赛尔译文|基础模型的风险与机遇(五)
原文:On the Opportunities and Risks of Foundation Models
链接:https://arxiv.org/pdf/2108.07258.pdf
译者:哈工大 SCIR 张伟男,朱庆福,聂润泽,牟虹霖,赵伟翔,高靖龙,孙一恒,王昊淳,车万翔(所有译者同等贡献)
转载须标注出处:哈工大 SCIR
编者按:近几年,预训练模型受到了学术界及工业界的广泛关注,对预训练语言模型的大量研究和应用也推动了自然语言处理新范式的产生和发展,进而影响到整个人工智能的研究和应用。近期,由斯坦福大学众多学者联合撰写的文章《On the Opportunities and Risks of Foundation Models》,将该模型定义为基础模型(Foundation Models),以明确定义其在人工智能发展过程中的作用和地位。文章介绍了基础模型的特性、能力、技术、应用以及社会影响等方面的内容,以此分析基于基础模型的人工智能研究和应用的发展现状及未来之路。鉴于该文章内容的前沿性、丰富性和权威性,我们(哈工大 SCIR 公众号)将其翻译为中文,希望有助于各位对基础模型感兴趣、并想了解其最新进展和未来发展的读者。因原文篇幅长达 200 余页,译文将采用连载的方式发表于哈工大 SCIR 公众号,敬请关注及提出宝贵的意见!

-
引言 -
能力 -
应用 -
技术 -
社会 -
结论
4.4 评价
4.技术
4.4 评价
Authors: Rishi Bommasani, Kawin Ethayarajh, Omar Khattab
评价为机器学习模型提供上下文信息:它可用作 (1) 追踪技术发展 — 我们如何衡量模型的性能以及如何设计改进的模型 (§4.1: 建模); (2) 理解 — 模型会表现出什么行为(§4.11: 可解释性)以及它们在不同的数据子集上的差异(§4.8: 对分布变化的鲁棒性);(3) 文档 — 我们如何有效地总结模型行为并将其传达给不同的相关人员。对于基础模型,评价的以上每一个目的都至关重要,但基础模型的性质引入了其他 AI 或 ML 设置中通常不会遇到的新挑战:
(1) 跟踪技术发展需要相对比较,但比较基础模型很复杂,因为基础模型必须适配(可能以不同的方式)后才能执行下游任务。
(2) 理解基础模型需要有关被评价的内容的特定先验知识(例如, 分类学),但基础模型获得的某些即时技能(例如, 上下文学习)在设计评价方式时难以提前得知。
(3) 文档需要明确的需求才能为决策提供有意义的信息,但基础模型可以适配用于无数应用场景,这使得撰写全面的文档十分有挑战性。
为了展开评价基础模型的讨论,我们区分了从基础模型的抽象中引出的两类评价:基础模型的内在评价,即考虑到任务不可知性,将模型与特定任务分离的评价,以及对特定任务模型的外在评价,其依赖于基础模型和适配机制。此外,我们认识到,由于基础模型的预期影响和范围,各种利益相关者(例如, 基础模型提供者和应用程序开发人员、审计员和政策制定者、从业者和研究人员)将需要评价基础模型和其在特定任务衍生品,这些评价将服务于不同的目的,并涉及利益相关者的不同需求。考虑到这一点,机器学习模型评价的标准范式并不完全适用于基础模型。因此,我们强调采用内在评价(§4.4.2: 内在评价),正视适配在外在评价中的重要性(§4.4.3: 评价与适配),以及评价设计(§4.4.4: 评价设计)是迈向更适合基础模型的评价框架的明确步骤。该讨论有助于围绕机器学习系统的评价的角色展开更广泛讨论 [Galliers and Spärck Jones 1993; Lipton and Steinhardt 2019; Ribeiro et al. 2020; Linzen 2020; Kiela et al. 2021; Milli et al. 2021; Jacobs and Wallach 2021; Bowman and Dahl 2021; Dehghani et al. 2021; Ma et al. 2021a, inter alia],同时,鉴于评价的复杂性,机器学习之外存在的测量和评价理论[Messick 1987; Jackman 2008; Loevinger 1957; Messick 1988; Hand 2010; Brewer and Crano 2014] 也可能对该讨论产生帮助。
