赛尔译文 | 基础模型的机遇与风险 (七)
原文:On the Opportunities and Risks of Foundation Models 链接:https://arxiv.org/pdf/2108.07258.pdf 译者:哈工大 SCIR 张伟男,朱庆福,聂润泽,牟虹霖,赵伟翔,高靖龙,孙一恒,王昊淳,车万翔(所有译者同等贡献) 转载须标注出处:哈工大 SCIR
编者按:近几年,预训练模型受到了学术界及工业界的广泛关注,对预训练语言模型的大量研究和应用也推动了自然语言处理新范式的产生和发展,进而影响到整个人工智能的研究和应用。近期,由斯坦福大学众多学者联合撰写的文章《On the Opportunities and Risks of Foundation Models》,将该模型定义为基础模型(Foundation Models),以明确定义其在人工智能发展过程中的作用和地位。文章介绍了基础模型的特性、能力、技术、应用以及社会影响等方面的内容,以此分析基于基础模型的人工智能研究和应用的发展现状及未来之路。鉴于该文章内容的前沿性、丰富性和权威性,我们(哈工大 SCIR 公众号)将其翻译为中文,希望有助于各位对基础模型感兴趣、并想了解其最新进展和未来发展的读者。因原文篇幅长达 200 余页,译文将采用连载的方式发表于哈工大 SCIR 公众号,敬请关注及提出宝贵的意见!

-
引言 -
能力 -
应用 -
技术 -
社会 5.1 不平等和公平 5.2 滥用 5.3 环境 5.4 合法性 5.5 经济 5.6 规模伦理
-
结论
5.社会
基础模型的社会影响,涉及模型本身的构建及其在开发应用中的作用,需要仔细检查。具体来说,我们预计基础模型将产生难以理解的广泛社会后果:基础模型是不直接部署的中间件,也是用以进一步自适应的基础。因此,使用传统方法对技术的社会影响进行推理可能会有些复杂;对于具有明确目的的系统来说,社会影响会相对更容易掌握,但难度依旧较高。在本章中,我们将讨论如何应对并开始理解基础模型的社会影响的复杂性。具体来说,我们讨论(i)不公平(§5.1: 不平等和公平)和滥用(§5.2: 滥用)方面的危害,(ii)对经济(§5.5: 经济)和环境(§5.3: 环境)的影响,以及(iii)关于法律(§5.4: 合法性)和伦理(§5.6: 规模伦理)的更广泛的考虑。
5.1 不平等和公平
Authors: Rishi Bommasani, Fereshte Khani, Esin Durmus, Faisal Ladhak, Dan Jurafsky
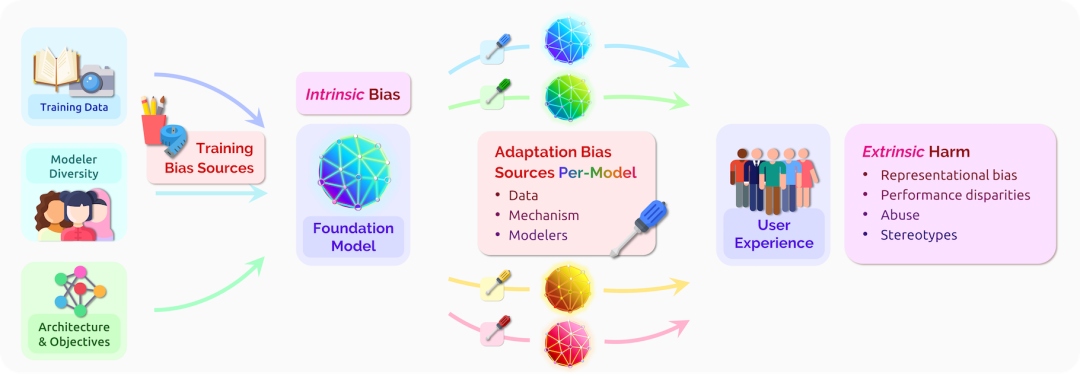
图1 基础模型中存在的内在偏见是各种训练偏见源(左)的副产品,它与适配过程中引入的偏见共同决定了用户在特定下游应用背景下所经历的外在危害(右)。我们强调,相同的基础模型是众多不同应用共享的基础;因此,它的偏见普遍存在于众多应用之中。此外,由于用户所经历的危害是特定适配模型的结果,因此将这些危害归因于该图中描述的各种过程和来源是非常重要的,但也具有挑战性。
5.1.1 引言.
基础模型有可能产生不平等的结果:它对人们的待遇是不公正的,导致该结果的一个重要原因是历史性歧视 [Hellman 2021] 因素造成的不均衡分布。像任何 AI 系统一样,基础模型可以通过产生不公平的结果、巩固权力系统以及不成比例地将技术的负面影响分配给那些已经被边缘化的人来加剧现有的不平等。
在这里,我们想了解基础模型与哪些有关公平的危害是相关的,哪些资源导致了这些危害,以及我们该如何进行干预以解决这些危害。我们在这里讨论的问题和算法公平与人工智能伦理 [Corbett-Davies and Goel 2018; Chouldechova and Roth 2020; Hellman 2020; Johnson2020; Fazelpour and Danks 2021]、种族与技术 [Benjamin 2019; Hanna et al. 2020; Gebru 2021;Field et al. 2021] 以及社会与技术的共存等一系列广泛的问题密切相关 [Abebe et al. 2020]。
5.1.2 危害.
