赛尔笔记 | 自然语言推理数据集简述
作者:哈工大SCIR 严未圻
1.1 背景
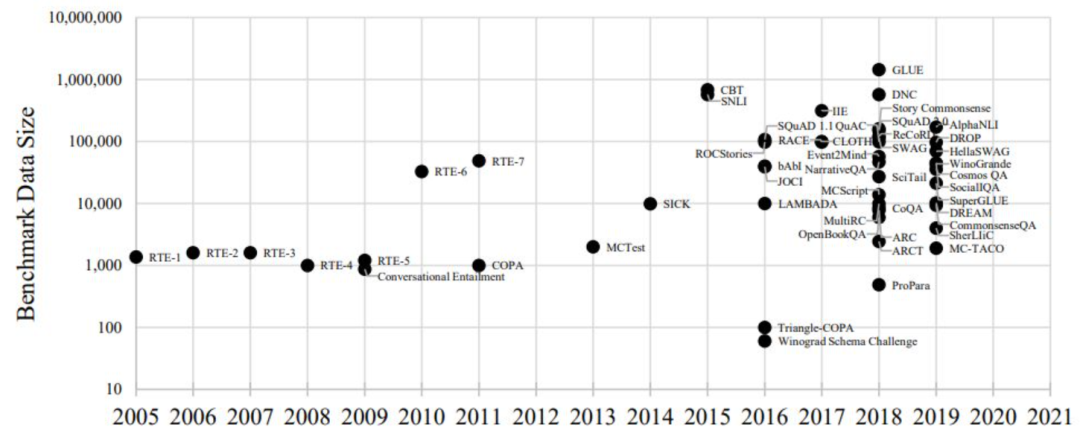
Natural language inference(NLI)自然语言推理,或Recognizing Textual Entailment(RTE)[1]文本蕴含识别,指的是预测hypothesis(假设)是否蕴含于、矛盾于、无关于已经给出的premise前提条件句。该任务2013年由Ido提出,2015年由Bowman和Manning等人完善。2018年学术界提出了大量的相关benchmark[2],进一步为NLI领域的研究提供了便利。本文将介绍几个重要的NLI数据集以及最近两年发表的NLI数据集。
1.2任务概述
NLI任务,或者说RTE任务,在Ido Dagan 2013年的书[1]中提到,提出该任务的最初想法是想设计一个任务来综合考量模型对于自然语言的理解和推理能力。根据他的哲学,这个任务应该尽量简单,来符合抽象性和泛化性,以便于推广到其他下游任务上。于是他提出了这个任务:判断一段文本的意思是否蕴含于另一段文本。后续研究也表明了,这样的简单任务在其他许多NLP任务中也有出现,例如机器翻译、语义搜索、信息提取。[3]高层次的抽象任务避免了模型对于特定语言类型进行特殊表达,使得任务训练出来的模型泛用性更强。同时,这样的任务还能促进评估,这也是任何一个学术进步中非常重要的部分。关于这个任务的更多的思辨,可以去IEEE上搜索Ido Dagan的这本书,其中的Chapter1讲解的非常详细。

2.传统数据集简述
NLI任务中比较权威的一个数据集就是纽约大学、华盛顿大学等机构创建的一个多任务自然语言理解基准和分析平台,也就是GLUE[4]。其中,与NLI相关的数据集包括QNLI,以及MNLI。
2.1 QNLI
Qusetion-answering NLI,QNLI数据集,是一个自然语言推断任务。QNLI是从另一个权威的QA数据集The Stanford Question Answering Dataset(斯坦福问答数据集, SQuAD 1.0)转换而来的。SQuAD 1.0是由问题-段落对组成的问答数据集,其中段落来自Wiki,段落中的一个句子包含问题的答案。通过将问题和上下文(即维基百科段落)中的每一句话进行组合,并过滤掉词汇重叠比较低的句子对就得到了QNLI中的句子对。相比原始SQuAD任务,消除了模型选择准确答案的要求,也消除了简化的假设,即答案始终在输入中并且词汇重叠是可靠的提示。