4.4.2 内在评价
机器学习系统的评价传统上以任务为基础,通常被设想为对应用程序特别有用的功能(例如,翻译,对象识别)。相比之下,由于基础模型是必须进一步调整或专门用于执行有用任务的中间资产,因此必须改变标准评价范式以促进对基础模型的直接理解和比较。
一种方法是根据与训练目标相关的任务来评价基础模型。例如,像 GPT-3 这样的语言模型通过在给定先前上下文的情况下预测下一个单词来训练,可以根据它在保留的测试数据中给定单词的先前上下文分配单词的概率进行评价(i.e., 语言建模基准中的困惑度,如LAMBADA [Paperno et al. 2016])。到目前为止,这种方法在 NLP 中显示出前景,但我们发现它表现出的两个基本局限性。首先,依靠训练目标进行评价缺乏通用性:使用不兼容的目标训练的基础模型无法在一致的框架中进行比较或理解。其次,以这种方式评价依赖于有意义的代理关系,i.e., 训练目标方面的测量应该与其他更有意义和可理解的指标相关(例如,通过基础模型生成的内容的质量)。虽然在某些情况下这种代理关系已被证明是可靠的,但在评价基础模型更多样化的能力、以及它们在更多样化的环境或领域中的行为以及超出域内准确性的情况时,它可能会崩溃(我们在§4.4.8: evaluation-design中更广泛的讨论了该问题)。鉴于这些限制,我们预计需要综合考量两种方法互补带来的好处。
从广泛的外在评价中推算内在评价。评价基础模型的一种方法是使它们适配广泛的任务,并测量生成的特定于任务的模型的性能。由于基础模型是所有这些模型的共享基础,因此总体性能反映了该共享基础的性质和质量。目前,人工智能的许多子领域已经开始构建元基准,i.e. 一个独立的评价,整合了多个不同任务或领域的单一评价 [Wang et al. 2019b,a; Hu et al. 2020; Santurkar et al. 2020; Gehrmann et al. 2021; Hendrycks et al. 2021b; Koh et al. 2021; Tamkin et al. 2021a]。在这种范式被越来越多的人采用及其存在的既定优势的前提下,我们指出为什么它可能不足以完全满足基础模型的评价要求。元基准评价需要适配(最低限度地将基础模型专门化于元基准中的每个任务),考虑到所涉及的额外过程(例如,适配),这使得对基础模型本身的推理具有挑战性。具体来说,这使技术发展追踪问题变得复杂,无论是在跟踪方面(例如,性能归因于强大的基础模型还是精心设计的适配方式)还是在识别用于学习基础模型的中间过程的发展(例如, 通过比较两个基础模型在元基准上的性能,可能难以确定数据选择(§4.6: 数据)、训练目标(§4.2: 训练)和模型架构(§4.1: 建模)等方面的发展)。此外,这种评价范式使得特定于基础模型领域的属性和能力难以被理解或记录,这可能使这些信息难以传达给某些利益相关者(例如,SuperGLUE 性能可能无法为决策者提供足够的信息,或可能误导决策者) 或难以用他们预测模型在新任务或领域中的行为。