基础模型是在适配前没有特定用途的中间产物;想要了解它们的危害,需要先推理它们的特性以及它们在构建特定任务的模型中所扮演的角色。我们描述了内在偏见1例如,间接但普遍影响下游应用的基础模型的属性,以及外在危害,例如,在特定下游应用 [Galliersand Spärck Jones 1993] 背景下出现的危害。
内在偏见 基础模型的属性可能会对下游系统造成危害。因此,尽管隐式偏见或危害 [DeCampand Lindvall 2020] 本身仅能在基础模型适配和应用后才能体现,但也是可以直接测量的。我们专注于研究最广泛的内在偏见形式,表示偏见,特别是考虑到误表示(misrepresentation)、欠表示(underrepresentation)和过表示(overrepresentation)。人们可能会被有害的刻板印象 [Bolukbasi et al. 2016; Caliskan et al. 2017; Abid et al. 2021; Nadeem et al. 2021; Gehman et al.2020] 或消极态度 [Hutchinson et al. 2020] 所误表示,这些印象和态度会通过下游模型传播并强化社会中的误表示 [Noble 2018; Benjamin 2019]。人们可能被欠表示或完全抹除,例如,当LGBTQ+ 身份术语 [Strengers et al. 2020; Oliva et al. 2021; Tomasev et al. 2021] 或描述非裔美国人的数据 [Buolamwini and Gebru 2018; Koenecke et al. 2020; Blodgett and O’Connor 2017] 被排除在训练集之外时,下游模型将在测试时难以处理类似的数据。人们可以被过表示,例如,BERT 似乎默认编码了一个以英语为中心的视角 [Zhou et al. 2021a],它可以放大多数派的声音并造成了同质化视角 [Creel and Hellman 2021] 或单一文化 [Kleinberg and Raghavan 2021] (§5.6: 规模伦理)。这些表示偏见与所有 AI 系统有关,但它们的显著程度在基础模型范式中得到了极大的强化。由于基础模型作为基础服务于无数应用程序,人们在表征方面的偏见普遍存在于众多应用程序和设置中。此外,由于基础模型承担了大部分繁重工作(与通常旨在轻量化的适配相比),因此我们预计这些一直以来的危害中的大多数将在很大程度上取决于基础模型的内部属性。
1 我们使用偏见,一词来表示基础模型导致不公平的属性;我们遵循 Blodgett et al. [2020] 来尽可能地试图描述受到危害的对象以及他们受到危害的方式。
外部危害 用户可能会从基础模型适配的下游应用中体验到特定的危害。这些危害可以是表示层的 [Barocas et al. 2017; Crawford 2017; Blodgett et al. 2020],例如信息检索系统对黑人女性的性别化描述 [Noble 2018],机器翻译系统默认男性的代词性别错误 [Schiebinger 2013,2014]、或有害刻板印象的产生 [Nozza et al. 2021; Sheng et al. 2019; Abid et al. 2021]。它们可能是由滥用构成的,例如基于基础模型的对话代理以有害内容 [Dinan et al. 2021; Gehman et al.2020] 或微攻击 [Breitfeller et al. 2019; Jurgens et al. 2019] 攻击用户。所有这些面向用户的行为都可能导致心理伤害或有害刻板印象的强化 [Spencer et al. 2016; Williams 2020]。除了个人遭受的伤害之外,群体或子群体也可能受到诸如群体级表现差异之类的危害。例如,系统可能在非裔美国人英语 [Blodgett and O’Connor 2017; Koenecke et al. 2020] 的文本或语音上表现不佳,在根据临床笔记检测医疗状况时在种族、性别和保险状态等方面的少数群体上发生错误 [Zhang et al. 2020b],或者未能检测肤色较深的人脸 [Wilson et al. 2019;Buolamwini and Gebru 2018]。随着基础模型在包括高风险领域的更广泛的应用,这些差异可能会演变成更深、更严重的危害。Koenecke et al. [2020] 讨论了如果非裔美国英语使用者无法可靠地使用语音识别技术(例如,由于底层基础模型的不平等),这可能意味着他们无法从某些衍生产品(例如,语音助手、辅助技术)中受益,并且如果这些技术被用于进行就业面试或转录法庭诉讼程序,他们将会处于不利地位。更一般地说,表征这些群体级的危害(并为那些被害者伸张正义)还需要人工智能社区提高对基于群体的偏见 [Allport 1954]和社会群体的理解:我们整理的相关工作包括社会科学和超越二元性别的处理 [Lindsey2015; Westbrook and Saperstein 2015; Richards et al. 2017; Darwin 2017; Keyes 2018; Hyde et al.2019; Cao and Daumé III 2020; Dinan et al. 2020],更细致的种族处理,[例如, Penner andSaperstein 2008; Freeman et al. 2011; Saperstein and Penner 2012; Saperstein et al. 2013; Pennerand Saperstein 2015; Field et al. 2021], 更好地解决交叉身份 [例如, Crenshaw 1989; Nash 2008;Gines 2011; Penner and Saperstein 2013; Ghavami and Peplau 2013; Bright et al. 2016; Buolamwiniand Gebru 2018; May et al. 2019; O’Connor et al. 2019; Guo and Caliskan 2021], 以及更现代的残疾处理 [例如, Batterbury 2012; Spiel et al. 2019; Hutchinson et al. 2020] 等社区。
其他注意事项 为了更全面地理解基础模型的危害,需要进一步以(以文档)记录内在偏见和外在危害;未来的工作应该阐明内在偏见和外在危害之间的关系 [Blodgett et al. 2020, 2021;Goldfarb-Tarrant et al. 2021]。该文档要求将利益相关者置于学术界和行业从业者之外:基础模型的不平等影响将主要由少数群体承受,他们在学术界和工业界均是欠表示的。特别是对于基础模型,它们的创建和研究可能将由具有所需访问权限和资源的人进行,这进一步强调了以边缘化声音为中心的场景的重要性 [D’Ignazio and Klein 2020, §5.6: 规模伦理]。特别地,用户们对特定适配模型的研究在跨应用程序聚合时,可以提供关于基础模型内在偏见的令人信服的个性化文档,并且这些文档均是以个体用户为中心的。在这种方式下,我们可以想象到,人机交互 (HCI) 方法可以通过一些调整来兼容基础模型中涉及的抽象表示,进而帮助边缘化社区的声音的中心化(在 §2.5: 交互中进一步讨论)。
5.1.3 资源.