样本个数: 训练集104743个,开发集5463个,测试集5461个。
任务: 判断问题和句子是否蕴含。是一个蕴含和不蕴含的二分类问题。
评价准则: 准确率Acc。
2.2 MNLI
The Multi-Genre Natural Language Inference Corpus,MNLI[5] ,多类型自然语言推理数据库,是一个自然语言推断任务,数据集是通过众包方式对句子对进行文本蕴含标注的集合。给定前提语句和假设语句,任务是预测前提语句是否包含假设(entailment)、与假设矛盾(contradiction)或者两者都不(中立,neutral)。前提语句是从数十种不同来源收集的,包括转录的语音、小说和政府报告。
样本个数: 训练集392702个,开发集dev-matched 9815个,开发集dev-mismatched 9832个,测试集test-matched 9796个,测试集test-dismatched 9847个。
因为MNLI是集合了许多不同领域风格的文本,所以又分为了matched和mismatched两个版本的数据集,matched指的是训练集和测试集的数据来源一致,mismached指的是训练集和测试集来源不一致。
任务: 句子对,一个前提,一个假设。
前提和假设的关系有三种情况:蕴含(entailment)、矛盾(contradiction)、中立(neutral)。是一个句子对三分类问题。
评价准则: 匹配准确率Matched-Acc/不匹配准确率Mismatched-Acc。
MNLI的创作者同时推荐使用SNLI[6](Stanford Natural Language Inference)数据集作为辅助[7]。该数据集是一个类似MNLI的数据集,是一个570k大小、人工编写的英语句子对的集合。
3.对抗性数据集简述
在许多新的NLI benchmark提出之后,学者们开始对于数据集的性能提出质疑。认为许多现有的数据集如MNLI、SNLI等的鲁棒性不强,训练出来的模型泛化性能也有很大的提升空间。这样的模型并没有达到NLI任务提出的初衷:使得模型能够在训练集合上真正学习到理解自然语言的能力。一部分学者从模型结构入手,尝试创造出学习能力更强、不会陷入数据集局部特征的模型;另一部分学者则认为模型更新速度已经超过了数据集的更新速度,他们转换思路,尝试构建更强大、更有挑战性的数据集。
