分为局部的或全局的 [Doshi-Velez and Kim2017]。局部解释试图解释模型对特定输入的响应(例如将输入的每个特征和行为相关联或识别与行为最相关的训练样本;[Simonyan et al. 2013; Bach et al. 2015; Sundararajan et al. 2017;Shrikumar et al. 2017; Springenberg et al. 2014; Zeiler and Fergus 2014; Lundberg and Lee 2017;Zintgraf et al. 2017; Fong and Vedaldi 2017; Koh and Liang 2017])。相比之下,全局解释与特定输入无关,旨在揭示影响模型行为的总体数据的质量(例如,综合模型中与行为最密切相关的输入;[Simonyan et al. 2013; Nguyen et al. 2016])。
局部和全局解释为任务限定模型的行为提供了实用的见解 [例如,Li et al. 2015; Wang et al.2015b; Lapuschkin et al. 2019; Thomas et al. 2019; Poplin et al. 2018]。这里,由此产生的解释通常被视为对引发行为的模型机制的启发;例如,当模型读取手写数字“7”时,将水平线作为重要原因的解释很容易让人产生这样的印象,即水平线是模型用来识别所有 7 或可能是区分所有数字的一个普遍重要的特征。
然而,考虑到基础模型的单模型-多模型的性质(参见图3),我们应该注意不要从行为的具体解释跳到关于模型行为的一般假设。虽然当前的解释方法可能会阐明特定行为(例如,识别数据的哪些方面对特定行为产生了强烈影响),但由此产生的解释并不一定有助于洞察模型对其他(甚至看似相似的)输入的行为,更不用说其他的任务和领域。
另一种方法通过自解释的形式利用基础模型的生成能力来完全回避上述类型的事后解释 [c.f. Elton 2020; Chen et al. 2018]。也就是说,通过训练这些模型不仅生成对输入的响应,还同时生成对该响应的人类可理解的解释。虽然目前尚不清楚这种方法在未来是否会产生成果,但我们有理由持怀疑态度:语言模型和现在的基础模型在没有任何参考而生成流畅、看似合理的内容方面非常出色。简单的自生成“解释”是很容易实现的,但重要的是要辨别模型创建看似合理的解释的能力与提供对其行为的真实见解之间的差异。
4.11.3 模型机制表征
对系统的深入理解通常意味着理解系统是如何运行的:它包含哪些知识和机制,以及这些知识和机制如何组合形成整体的?
如果这是可行的,那么表征基础模型中的表示以及对它们进行操作的机制将是满足彻底理解这些增涨模型的愿望的核心;并且无论这些机制是多而具体还是少而可泛化(参见图3),它们都是基础模型在不同任务和领域中采用广泛行为的能力的核心。
为了使模型表示和机制的概念具体化,请考虑 GPT-3 展示的一个简单行为:在给定两个小数值相加示例然后查询两个新数相加的例子中,可以快速观测到 GPT-3 做了什么;大概率它会预测出加法的正确结果 [Branwen 2020; Brockman 2020]。至于为什么 GPT-3 会这样运行,人们可以在输入中找到证据,例如提示中对响应影响很大的方面(有可能是相加的两个数字),或者 GPT-3 训练数据中影响响应的某些方面(有可能是加法的样本)。通过深入研究模型,我们可以更深入地了解 GPT-3 关于特定数字组合的加法机制以及关于其他任意数字组合的加法机制。我们还可以更深入地了解这些机制是否类似于“加法”的数学概念或仅与该概念相关。
通过理解单个模型机制,我们可以建立对基础模型复杂行为的组合的理解。数学单词问题的解决是一项比数字加法稍微复杂的任务,其中数字带有单位,问题以自然语言呈现。一旦我们理解了模型执行加法的机制,我们就可以研究这种机制是否作为中间步骤被用作解决单词问题。如果加法机制被使用了,我们就可以理解模型如何解决单词问题了,这也将增加我们对基础模型概括数量和加法(而不是一种相关性或启发式)概念的信心,以及增加我们预测模型的为什么(输入的哪些部分被关注)问题和输出的是什么(两个数字的加法)问题的能力的信心。如果加法机制没被使用,我们将合理的怀疑这是否为真正的加法,然后研究哪些表示和机制作为代替被使用了。