为了充分表征和适当干预基础模型的危害,我们必须能够追溯到基础模型和适配过程的属性的来源,并进一步分解为各个偏见来源 [Friedman and Nissenbaum 1996]. 溯源对于过往危害的伦理和法律责任的归因至关重要,当然,归因将需要创新性的技术研究,例如因果 [Pearl 2000] 和推断 [Koh and Liang 2017] 等。
数据 基础模型的各类型数据塑造了其应用的行为以及相关的外在危害,上述数据类型包括:用于基础模型训练的训练数据、用于基础模型适配的适配数据以及测试时的用户数据/交互。对于所有这些数据源,数据的属性(例如,有害和仇恨言论 [Henderson et al. 2017]、辱骂性语言 [Waseem et al. 2017]、微攻击 [Breitfeller et al. 2019],刻板印象 [Voigt et al. 2018]) 将体现在基础模型(及其适配变体)的偏见中2。由于训练数据是决定基础模型和相关内在偏见的关键数据源,因此我们在这里重点关注训练数据。目前,训练数据以及相关数据实践(例如,数据管理、数据选择和数据加权 [Paullada et al. 2020; Bender et al. 2021; Rogers 2021])与基础模型获得的内在偏见之间的关系仍不清楚;未来工作迫切需要澄清这种关系。由于基础模型通常需要大规模的训练数据,这不仅对其文档构建 [Bender et al. 2021] 、同时还对数据偏见和模型偏见之间关系的全面、科学探索提出了明显的挑战,我们预计上述规模的问题的解决将需要新的协议。建立起类似于准确性指标的偏见比例规律 [Kaplan et al. 2020;Henighan et al. 2020] ,有可能会使小规模系统性研究为大规模数据实践带来启发。
2 带标签的限定任务数据中,标签空间选择的偏见 [Crawford 2021] 和数据标注者的偏见 [Geva et al. 2019; Sapet al. 2019] 也可能导致用户经历外在危害。
建模 建模决策(例如,训练目标(§4.2: 训练)、模型架构(§4.1: 建模)、适配方法(§4.3: 适 配))会影响基础模型及其变体的偏见,从而影响所经历的外在危害。尽管其背后的诱发属性和机理尚不明确,但现有工作已证明基础模型放大了训练数据偏见,扩展了机器学习和深度学习模型的趋势 [Zhao et al. 2017; Wang et al. 2019d; Jia et al. 2020; Hashimoto et al. 2018]。此外,考虑到直接应用基础模型可能是不可行的(由于它们的规模),模型压缩或有效性提升的努力似乎也会放大偏见 [Hooker et al. 2020; Renduchintala et al. 2021]。基础模型改变社会行为并引发社会学变化的反馈循环也可能加剧放大,从而改变后续的训练数据;这种形式的反馈效应往往会加剧其他机器学习应用中的不公平性 [Lum and Isaac 2016; Ensign et al.2018; Hashimoto et al. 2018]。除了在训练和应用基础模型中做出的明确决策之外,社区价值观 [Birhane et al. 2020] 和规范(§5.6: 规模伦理)都间接和隐含地 [Liu et al. 2021b] 塑造了构建模型的决策。因此,测量偏见、引入基础模型 [例如, Brown et al. 2020] 和标准基准[Friedman and Nissenbaum 1996, §4.4: 评估]、研究不同用户群体以记录经历危害的文档这些工作相结合,是确保强调对偏见和不公平的考虑的最佳实践。
建模者 与所有算法系统一样,在开发或应用基础模型的决策机构中,利益相关者和边缘化社区的代表性和多样性较差,这本身就存在问题,并可能对这些社区造成更大的伤害3。虽然难以记录,但现有的开发基础模型的努力表明了一种可能性:Caswell et al. [2021] 证明了用于训练多语种语言模型的数据是欠表示的有缺陷数据,Hutchinson et al. [2020] 表明模型通常包含对残疾人的不良偏见。在这些情况下,如果开发团队有这些群体更好的表示,这些偏见和危害就有可能被更早的发现。此外,由于终端用户可能比开发人员更加多样化,并且可能更早地注意到这些问题,因此允许用户反馈以帮助基础模型设计维护(§2.5: 交互)是一个重要的前进方向。
3 我们注意到关于学科背景和人口特征的多样性,在这些具有高影响力的决策环境中具有根本的重要性,其原因远远超出了对公平相关危害的潜在改进认知
5.1.4 干预和追索.
解决、减轻和纠正与技术相关的不平等需要整合社会性和技术性方法 [Abebe et al.2020]。特别是对于基础模型,我们同时考虑了改变模型开发部署方式以预防性地减少危害的主动方法,以及响应危害并为未来做出改变的反应性方法。就其核心而言,基础模型的抽象使以下两个方面都变得复杂:了解基础级别的干预是否成功地减少了损害需要在特定部署的应用级别进行下游观察,而在发生损害时的追索需要对基础模型提供者进行上游反馈和问责。
Intervention. 干预 技术系统干预管理的一般原则适用于基础模型设置:对偏见或危害负有最大责任的来源的确定,为目标动作提供了所需的依据。例如,技术(例如,基础模型)的设计、生产和控制 [Longino 1990; Harding 2015; Nielsen et al. 2017; O’Connor et al. 2019; Hofstraet al. 2020; Katell et al. 2020] 团队迫切地需要多样性的提升,如果多样性缺乏被证明与危害[Caswell et al. 2021] 相关,那么该需求还会进一步加剧。此外,透明化文档 [例如, Gebruet al. 2018; Bender and Friedman 2018; Mitchell et al. 2019] 和审计 [例如, Raji and Buolamwini2019] 在提供干预和变革的动力方面同样至关重要 [Burrell 2016; Lipton 2018; Creel 2020; Rajiet al. 2020; Wilson et al. 2021]。基础模型的规模及其细节的可访问性为现有的文档和审计协议带来了新的挑战,我们在 §5.6: 规模伦理 中进一步讨论了这些挑战。
迄今为止,在基础模型领域中为减少技术的不公平影响而考虑的许多干预措施都是以数据为中心(以避免不公平或偏见的反映)和涉及建模决策(以避免放大数据偏见)的技术缓解方法。在基础模型领域中特别重要的是认识到这些缓解方法可能针对流水线中的不同步骤,例如训练数据 [例如, Lu et al. 2020]、目标函数建模 [例如, Zhao et al. 2018],适配方法和测试用途 [例如, Park et al. 2018; Zhao et al. 2019]。因此,不同的方法不仅可能有效程度不同,而且需要来自不同实体(例如,基础模型提供者与应用开发人员)的动作,并且不同程度地影响这些模型的昂贵的训练过程(例如,基础模型初始化过程改变与后验改变)。这种形式的技术干预也可能针对不同的目标:一些干预,例如改变训练数据,旨在减少 内在偏见。另一方面,大多数在算法/机器学习公平性方面的缓解工作转而考虑减少模型行为方面的结果差异,例如,与外在危害更直接相关的下游系统的输出。目前所有形式的技术缓解都受到严重限制:衡量或对抗内在偏见的方法是脆弱的或无效的,衡量或消除外在结果差异的方法可能与利益相关者的目标不一致 [Saha et al. 2020],并且有一些证据表明某些类型的技术干预可能同时是无法令人满意的 [Corbett-Davies and Goel 2018; Kleinberg et al.2017] 和不可能的 [Lechner et al. 2021] ,甚至可能加剧不平等 [Xu et al. 2021]。尽管如此,我们仍然相信技术方法仍将在解决基础模型领域中出现的危害方面发挥重要作用;总的来说,我们提倡透明度,特别是考虑到技术缓解方法可能无法实现预期目标。更广泛地说,偏见的提出和消除必须谨慎,以便向具有不同专业知识的各种利益相关者清楚地传达现状(例如,基础模型之上的应用开发人员和监管技术的政策制定者 [Nissim et al. 2020])。
Recourse. 追索权 不幸的是,主动干预不太可能完全解决因基础模型而可能出现的所有潜在危害或不平等。当危害发生时,目前没有广泛采用(或法律要求)的框架来解决受害方合理的追索权。虽然特定应用可能存在某些协议,但基础模型的抽象再次导致了脱节:损害可能部分归因于基础模型提供者和下游应用开发人员,但将这一责任分配给哪一方仍然具有挑战性。更简单地说,甚至没有将这些危害传达给基础模型提供者的机制(即使向应用开发人员提出了反馈或投诉)。因此,关于应用开发人员和终端用户的反馈应如何向上游传递到基础模型提供者,如何确定对这些危害负责的实体(例如,基础模型提供者、应用开发人员),以及与法律责任的关系(§5.4: 合法性),需要新的规范和标准。为了在这个问题上取得进展,我们鼓励未来的工作参考其他领域中使用的实践(尤其是那些具有类似抽象和多实体结构的领域),我们预计引入的任何标准都可能需要合理的动态性,以便他们能够与这些模型及其应用迅速变化的现状保持同步。
5.1.5 其他.