3.1 ANLI
Yixin Nie的团队提出了一种新的数据集,称为ANLI(Adversarial NLI)[8]。这个数据集的基本思想是基于与模型进行对抗,从而迭代更新数据集。将SOTA模型应用在这个数据集上,也能够看出该数据集十分具有挑战性。
构建ANLI数据集一共需要三轮,这个过程被称为HAMLET(Human-And-Model-in-the-Loop)。HAMLET的过程可以把标注师看成是一个“白帽”黑客,标注者被提供了一个前提premise和一个预期关系target label,标注者需要尽可能的使给出的假设有迷惑性,让机器误判,同时需要给出一个理由,为什么premise和hypothesis符合预期假设。这个理由会被交给另一个工人,称为验证者。如果第一个验证者与标注者意见相左,则交给第二个验证者,若第二个验证者的意见与第一个验证者意见相左,则弃用这个样例。如果意见相同,则改写这个label。标注是由Mechanical Turk的工人进行标注的。
一轮标注结束之后会根据之前的标注构建新的训练集、测试集和验证集。其中验证集和开发集仅由第一遍验证正确的数据条目构成。此外,测试集还有单独的标注者和重新平衡各个种类的步骤。
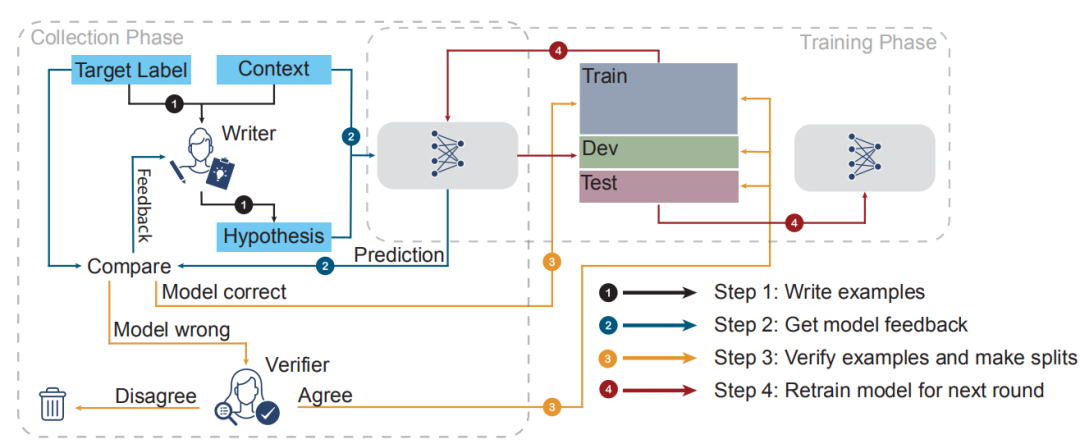
第一轮标注,我们使用SNLI、MNLI和FEVER的NLI版本作为数据集,训练一个BERT-Large模型。选出表现最佳的超参数,将这个模型作为第一轮选择的模型。第一轮的premise来自HotpotQA的训练集。选取方法一是直接选用数据集中的事实,方法二是根据问题从Wiki中利用TF-IDF相似度选取相关文本。
第二轮标注利用了在NLI数据集上表现更好的RoBERTa模型,同样利用了SNLI、MNLI和FEVER的NLI版本[9],并且加上了第一轮的数据(A1)。同样根据A1的验证集进行超参数选择,选取效果最好的RoBERTa[10]模型作为最后一轮的模型。Premise选取方法同第一轮。
最后一轮标注使用了更加广泛的数据,包括新闻 (提取自Common Crawl)、 小说 (提取自StoryCloze and CBT)、口语文本(主要来自于美国庭审记录),,以及从WikiHow提取的部分文字,加上RTE5中的长数据。利用这些数据,我们训练了一个更强的RoBERTa模型。