内在属性的直接评价。为了对元基准的使用进行补充,我们还对为什么脱离特定任务直接测量基础模型的属性(例如,特定能力或偏差)是有价值的进行了讨论。15 例如,我们可能会努力直接测量基础模型的语言能力,比如识别句法有效和无效的句子。为了强调这种方法的价值,我们回到评价的目的。值得注意的是,阐明能力、技能和偏见的存在和强度可以确定需要改进的具体领域(技术发展),阐明当前的潜力(理解),并有效地组织相关方面(文档)。这种方法也适用于可被广泛理解的评价,即技术专家、非技术专家(例如政策制定者或社会科学家)和一般民众都可以理解的评价。例如,描述这些模型的劝说能力或修辞能力可以特别直观的展示模型潜在的虚假信息和对知识的误用情况 (§5.2: 滥用) [Buchanan et al. 2021]。
15 严格来说,这些直接评价可能仍然涉及下游任务以及基础模型的任务专门化,但其目标更类似于探针任务(参见 §4.11: 可解释性)或者对尽可能直接测量基础模型的探索。
属性的直接评价也是处理基础模型的即时属性的重要途径;为了证明这一点,我们将上下文学习作为案例进行研究。值得注意的是,Brown et al. [2020] 不仅展示了 GPT-3 强大的上下文学习的标志性能力,而且是第一个专门将上下文学习作为适配模型和与模型交互的特定方式。传统的基于任务的外在评价没有提供明确的方法来识别上下文学习;在这种情况下,直接与基础模型交互似乎是必要的。更一般地,虽然通过对这些模型及其能力的非结构化或松散结构化的探索会认识到许多意料之外的现象,如上下文学习,但我们认为应该寻找新的评价方法来构建这种探索,或者更有雄心地提出可以进行更严格测试的新属性。内在评价也可能降低展示基础模型潜力的门槛;如果基础模型的新方法在内在评价中的被证明存在改进,即使它们没有使用非常适合的适配方法来在外在评价中证明能力,这些新方法也会被认为是非常有希望的。
应如何实施内在评价是一个重要的悬而未决的问题;这种评价的机制尚不清楚。我们列举了一些可能有助于为内在评价的设计和执行提供信息的一般原则和注意事项。
(1) 来自人类评价的灵感。我们认为评价基础模型时应该注重的许多相关属性、能力和偏差也是在评价人类相应能力时感兴趣的,这表明测量人类这些属性的方法可能对评价基础模型具有指导意义,甚至可以直接转化。例如,可以修改原用于评价人类语言能力的心理语言学指标来对基础模型语言能力进行评价 [Levy 2008; Frank et al. 2013; Linzen et al. 2016; Ettinger and Linzen 2016; Marvin and Linzen 2018; van Schijndel and Linzen 2018; Futrell et al. 2019; Prasad et al. 2019; Ettinger 2020],或者修改人类偏见 心理的测量指标以评价基础模型的社会偏见 [Greenwald et al. 1998; Caliskan et al. 2017;May et al. 2019; Guo and Caliskan 2021]。
(2) 人工参与的评价。对于为理解基础模型提供更具探索性的方法而言,人工参与评价至关重要,包括评价模型的生成或交互能力。尤其是,人类直接与基础模型的交互可以更好地识别它们的新兴能力和局限性,对基础模型的直接人工审查 [例如, Raji and Buolamwini 2019, §5.6: 规模伦理] 可以推进文档构建和模型透明度等研究目标。
(3) 内在度量的有效性。虽然内在测量允许在源头进行直接测量,即独立于适配和特定任务的基础模型属性的测量和评价,但这也对建立对评价的有效性的信任提出了挑战。
值得注意的是,外在评价结果在验证内在措施设计方面也可能很重要,例如,内在措施的预测有效性(i.e., 它们(统计)预测相关下游结果的能力)可能被证明是一个核心标准。
4.4.3 外在评价和适配