机器学习有着不公平影响的既定记录,其大部分危害由边缘化社区承担。基础模型为危害的计算带来了新的挑战,但最终,为了使其社会影响公平,需要进行大量研究和变革,以了解它们造成的危害并有意义地解决和纠正这些危害:
(1) 基础模型的一对多性质,即在众多应用中使用相同的少数基础模型,意味着基础模型的内在属性遍及许多下游应用。因此,这些模型中的有害偏见对所经历的危害产生了巨大的影响。
(2) 基础模型领域中的偏见和危害存在多种来源(例如,训练和适配数据、建模和适配决策、建模者多样性和社区价值)。偏见和危害的归因是干预和责任问题的基础;而归因则需要新的技术性的研究才能可靠地完成。
(3) 基础模型的不公平并非不可避免的,但解决它们需要多管齐下的方法,包括主动干预(例如,数据中心化和模型中心化的更改)和反应性追索(例如,反馈和问责机制)。
5.2 滥用
Authors: Antoine Bosselut*, Shelby Grossman*, Ben Newman
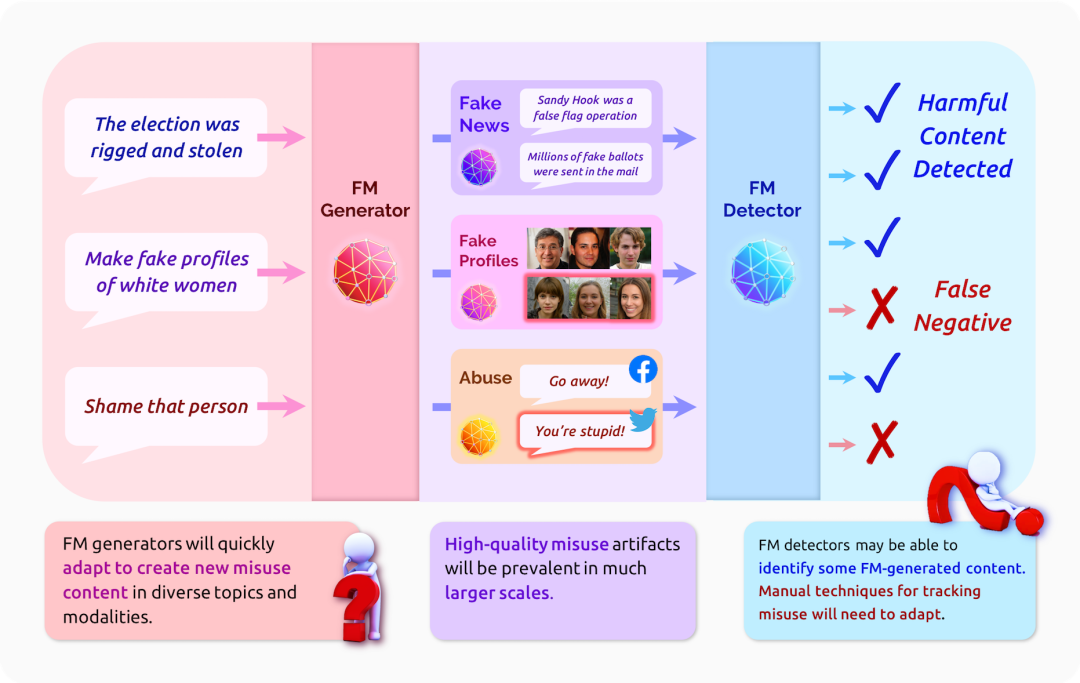
图2 该图显示了基础模型对操纵性、有害内容生成以及检测的影响。
在本节中,我们考虑基础模型的滥用 — 人们按照预期用途(例如,语言生成)使用基础模型,但别有用心的人却利用其能力对群体或个人造成伤害的情况。此定义将滥用问题定位在了不平等(模型可以在没有恶意的情况下造成危害;§5.1: 不平等和公平)和安全(不良行为者利用模型中无意的能力或漏洞造成危害;§4.7: 安全和隐私)之间。下面,我们概述了基础模型如何导致了新形式的滥用以及如何支撑新的滥用检测和缓解工具。
5.2.1 基础模型将被滥用于有害目的.
生成式基础模型在规模(§4.2: 训练)、多模态(§4.1: 建模)和适配性(§4.3: 适配)方面的进步将允许它们被滥用来生成高质量、廉价和个性化的用于有害目的的内容。在本节中,我们将在以下两个恶意活动示例的背景下讨论这三个维度:操纵性内容创建和骚扰。
内容质量 与之前的 AI 方法相比,基础模型能够自动生成质量更高、更人性化的内容。它们可能会帮助虚假信息行为者,例如,在这种情况下,地方可以创建欺骗外来民众的内容,而不会透明地表明内容与地方有关。目前,创建此内容通常需要雇用会说目标人群语言的人员。政府可能会将内容制作外包给目标地区的母语人士4,5。,但这个决定会给运营安全带来真正的风险。基础模型将使得创建的内容通常与人类创建的内容没有区别 — 同时满足引发共鸣的内容创建和运营安全的目标。
4 https://www.lawfareblog.com/outsourcing-disinformation
5 https://fsi.stanford.edu/content/ira-takedown-20201215
除了欺骗外来人口外,基础模型生成高质量合成图像(深度伪造)或文本的能力可能会被滥用来骚扰个人。深度伪造已经被用于骚扰。例如,印度调查记者拉娜·阿尤布 (Rana Ayyub) 遭到了高质量深度伪造的攻击,该攻击将她的脸叠加在色情视频上,导致她离开公众生活数月6。由于基础模型通常是多模态的 (§4.1: 建模),它们同样可以模仿语音、动作或文字,并可能被滥用来捉弄、恐吓和勒索受害者7。
6 https://www.huffingtonpost.co.uk/entry/deepfakeporn_uk_5bf2c126e4b0f32bd58ba316
7 https://www.wsj.com/articles/fraudsters-use-ai-to-mimic-ceos-voice-in-unusual-cybercrime-case-11567157402
5.2.2 基础模型将成为有害内容的强大检测器.