最终得到的数据集的数据量和统计数据如图所示,Error rate指的是每一轮的错误率的平均值。
表1 ANLI数据集的统计量
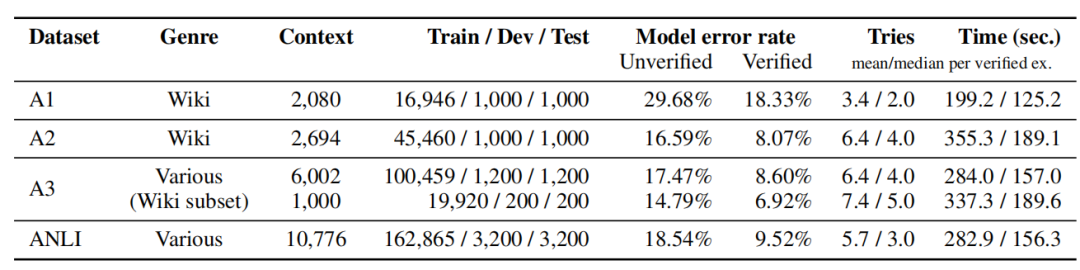
为了表现数据集的可靠性和挑战性,作者将在其他数据集上表现优秀的模型应用在ANLI上,对比其效果。
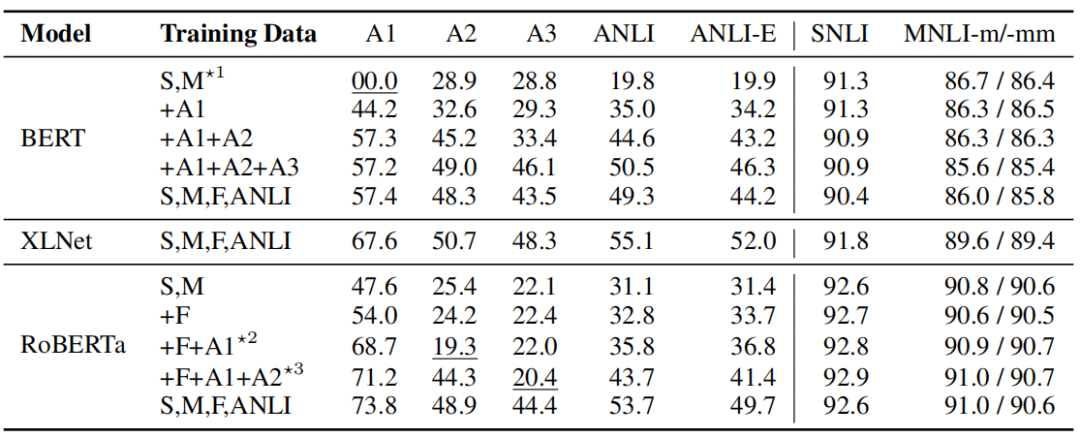
其中S表示SNLI,M表示MNLI,*n表示用这个模型训练了几轮,-E表示加上了特别的测试集标注者的测试集数据。
从中我们不难发现,基础模型的表现非常差,而且随着训练轮数的增大,数据集变得越来越具有挑战性。同时,利用这些多轮数据本身训练的模型鲁棒性相比没有使用的显著提高。RoBERTa虽然取得了SOTA的效果,但是本身的基础模型在ANLI数据集上表现也不理想。另外我们发现,在原先MNLI和SNLI任务上添加新的ANLI数据,并不会使得其在SNLI和MNLI上表现下降。这些结果都说明了,ANLI数据集是一个具有挑战性的有效数据集。
3.2 DocNLI
ANLI数据集的效果提升证明了对于NLI任务来说,一个优秀的数据集的提升是十分显著的。然而ANLI本身是存在一些问题的,例如初始启动的两次数据集使用了SNLI和MNLI,这两个数据集本身的来源非常单一,而且数据集句子本身的长度比较短,难以迁移至下游任务,比如验证文档摘要的正确性,句子级别的NLI模型很难起到作用。为了解决这个问题,Wenpeng Yin等人提出了一个新的大规模NLI数据集DocNLI[2]。它具备以下几个特征:1.DocNLI与下游任务结合紧密,在DocNLI数据集上表现理想的模型,原理上在下游任务上的表现也会比较理想;2.前提句总是超过一句话,假设的文本长度变化不一。这保证了DocNLI训练的模型对长短文本都有较强的理解能力;3.DocNLI刻意的去除人工设置数据集的痕迹,让数据集更加的真实。
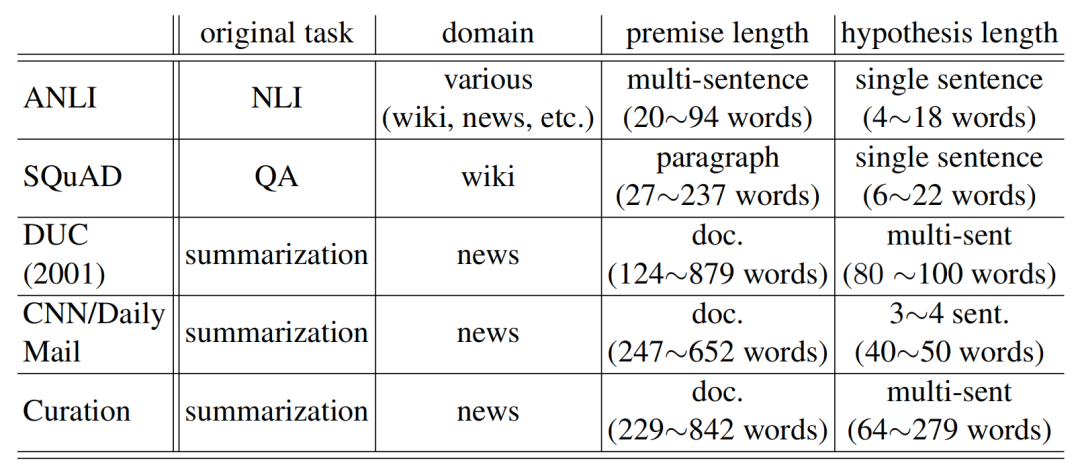
DocNLI是一个由之前已有数据集得出的数据集,它利用了表中所示的这些数据集。
表3 构成DocNLI的数据集
收集ANLI: 对于ANLI数据集,DocNLI选择直接接纳所有数据,但是将neutral和contradiciton两类标签合并为同一个标签not_entail。