评价特定于任务的模型历来涉及报告模型在特定测试集上的性能(通常等价于模型在测试集上的准确性)。虽然这种范式部分程度上足以理解或记录模型,但它通常对使用不同(并且可能是不平等的)资源生成的特定于任务的模型进行不公平的比较,从而难以衡量取得了多少技术进展。在基础模型体系中,对不公平比较的担忧正在加剧:不同的基础模型(例如,BERT 和GPT-3)可能作为不同的任务特定模型的基础,而这些基础模型可能涉及大量不同的训练数据和计算。
考虑到达到特定性能水平所需的资源,Linzen [2020] 认为 (预) 训练资源应该在评价中得到确认和跟踪。我们相信这是一个有科学原则的提议;在不考虑培训资源的情况下比较不同的培训基础模型方法可能会产生误导。然而,鉴于创建基础模型的过程特别昂贵(例如,需要大量的人力和财务资本),并且除了科学因素外,通常还受社会因素(例如,商业激励)的支配,在实践中为基础模型提供的培训资源会有很大差异,这使得控制基础模型的不同因素以进行对比比较变得困难。在这里,我们考虑一种可能更普遍可行的替代方案,以补充Linzen [2020] 的提议。值得注意的是,我们考虑了为什么外在评价中应该承认适配资源,这是因为这一点对于确保外在评价能够识别最高效的适配方法(内在评价从根本上无法做到的一点)至关重要。我们提议注意这样一个事实,即适配资源通常被解释为用于适配模型的数据,但额外的资源[例如,用于选择适配方法的数据; Perez et al. 2021] 和约束(例如,适配基础模型所需的访问级别;§4.3: 适配和§5.6: 规模伦理进行了进一步的讨论)也应该考虑在内。
适配资源的计算。 计算为特定任务调整基础模型所花费的资源需要全面了解不同适配方法所需使用的资源或约束,例如,评价也必须随着适配中使用资源的发展而发展 (§4.3: 适配)。在现有的特定于任务的评价中,大多数评价指定了可用于(基础)模型适配任务的数据量。然而,Perez et al. [2021] 在这里确定了一个在过去工作中被忽视的关键点,即评价应该考量所有在适配过程中使用的数据,例如,不仅包含适配基础模型的数据也应包含用于选择适配方法的数据。此外,在基础模型制度中,不同适配方法的访问要求概念也是一个新的需考虑的因素,应该包含在评价中。具体来说,一些适配方法通常可能优于其他方法,但与其他方法相比,可能需要更大的访问权限或修改基础模型的能力(例如,微调需要基础模型梯度来修改基础模型,而提示可能只需要黑盒访问来指定输入)。
计量适配所涉及的资源可以补充从特定任务模型的评价中合理得出的各种结论。目前,特定任务的评价可能为特定任务的具体工作(i.e. 正在评价的确切模型)提供某些类型的清晰的理解或文档,但没有为不同的适配方法如何执行以及如何在给定的上下文中选择特定的适配方法提供明确的信息。相比之下,通过计量适配中涉及的资源和访问要求,评价可能更好地帮助研究人员发现哪些适配方法或程序能够最好地利用所提供的资源,i.e. 评价信息不仅对正在被评价的模型有效,也对产出该模型的通用流程有一定的参考价值。因此,拟议的评价协议明确致力于确定应使用哪些适配方法;我们注意到,所有这些结论都应始终针对给定的基础模型,因为这种形式的评价并不能提供足够的证据来证明某个适配方法在所有基础模型中都是最好的。16
16 根据当前结果能够得出相反的结论,我们建议不同的适配方法更适合不同类型的基础模型和训练目标 [Liu et al. 2021e; Lester et al. 2021]。
4.4.4 评价设计
理论上,评价的目标是衡量和表征用于各种不同目的(i.e. 技术进展、基础模型理解、基础模型文档)的理论指标 (例如,准确性, 稳健性 (§4.8: 对分布变化的鲁棒性), 公平性 (§5.1: 不平等和公平), 效率(§4.5: 系统), 环境影响(§5.3: 环境))。然而,在实践中,评价的效用将取决于评价的设计和执行方式。举例来说,对基础模型的文本生成质量(例如, 所生成文本的事实正确性)的自动测量可能无法很好地反映上述理论指标,相反,人工参与评价可能会更好地体现这些理论指标。