虽然基础模型的生成能力将提供大量的滥用机会,但相同的能力也可能使它们成为有害内容的强大检测器。虽然这些功能对人类生成内容检测和模型生成内容检测同等相关,但我们在本节中重点关注模型生成内容检测。首先,我们概述了当前手动检测方法在发现基础模型的有害滥用方面将面临的挑战。然后,我们提出了基础模型的交互式和多模态表示能力如何使其成为自动检测有害内容的强大工具。最后,我们讨论了与在在线环境中部署自动检测模型以打击潜在的基础模型滥用相关的风险。
重新思考人为干预 目前,恶意行为通常可借助互联网上的内容来源搜索来发现(在社交媒体上,有时会进行删除)8 。例如,虚假的社交媒体个人资料通常会从约会网站窃取个人资料照片,这些照片可以通过反向图像搜索来发现。同样,虚假信息网站经常使用抄袭内容来掩盖欺骗性内容 [DiResta and Grossman 2019],通过进行互联网短语搜索很容易识别。基础模型将限制这些检测策略的有效性。相对简单的虚假宣传活动已经利用人工智能生成的照片9 。以消除被反向图像搜索发现的可能性。用于评估这些照片(同样地,还有文本和视频)是否是 AI 生成的工具是存在的,但基础模型将使这项工作复杂化,对人类手动发现技术提出了挑战 [Ippolito et al. 2020; Clark et al. 2021]。
8 https://www.theatlantic.com/ideas/archive/2020/09/future-propaganda-will-be-computer-generated/616400/
9
有关中东活动的示例,请参阅
https://www.thedailybeast.com/right-wing-media-outlets-duped-by-a-中东宣传运动
有关古巴的示例,请参阅
https://raw.githubusercontent.com/stanfordio/publications/main/twitter-CU-202009.pdf
作为探测器的基础模型。使基础模型成为强大的创意内容生成器的能力,也可能使它们成为强大的模型生成内容检测器。现有工作表明,基础模型可用于检测来自(生成统计文本[Holtzman et al. 2020] 的)文本生成器 [Zellers et al. 2019b] 的虚假信息,还可用于根据提示问题评价自身生成结果的有害性程度 [Schick et al. 2021]。下面,我们将描述未来的基础模型将如何创建更强大的机器生成的有害内容检测系统。
基础模型的交互式多模态界面的改进将为基础模型滥用的有害内容生成检测的提升提供新的机会。当前的统计检测器必须重新训练和重新部署,以整合关于滥用策略 [Dinanet al. 2019] 的文本内容的新知识。基础模型的快速学习能力 (§4.3: 适配) 可能使它们能够从人类反馈中适应新的滥用策略,即使基础模型最初未被训练来识别该策略。
同时,基础模型的多模态能力将强化生态系统滥用的表示的表达能力。先前的工作探索了虚假信息如何比真实内容在社交网络中传播得更快 [Starbird et al. 2018; Vosoughi et al.2018],通过回顾分析获取可识别的签名。基础模型的多模态能力可以让它们联合学习有害内容及其在社交网络上的典型传播签名的表示。这些联合表示可以提供强大的工具来预测某些类型的自动生成的内容是否表明了滥用行为。
基础模型作为自动探测器的风险 针对模型生成的和人生成的有害内容的自动检测系统的改进将使这些系统在网上更加流行,从而产生潜在的负面后果。任何检测系统都会有假正例情况 (人生成的合适内容被标记为有害) [Sap et al. 2019; Xu et al. 2021]。算法误报影响用户(或用户组)的比率可能在下游导致危害(§5.1: 不平等和公平)。基础模型的适配能力应该使系统性假正例更容易解决,因为模型可以进行局部编辑以重新分类这些示例(§4.3: 适配)。然而,一些极端情况可能不会被优先考虑,这些情况下的追索将具有挑战性。
更广泛地说,滥用检测系统的大规模部署可能会引发有害内容生成器和检测器之间的“军备竞赛”。大多数使用基础模型的内容生成器缺乏单独开发的资源,并将使用由大公司部署的系统。虽然使用条款政策应概述这些系统的可接受用途(§5.6: 规模伦理),但基础模型的部署者还需要内部检测系统来识别其产品的滥用10 并减少滥用(§5.4: 合法性)。但是,对于拥有资源来开发自己的基于基础模型的内容生成器的滥用行为者,对其控制是相对较少的,这为分发策划内容的平台带来了压力。乐观地看,内容平台包括世界上一些资本最充足的公司。他们的资源可能使探测器的开发超出大多数个人滥用代理的能力。由于重复大规模训练这些系统的成本很高,这种资源优势可能会抑制个体基础模型的开发。然而,即使没有最大的基础模型为其提供支持,许多基础模型滥用的实例仍然可能成功,特别是因为攻击者可能利用基础模型的交互功能快速生成可以逃避检测的内容。
10 https://www.wired.com/story/ai-fueled-dungeon-game-got-much-darker/
5.3 环境
Authors: Peter Henderson, Lauren Gillespie, Dan Jurafsky
基础模型可能会带来众多社会和环境效益,例如在法律领域 (§3.2: 法律)、医疗保健(§3.1: 医疗保健和生物医学),甚至气候变化应对 [Rolnick et al. 2019] 等方面。但由于它们的规模较大,如果模型创建者不仔细应对,其自身会因碳排放量增加而对环境产生负面影响 [Strubell et al. 2019; Lottick et al. 2019; Schwartz et al. 2019; Lacoste et al. 2019; Cao et al. 2020;Henderson et al. 2020; Bender et al. 2021; Patterson et al. 2021; Lannelongue et al. 2021; Parcolletand Ravanelli 2021]。解决此类排放问题势在必行:目前的预测表明,气候变化产生的速度比以前想象的要快 [Masson-Delmotte et al. 2021]。
为了了解基础模型中可能发生此类排放的位置,我们考虑了它们的生命周期。首先,它们接受了大量数据的训练,该训练可能长达数月并通常分布在数百至数千个 GPU上。之后,它们可能会适配到新的领域或被蒸馏成更小的模型。所有这些都可以被视为训练制度的一部分。纯粹用于研究的模型可能不会超出这些步骤的范畴。在模型经过适配和/或蒸馏之后,它们可能会继续部署到生产中。此时将通过模型进行多轮推理,直到训练出新模型并重复循环迭代。
这些步骤中的每一步都有可能使用大量能源并导致碳排放。在初始训练阶段,基础模型可能会产生大量的一次性能源成本和碳排放。例如,在某些条件下,训练一个基于 BERT的模型所产生的排放量要 40 棵树耗费 10 年才能抵消11 。如果大规模地部署,基础模型可能需要大量能量来服务数百万个请求12— 如果使用不可再生资源则会转化为大量碳排放。