收集SQuAD: 在之前的工作中,已经有人将SQuAD这个经典数据集进行了转换,Demszky利用SQuAD设计了QA2D数据集[11],DocNLI数据集直接利用QA2D数据集,将其作为SQuAD的转换。
收集文本摘要数据: 数据集引入了3个重要的文本摘要数据集DUC2001、CNN/DailyMail 和Curation。每个文本摘要数据都是由一段文本和一个人工生成的参考摘要构成,本文利用3类方法对参考摘要进行替换。
(1)词替换。遮盖住8个词性是名词或动词或代词或量词的词,并且用BERT预测并替换这些词。
(2)实体替换。使用spaCy工具进行命名实体的识别。对于整个摘要中只出现一次的实体类型,我们从文档中选取一个同类实体替换,否则选择摘要中出现的同类实体替换。
(3)句子替换。从真实摘要文本中,我们随机挑选出一个句子,将剩余的句子送入CTRL算法,一个SOTA的可控文本生成算法,生成相同语义的句子。这样也创造了新的“假”摘要。
对于这样的文本摘要数据集,还存在一个问题,那就是BERT以及RoBERTa等模型能够很快的学习到一些带有偏差的信息,从而判断出一个数据是真实的或是虚假的。但是“真实或虚假”并不是“蕴含或不蕴含”,因为某些虚假的摘要如果蕴含了足够的信息,也可以是蕴含的。这也是为什么DocNLI特别提到需要删除一些人工痕迹的原因。
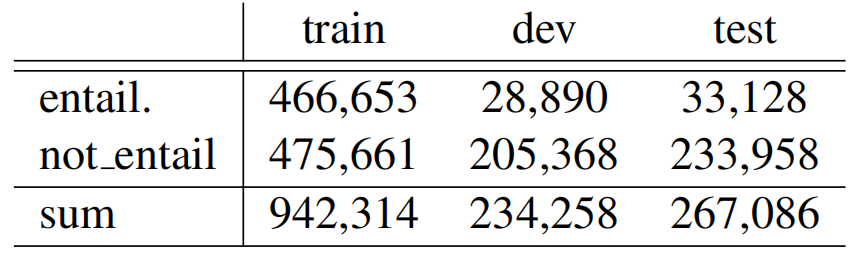
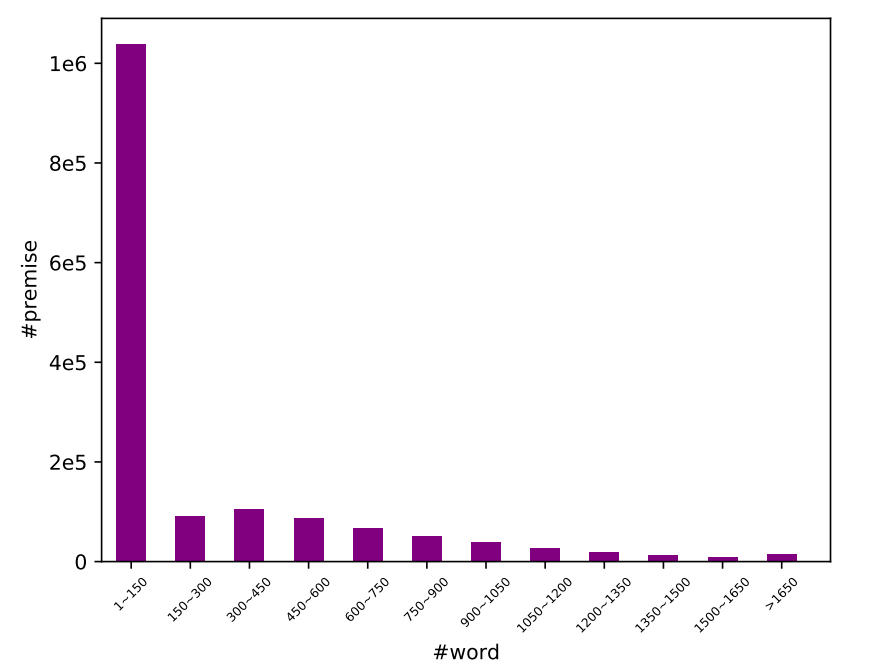
下图4、5显示了DocNLI的文本长度,可以看出前提部分长度普遍较长,假设部分长度长短不一。
此外,数据集还经过了人工检验,作者从假数据中任意抽取了200条“假”摘要,交给人类评测,评测主要是两条:(1)是否真的不蕴含(2)是否有语法错误。其中200条数据均属于不蕴含,但是仍存在一些语法错误。
对于构建好的DocNLI,作者利用了一些实验说明该数据集的挑战性,以及数据集训练的模型对于下游任务的可扩展性。
首先,作者使用了在NLI数据集上表现非常好的RoBERTa模型,以及在长文本上表现好的Transformer的变体Longformer,并添加了一组只用hypothesis训练的RoBERTa作为对照组。
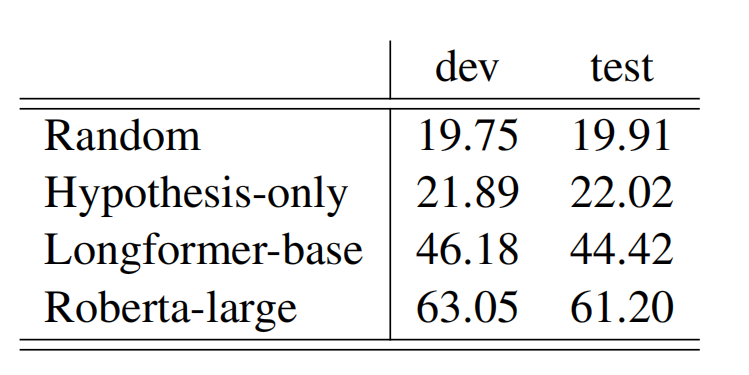