我们从评价机制开始考虑我们为基础模型及其改编的衍生品设想的评价设计。传统上,机器学习模型的评价涉及一个用于学习模型的大型训练集、一个用于设置超参数的可选验证集以及一个用于评价学习模型对保留数据的泛化能力的测试集[Bishop 2006]。因此,创建基准来评价模型历来需要大量数据,其中大部分用于训练,当数据稀缺或获得成本高昂时,这会使某些细微的诊断或评价的设计复杂化[Rogers 2020, 2021]。相比之下,因为基础模型的好处通常与适配的样本利用效率(i.e. 少样本或零样本能力)和应用场景的多样性相关,我们设想了一个评价方式,其中为不同单个任务提供的基准数据集要小得多(因此需要作为训练集的数据要少很多,i.e. 适配数据)并且更加多样化(在外部评价期间既可以捕捉内在评价关注的各种模型能力,也能够以生态有效的方式进行更有力的基本评价 [Bronfenbrenner1977; de Vries et al. 2020] )。这表明基础模型的性质可能会引发基准的性质(以及构建基准的心态)的转变,同时强调质量和多样性而非数量作为基准的关键优先事项。
在NLP 社区中已经开始出现这样具有广泛多样的基准的范式,例如BIG-Bench17 和FLEX [Bragg et al. 2021] ; 这种范式降低了基准设计的门槛,从而使社区能够更广泛地参与评价设计。18
除了评价机制外,评价结果的呈现和对结果的交互方式共同影响这些成果被如何用于决策。(例如,新的建模方法、模型选择、审计)排行榜已成为机器学习中事实上的范式,其中模型按特定且单一的标准(通常是准确性的一种形式)进行排名。随着时间的推移,这种方法通常会导致系统质量的显著且快速地进步 [例如,Wang et al. 2019a],但人们非常担心这能否产生更通用的进步[例如, Linzen 2020; Bowman and Dahl 2021].19 与所有机器学习模型一样,对基础模型及其衍生模型的要求很少是单一的;相反,我们期望其应用的广度和社会影响超出局限的准确性指标(例如,稳健性、公平性、效率和环境影响)。为此,我们认为基础模型的评价应报告这些不同方面的测量结果;现在越来越多地基准不仅仅反映准确性 (例如,稳健性 [Koh et al. 2021; Goel et al. 2021], 公平 [Nadeem et al. 2021; Nangia et al. 2020], 效率和环境影响 [Coleman et al. 2017])。此外,我们注意到,如果仍要以排行榜的形式报告这些不同类别的指标,则解耦潜在的各种因素纠缠(以诱导排名)将十分重要 [Ethayarajh and Jurafsky 2020]。特别的是,由于不同的利益相关者会有不同的偏好(例如,他们赋予不同属性的不同权重)和价值观 [Birhane et al. 2020],排行榜设计应该允许利益相关者以符合他们的价值观的方式操纵排名的方式;Ma et al. [2021a] 提出了一种早期的尝试,通过将用户指定的效用函数引入经济框架来比较模型的效用。
17 https://github.com/google/BIG-bench
18 传统上,ImageNet [Deng et al. 2009] 和 SQuAD [Rajpurkar et al. 2016] 等基准测试的设计是由资源丰富的研究实验室进行的,这些实验室有能力通过众包来支付创建这些数据集的费用 [Rogers 2020]
19 我们注意到与斯特拉森定律 [Strathern 1997](有时称为古德哈特定律 [Goodhart 1984])的联系:"当一个度量方式成为目标时,它就不再是一个好的度量方式。"