11 Strubell et al. [2019] 计算了在美国平均能源网上训练 BERT 的碳排放量,我们使用 https://www.epa.gov/energy/greenhouse-gas-equivalencies-calculator 将其转换为其他领域的等效排放量。我们注意到,这个数字可能会因能源网和其他考虑因素而有所差异 [Henderson et al. 2020; Patterson et al. 2021]。
12 例如,transformer 已经在微软和谷歌中大规模地用于搜索。请参阅 https://www.blog.google/products/search/search-language-understanding-bert/ 和 https://azure.microsoft.com/en-us/blog/microsoft-makes-it-easy-to-buildpopular-language-representation-model-bert-at-large-scale/。
因此,训练和部署基础模型的某些决策设计对环境的影响可能很大。即使是看似微不足道的决定,例如减少模型的层数,也可能导致环境成本的大规模显著性降低。例如,根据Henderson et al. [2020] 的计算,以商用翻译服务规模部署的稍微节能一点的翻译模型,根据能源网的不同,每日可以节省 78 kgCO2eq 至 12,768 kgCO2eq 的碳排放量。这大致相当于 1 至 211 棵树生长 10 年所固存的碳,或 0.35 至 57.4 英亩森林一年内所固存的碳13 。因此,基础模型的设计、部署和部署后的监控应充分反映这些风险。
13 固碳估计来自 https://www.epa.gov/energy/greenhouse-gas-equivalencies-calculator,其他估算方法的结果可能更高。更高效的能源网将排放更少的碳,导致影响的估计值区间较大。
当然,在计算任何给定模型所使用的能量或碳排放量时均存在不确定性 [Hendersonet al. 2020; Cao et al. 2020; Patterson et al. 2021],目前其他排放源可能比基础模型产生的排放量大得多 [Mora et al. 2018]。但是,如果基础模型继续扩大规模并越来越受欢迎,它们很可能会成为碳排放的重要贡献者。我们的目标是为基础模型开发者和大规模部署者提供一个框架14,以考虑他们应如何减轻任何不必要的碳排放并保持这些模型的净社会影响是积极的。我们建议:
(1) 在许多情况下,碳影响可以而且应该得到缓解。这可以通过在低碳强度地区训练模型或者使用更高效的模型和硬件(§5.3.1: 环境-缓解)来实现。
(2) 当所有缓解机制用尽且不可能进一步缓解时,应评估社会成本和收益来确定是否应该以及何时在更小、更高效的模型上部署更大的基础模型 — 前提是了解大型基础模型的前期成本可在模型的整个生命周期内摊销(§5.3.2: 环境-成本)。
(3) 能源、计算和碳成本 — 以及为减轻负面影响而采取的任何努力 — 都应该清楚地报告给决策和研究方(§5.3.3: 环境-报告)。
14 我们专注于模型开发者和大规模部署者,比如那些在基础模型之上构建生产系统的人,因为他们最具做出有意义的改变的能力,从而减少能源使用和碳排放。他们的单项改变 — 例如使用更高效的模型 — 便可扩展到大规模的碳节省,否则将需要大规模的运作来覆盖所有下游模型用户。
5.3.1 在很多场景下我们可以也应该减轻碳影响.
训练基础模型的碳影响不同于部署它们进行推理的影响。模型训练没有延迟要求,因此可以在云环境中相对轻松地跨能源网进行训练。每个能源网都有自己的碳强度 — 每千瓦时使用的能源排放的碳量。例如,魁北克由于依赖水力发电因而碳强度极低,而爱沙尼亚的能源网由于依赖页岩油而具有极高的碳强度(尽管这种情况正在迅速变化)[Hendersonet al. 2020]。最近的研究甚至表明,污染程度排在前 5% 的发电厂贡献了所有电力排放量的73% [Grant et al. 2021]。因此,虽然训练基础模型可能非常耗能,但研究人员已经证明,通过选择碳排放量最少的能源网,可以部分减轻这些模型的碳影响 [Henderson et al. 2020; Lacosteet al. 2019; Patterson et al. 2021]。
碳补偿也被认为可以作为权宜之计,直到所有数据中心都可以使用无碳可再生电力。该策略涉及减少一项活动中的碳排放,以抵消另一项活动的排放。但大多数的 — 如果不是全部 — 碳抵消是比从一开始不排放二氧化碳更糟糕的解决方案 [Holl and Brancalion 2020]。一些碳抵消计划甚至会产生负面影响。例如,对植树活动(通常是碳抵消的来源)的研究表明,它们弊大于利。它们会导致单一栽培(使用一种特定树种),从而减少该地区的生物多样性并减少森林土壤中的碳储存 [Heilmayr et al. 2020; Hong et al. 2020b]。与最初从未排放碳的情况相比,使用碳抵消可能会导致更多的碳排放。因此,在训练或部署基础模型时,我们建议预先设计尽可能少的碳排放,而不是简单地依靠碳补偿来抵消排放。
当无法在低碳地区运行时,应利用其他的缓解策略,从而减少不必要的能源使用。具体包括:
• 使用更高效的硬件设备15 ,
• 使用混合精读训练 [Micikevicius et al. 2017] 或者量化 [Gholami et al. 2021],
• 使用更高效的架构(例如,使用改进后的 transformer 而不是原始的 transformer 架构;或使用稀疏模型)[So et al. 2019; Patterson et al. 2021; Mostafa and Wang 2019],
• 将模型蒸馏并使用蒸馏模型 (例如,[Sanh et al. 2019]),
• 并利用其他可以降低能源成本的优化策略(更多讨论参见§4.5: 系统)
15 值得注意的是,由于这个原因,加利福尼亚州现在对使用低效率 GPU 的计算机进行监管,要求它们保持在30-100 千瓦时/年以下,具体取决于制造日期和计算机类型。参见加州电器效率条例(20 )第 1601-1608 条。
开源项目和云计算的维护者应该努力将他们的默认设置设定为最高效的,因为众所周知“绿色默认(green defaults)”是最有效的缓解策略(详见 [Henderson et al. 2020] 中的讨论)。其他的环节策略在近期的以下研究中也有讨论 [Strubell et al. 2019; Lacoste et al. 2019;Schwartz et al. 2019; Henderson et al. 2020]。我们还注意到,减少能源使用还会带来一个好处,即让那些计算资源有限的人更容易接触到模型(更多的讨论请参阅 §5.6: 规模伦理)。
然而,当模型主要用于推理时,例如,部署在产品应用中,它通常不能迁移到针对低延迟应用的碳密集度较低的能源网中。在这种情况下,除了使用上面阐明的缓解策略之外,重要的是权衡提出的基础模型与更节能的替代方案的利弊。我们将在下一章节中进一步讨论这一点。
5.3.2 在使用基础模型前评估好成本和收益.