有许多更复杂的、令人担忧的模型机制的潜在案例需要格外注意,例如,根据名称中的字符或图像中的像素估计种族。在基础模型中建立和使用这种机制的证据,会为禁止该模型执行预测性警务、营销、贷款申请和大规模监视等任务提供伦理或法律责任依据。
目前已经出现了大量方法来研究神经网络模型内部的各个方面。通常,这些方法将模型分成各个节点(例如神经元、层或层的一部分),然后查询节点中捕获的表示或节点的组合机制。一些方法是假设驱动的:通过假设节点可以捕获特定的信息(例如一个词的语法特征,或一个人的种族),人们可以探测所有节点以量化它们提供了多少该信息 [Alain andBengio 2016; Veldhoen et al. 2016; Belinkov et al. 2017; Adi et al. 2017; Conneau et al. 2018; Hewittand Liang 2019; Hewitt and Manning 2019; Voita and Titov 2020; Pimentel et al. 2020]。其他方法建立在解释性方法的基础上,相比于识别哪些数据导致某种行为,它们试图识别哪些数据导致某个节点被激活,或哪些节点导致模型中的另一个节点激活,从而揭示模型的表示和机制集合 [Olah et al. 2020; Mu and Andreas 2020; Carter et al. 2019; Goh et al. 2021]。总之,这些方法检查模型的内部,并为持续探索基础模型的行为提供基础。然而,基础模型中潜在的表示和机制的数量是巨大的,特别是考虑到它们的单模型-多模型的性质(参见图3),并且这些类型的方法通常只捕获了模型内在的一小部分。因此,扩大表示和机制的发现并阐明什么对模型行为最相关或最普遍,仍是一个公开的挑战。与解释基础模型的许多方法一样,这些类型的探索将受益于吸纳和支持更多样化和跨学科的研究人员以及更易于访问、灵活和可扩展的发现方法。
总之,我们认为基础模型的单模型-多模型的性质(参见图3)为当前的可解释性研究提供了新的机遇和挑战:单基础模型有许多适配版本,我们根本不知道它们共享机制的公用程度。如果机制是共享的,表征这些机制及其关系即可有效地处理基础模型的理解问题。如果机制是独立的,则必须独立分析基础模型的每次适配,从而导致基础模型的任何新适配的性质具有极大的不确定性。
4.11.4 不可解释性和可解释性的影响
最后,我们想强调的是,基础模型的广泛采用与许多跨学科研究人员最近呼吁不要使用复杂的黑盒模型进行高风险决策而是专注于更具有内在可解释性的模型的长期开发和应用相矛盾 [例如:Rudin 2019]。
在这些请求中,旨在解释基础模型的工作是一把双刃剑。大型机器学习模型和现在的基础模型通常只能由强大的公司和机构部署,并且可解释性的渐进式进步被夸大为“伦理清洗(ethics-wash)”,模型被持续使用仿佛它们已经实现了可解释性一般,事实证明,它们仍远低于算法可解释性的传统标准。此外,当可解释性方法经常假设可以轻松访问模型及其实现和参数时,可解释性不仅成为了强大机构的掩护,还将模型知识集中在了这些机构的手中。对于那些致力于基础模型可解释性的人来说,他们有责任始终如一地询问自己是否正在努力使基础模型对研究人员和模型所有者可解释还是对所有人可解释。
同时,在基础模型已经部署的范围内,可解释性工作提供了独特的机会来将基础模型的知识以及权限转移回数据化的评价人员的手中。解释可以促进模型的社会性显著方面的发现。从根本上说,允许任何人解释基础模型行为的可访问方法,将权限转移给了不同的人,从而创造了研究模型、发现对个人或其社区重要的模型方面以及有意义地同意、改进或共同争论基础模型的使用的机会。对于研究人员来说,不仅将基础模型的可解释性视为一个目标,而且是一个问题,这一点也很重要:研究工作可以探索和评估基础模型可解释性的缺乏是否是内在的、值得被深入研究的和被广泛认同存在问题而不应使用(或进一步规范)的,或者未来的基础模型是否有可能为所有人保持高标准的可解释性。
本期责任编辑:丁 效
理解语言,认知社会
以中文技术,助民族复兴