评价扮演着对所有机器学习范式(包括基础模型范式)至关重要的几个角色(例如,进步、理解、文档)。基础模型给现有的评价框架带来了新的挑战;设计直接针对基础模型制度的评价不仅可以更好地服务于多种评价目的,而且可以更好地服务于所涉及的无数利益相关者。
(1) 虽然机器学习评价传统上考虑了特定于任务的模型,但评价基础模型需要考虑到模型并非特定于任务。对基础模型的评价可能需要涉及整合两种互补的方法:(a) 从广泛地对特定任务的评价中估算基础模型的属性,以及 (b) 在基础模型中直接测量其属性。
(2) 现有的评价框架通常没有考虑到创建被评价模型所需的资源,从而导致不公平的比较。对于基础模型,我们讨论了一种评价范式,该范式强调考虑适配资源(例如,在适配中使用的所有数据及对基础模型的访问要求),这导致更有价值的评价,更好地描述适配过程运行的情况。
(3) 现有的评价设计通常在考虑的指标多样性方面受到限制,并且需要大量的适配数据集。对于基础模型,我们强调了越来越多的评价要求来满足更广泛的需求(例如,稳健性、公平性、效率、环境影响),以符合广泛的利益相关者价值观/偏好,并强调了通过重新分配评价所需的资源,适配模型过程中样例的使用效率将带来更多样化的评价。
4.5 系统
Authors: Deepak Narayanan, Trevor Gale, Keshav Santhanam, Omar Khattab, Tianyi Zhang, Matei Zaharia
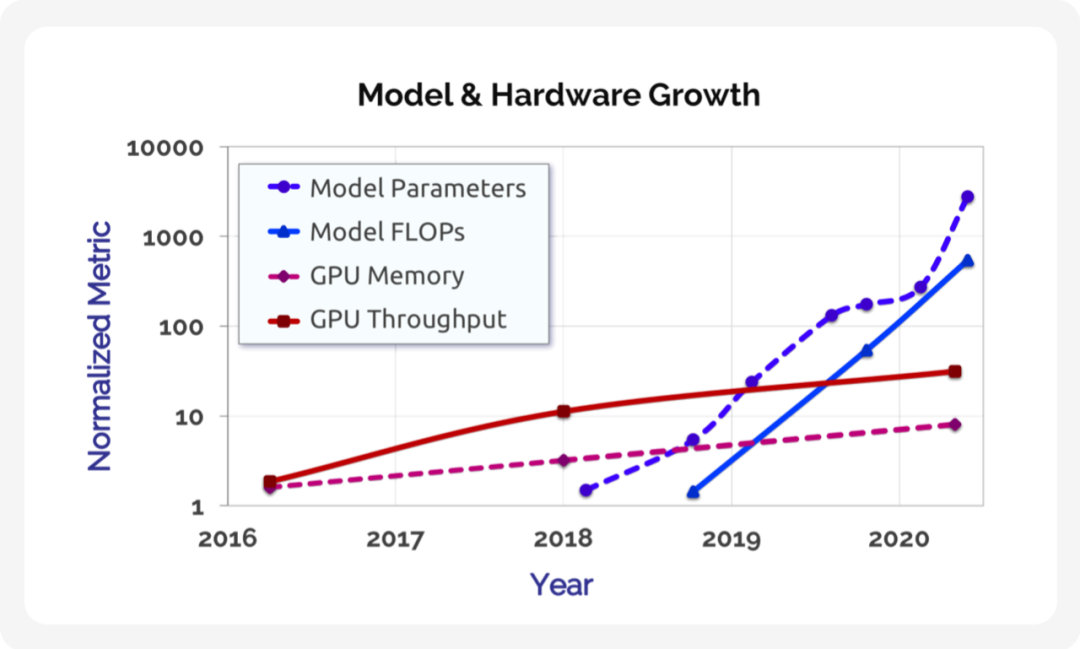 图1 该图显示了基于 Transformer 的语言模型(以蓝色显示)的参数和训练操作数 (FLOP) 的增长,以及NVIDIA P100、V100 和A100 GPU(以红色显示)的内存容量和峰值设备吞吐量随时间的增长。最先进的语言模型的增长速度(每条线的斜率)(每年大约 10 倍)远远超过硬件计算能力的增长速度(四年大约 10 倍),这激发了跨大量加速器的并行的需求,以及算法、模型、软件和硬件的协同设计的需求,以推动进一步的发展。参数和训练操作次数是从相关论文中获取的
[Brown et al. 2020]
,内存容量和峰值吞吐量是从 GPU 规格表中获取的。
图1 该图显示了基于 Transformer 的语言模型(以蓝色显示)的参数和训练操作数 (FLOP) 的增长,以及NVIDIA P100、V100 和A100 GPU(以红色显示)的内存容量和峰值设备吞吐量随时间的增长。最先进的语言模型的增长速度(每条线的斜率)(每年大约 10 倍)远远超过硬件计算能力的增长速度(四年大约 10 倍),这激发了跨大量加速器的并行的需求,以及算法、模型、软件和硬件的协同设计的需求,以推动进一步的发展。参数和训练操作次数是从相关论文中获取的
[Brown et al. 2020]
,内存容量和峰值吞吐量是从 GPU 规格表中获取的。
4.5.1 通过协同设计提高性能
今天,训练大规模基础模型需要定制的软件系统,如 Megatron 和 DeepSpeed [Shoeybi et al. 2019; Rasley et al. 2020],它们构建在 PyTorch 和 TensorFlow 等标准框架之上 [Paszke et al. 2019; Abadi et al. 2016]。这些软件系统依赖于许多堆栈中的创新来有效地大规模训练模型:新的并行化维度,例如管道并行性[Huang et al. 2019; Narayanan et al. 2019] 限制通信同时保持设备繁忙,状态分片优化器以减少内存使用 [Rajbhandari et al. 2020]、用于优化计算图的即时(JIT) 编译器[PyTorch 2021],以及优化的库,如 cuDNN 和NCCL [NVIDIA 2021]。