在采取尽可能多的缓解措施后(亦或无法缓解的情况下),评估所需的基础模型的大小 — 或是否应该使用基础模型则至关重要。这种成本-效益分析应考虑以下几点:
(1) 部署基础模型的社会成本和环境成本是否大于模型的社会效益?
(2) 另一种计算上更简单且更便宜的方法是否可以实现类似的社会效益(例如:一个更有效的基础模型,或者可能是简单的基线方法)
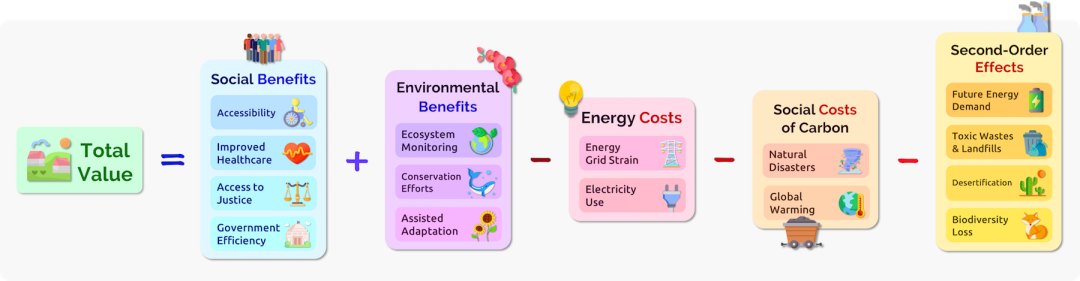
一种简化的权衡利弊方案将模型 𝑀 的整体影响抽象为:
𝑉 (𝑀) = 𝑆 (𝑀) − 𝐶(𝑀) − 𝐸(𝑀) − 𝑂(𝑀). (7)
图3 描述了上述方程以及可能输入每个变量的成本和收益。这里,𝑀 是模型,𝑆 是净社会效益和环境效益,以美元为单位。𝑆 可以通过改善医疗、诉诸司法、减少贫困、改善环境监测、帮助生态系统保护工作等来增加。
𝐶 是能源使用产生的碳的社会成本。这代表了作为当前货币价值释放的碳对社会未来的危害。从 2017 年开始,美国环境保护署 (EPA) 对碳的社会成本的估计为每排放 1 公吨 CO2不超过 $105(以 2007 年美元计)16 。
16 见https://19january2017snapshot.epa.gov/climatechange/social-cost-carbon_.html。但请注意,碳的社会成本可能是一个有争议的指标 [Stern and Stiglitz 2021]。利用适合的折扣因素(discount factor),可以降低碳成本。因此,上述指标的计算可能因方法而异。
𝐸 是模型的能耗成本。例如,2021 年 4 月,美国平均居民能耗成本约为 $0.1376 每千瓦时17 。添加这个变量可能是能源网压力增加的成本。例如,最近的一项研究表明,在按照平均需求标准化后,每次能源网中断事件的成本可能高达 $15.9 每千瓦 [Sullivan et al. 2015]18 。
17 https://www.eia.gov/electricity/monthly/epm_table_grapher.php?t=epmt_5_6_a
18 与碳的社会成本一样,计算这些成本的方法可能会因建模方法而异。
𝑂 是其他次生的环境影响的社会成本,可能包括:
• 芯片需求和芯片产量增加对复合碳的影响 [Gupta et al. 2021a]。
• 芯片制造的其他环境影响。例如在硅谷建立有毒废物场,其对健康的影响不平等地分配给社会弱势群体 [Stewart et al. 2014],或者再如在中国台湾,制造业带来的污染被指与慢性健康问题有关 [Tu and Lee 2009; Lin et al. 2016]。
• 气候变化的复合效应尚未包含在 SCC 模型中。例如,这些影响可能包括加速荒漠化 [Huang et al. 2016]、使许多物种面临灭绝风险的生态系统的快速变化 [Urban2015],以及由于永久性的冻土融化而增加的碳排放 [Schuur et al. 2015]。
• 对芯片生产能力带来不必要的压力。最近芯片短缺导致了汽车制造停工19 。并没有证据表明这种短缺是因为市场对机器学习优化过的芯片需求增加20。但上述这些顾虑属于次生效应,研究人员可能会衡量产生这种负面影响的风险,无论多么微小,是否值得使用或部署大型模型21 。
19 https://www.reuters.com/business/autos-transportation/ford-shut-some-n-american-plants-few-weeks-chipshortage-2021-06-30/
20 尽 管 最 近 的 报 告 表 明 对 数 据 中 心 芯 片 的 需 求 已 经 超 过 了 游 戏 行 业。见https://www.nextplatform.com/2020/08/21/the-local-maxima-ascension-of-datacenter-at-nvidia/.