可以看到只用hypothesis的对照组基本和随机猜测没有太大区别,而其他方法的F1值也都十分的不理想,可以看出,这是一个非常具有难度和挑战性的数据集。作者也通过文本长度的实验证明了,数据集的难度很大程度来自于文本长度。这也符合NLI任务的想法,即考量一个模型对于自然语言理解的能力,长文本、短文本的理解能力都要考虑。
关于数据集训练的模型,对于下游任务是否具有可扩展性,作者使用了FEVER数据集的NLI版本以及MCTest两个数据集作为验证。
表6 在其他NLP任务上的表现
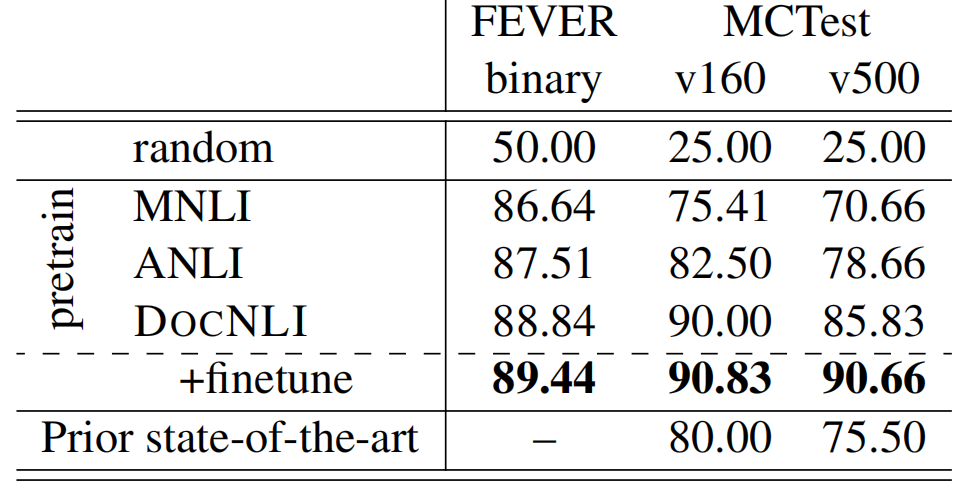
可以看到相比其他的NLI数据集训练出来的模型,使用DocNLI训练的模型,在其他任务上表现的更理想,说明模型通过DocNLI的训练,获得了更强的语言理解能力。
此外,为了验证数据集是否会因为长度过长而影响短文本的理解能力,作者又在两个长度偏短的NLI数据集上验证了自己的模型。
表7 短文本NLI数据集上的表现
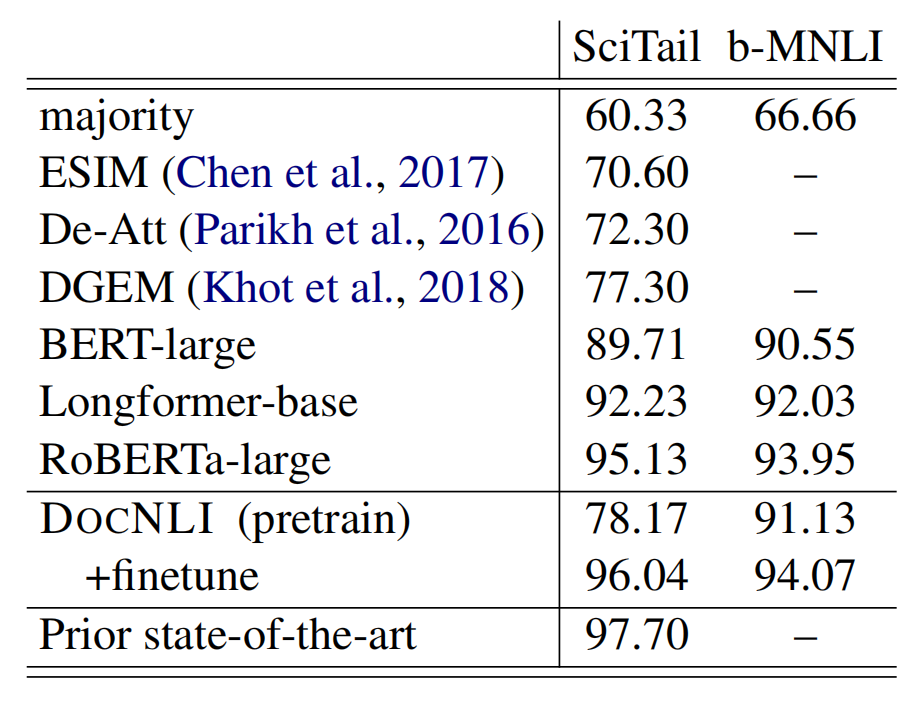
看得出来,经过微调的DocNLI数据集非常接近之前的SOTA,反映了DocNLI训练的模型,对于短文本的理解能力也是不错的。
最后,值得注意的是,所有的上述模型的训练,均是基于RoBERTa和LongFormer,并没有使用新的模型结构。作者也在最后提出展望,希望能够有新的模型能够在DocNLI上有出色的表现。
参考资料
Ido Dagan; Dan Roth; Fabio Zanzotto; Mark Sammons, Recognizing Textual Entailment: Models and Applications , Morgan & Claypool, 2013.
[2]Yin W , D Radev, Xiong C . DocNLI: A Large-scale Dataset for Document-level Natural Language Inference[J]. 2021.
[3]郭茂盛, 张宇, 刘挺. 文本蕴含关系识别与知识获取研究进展及展望[J]. 计算机学报, 2017, 40(4):889-910.
[4]Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
[5]Adina Williams, Nikita Nangia, and Samuel R Bowman. 2017. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426.
[6]Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. 2015. A large annotated corpus for learning natural language inference. arXiv preprint arXiv:1508.05326.
[7]Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2019. Super glue: A stickier benchmark for general-purpose language understanding systems. arXiv preprint arXiv:1905.00537.
[8]Nie Y , Williams A , Dinan E , et al. Adversarial NLI: A New Benchmark for Natural Language Understanding[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
[9]James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and verifification. In NAACL-HLT, pages 809–819.
[10]Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019b. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[11]Dorottya Demszky, Kelvin Guu, and Percy Liang. 2018. Transforming question answering datasets into natural language inference datasets. CoRR, abs/1809.02922.
本期责任编辑:赵森栋
理解语言,认知社会
以中文技术,助民族复兴