21 与前面描述的其他指标一样,计算这些影响并归因于模型的方法仍然具有一些不确定性。
在分析中,重要的是要考虑碳的经济效益和社会成本可能在社区之间分配不均,较贫穷的社区受气候变化的影响更大,而较富裕的社区则可以受益于模型 [Bender et al. 2021]22 。因此,在分析公式 7 时,应该更宏观地考虑对社会的好处和危害,而不是针对特定的组织或国家。在这种情况下,𝑉 (𝑀) 可以被视为一种分布,理想情况下应该在整个群体中呈均匀分布。在分布高度不均匀的情况下 — 例如,所有好处都落在模型设计者身上,而所有危害都落在永远不会从模型中受益的人群身上 — 设计者应该在部署模型之前在缓解上述问题上花费更多的精力。
22可 参考
https://www.un.org/sustainabledevelopment/blog/2016/10/report-inequalities-exacerbate-climate-impacts-on-poor/和https://blogs.imf.org/2020/12/02/how-artificial-intelligence-could-widen-the-gap-between-rich-and-poor-nations/。
当然,在评估公式 7 中的每个组成部分时,使用何种方法存在一些不确定性。根据数据来源和对现象的建模选择,例如评估碳的社会成本的不同机制,对这些项的经验估计可以在不同的范围内变化。然而,这种成本效益分析的关键要点不是等式中每一项的估值,而是这些影响中每一项的存在以及相对的重要性。我们的目标是为开始权衡这些利弊提供一个高层面的框架,未来的研究可能会就如何量化这些值提供更多指导。
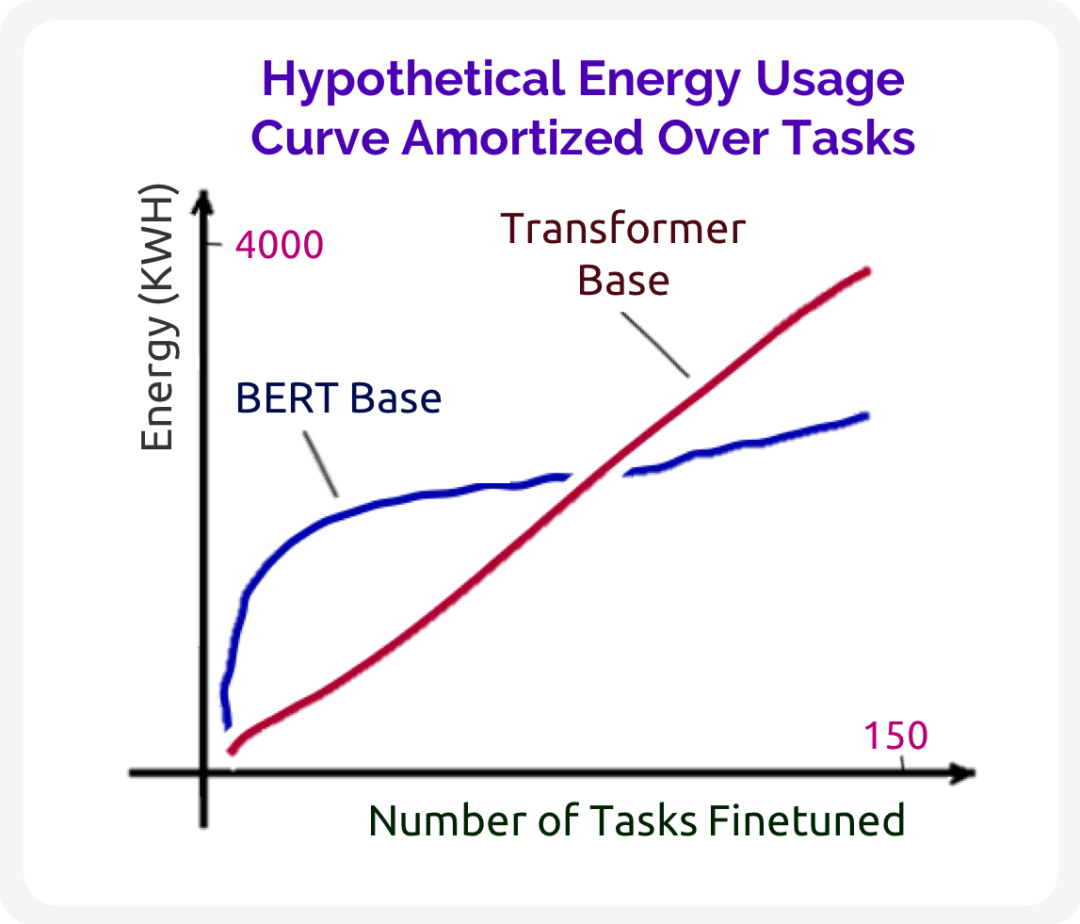
最后,我们注意到这些因素也应该在模型的整个生命周期内进行评估,而不是在每次运行的基础上进行评估。考虑一个替代的基线模型,它必须为每个新任务从头开始训练。基线模型很可能需要代价很高的超参数搜索才能在下游任务上实现等效的性能。相比之下,基础模型将成本放在初始预训练过程中,微调从而可能更简单、更节能。在基础模型的整个生命周期内,它可能比基线(如图 4)模型具有更高的碳效率。更有效的适配机制甚至可以进一步改善这种成本摊销(参见 §4.3: 适配)。
但是,适配机制的效率是不能保证的。某些基础模型可能永远不会比特定基线方法更有效,即使在许多任务上分摊时也是如此。例如,不能假设参数较少的小模型可以转化为能效的提升,由于增加的超参数调整成本或其他优化内容,在某些情况下,被证明与能效无关 [Zhou et al. 2020; Henderson et al. 2020]。因此,基础模型开发人员应在开始大规模训练之前严格评估其模型和适配机制的效率。
本节中的框架旨在指导读者在训练和部署模型时考虑环境和社会的利弊权衡,但在部署基础模型时还涉及到一些实质性的社会公平因素,在 §5.6: 规模伦理 中会继续讨论。§5.3: 环境 还更详细地讨论了算法部署带来的社会福利的变化情况。
5.3.3 应系统地报告碳/能源影响.
除非研究基础模型的研究人员和工程师提供其模型的计算、能源和碳成本,否则就无法进行成本-效益的分析。我们鼓励基础模型开发人员、提供者和管理人员报告这些指标,以及在创造基础模型时使用了哪些碳减排策略。如 [Henderson et al. 2020; Lottick et al. 2019;Lacoste et al. 2019; Schmidt et al. 2021; Anthony et al. 2020] 等工作中的碳影响声明以及为完成报告所使用的工具。对于研究人员来说,此类报告可以连同论文一同发布,但我们也鼓励行业参与者采用透明机制来提供其部署模型的这些指标23 。这将有助于在工业界和学术界制定政策建议,并帮助下游用户确定碳友好型使用模式。标准化报告还将有助于确定哪些模型可供计算资源有限的人使用(有关可及性的更多讨论,请参阅 §5.6: 规模伦理)。为了鼓励更多的关于能源和碳影响情况的汇总,我们建议,除其他措施外:在会议上颁发绿色徽章,要求向会议组委会提供相关指标,游说基础模型大规模部署者提供更多透明度,以及普遍转变学术界和工业界对这些指标的标准报告的专业规范(参见 §5.6: 规模伦理 中关于专业规范的更多讨论和 Henderson et al. [2020] 对报告机制的更多讨论)
23 一些云计算提供商已朝着这一目标迈出了一小步从而可以确定碳友好的云区域。
例如:https://cloud.google.com/blog/topics/sustainability/pick-the-google-cloud-region-with-the-lowest-co2。
本期责任编辑:赵森栋
理解语言,认知社会
以中文技术,助民族复兴