Megatron 和 DeepSpeed 在特定范围内是有效的;例如,Megatron 能够提升现代硬件理论峰 值吞吐量的 52% ,可以在大约 3000 个 GPU 上训练一个万亿级参数规模的模型 [Narayanan et al. 2021b]。然而,扩展到具有更多 GPU 的更大模型仍然具有挑战性,因为现有的并行化策略在更大的GPU 数量下会崩溃。数据并行性受 batch 大小的限制 [Li et al. 2020e],管道并行性受模型中层数的限制 [Huang et al. 2019; Narayanan et al. 2019],张量模型并行性受单个服务器中 GPU 的数量限制 [Shoeybi et al. 2019].
虽然我们将继续通过新硬件实现性能提升,但大型模型的资源需求增长远远超过硬件性能的增长 [Brown et al. 2020]。为了促进模型容量的下一次重大飞跃并使模型性能的进步能够民用化,协同设计训练算法、模型、软件和硬件将变得越来越重要,事实上提高性能的许多途径改变了训练计算的含义。举例来说,以较低精度执行操作(例如 fp16)有助于提高现代硬件的吞吐量(例如,V100 和A100 GPU 具有用于较低精度矩阵乘法的专用张量核心单元),虽然这也会影响数值优化程序 [Micikevicius et al. 2017]。同样,利用权重稀疏性可以通过只对模型中的非零值进行数学运算显著降低训练和推理时间[Elsen et al. 2020; Gale et al. 2020], 但需要不同的训练算法[Jayakumar et al. 2021; Evci et al. 2020; Dettmers and Zettlemoyer 2019]。协同设计的其他示例包括更直接映射到硬件的模型架构[So et al. 2019; Child et al. 2019; Wang et al. 2020c; Lee-Thorp et al. 2021; Kitaev et al. 2020; Beltagy et al. 2020; Tay et al. 2020; Ren et al. 2021],高效的优化器 [Anil et al. 2020; Shazeer and Stern 2018],新颖的标记化替代方案 [Xue et al. 2021; Tay et al. 2021],专门构建的硬件训练平台 [Jouppi et al. 2017; Mudigere et al. 2021; Selene 2021],以及具有宽松权重更新机制的分布式并行化策略 [Narayanan et al. 2019, 2021a].
案例研究:高效的知识表示。作为成功的协同设计的具体案例,基于检索的模型如 REALM、RAG 和ColBERT-QA [Guu et al. 2020; Lewis et al. 2020b; Khattab et al. 2020] 采用与简单增加模型参数量不同的模型设计方法。基于检索的模型不是试图从越来越大的数据集中将隐式知识直接累加到具有数十亿个参数的 DNN 模型中,例如 GPT-3,而是在模型参数之外存储知识,例如文本段落的形式,或使用稠密向量表示捕获段落中的知识。然后,这些模型使用可扩展的 top- 搜索机制来提取与每个输入相关的知识,同时维持 DNN 模型本身较小的规模(§4.1.4: 存储性)。这种设计提高了模型在生产中的计算效率和可维护性:比如说,开发人员只需替换一段文本就可以更新模型的知识,而无需重新训练大型 DNN。
基于检索的模型利用多个前沿的跨功能思想取得了有希望的初步结果,包括在训练期间通过检索器反向传播损失[Guu et al. 2020](这需要利用包含数百万个段落的知识存储来对梯度进行近似)以及建模查询和段落之间的细粒度交互 [Khattab and Zaharia 2020; Khattab et al. 2020](需要将计算分解为向量级最近邻搜索操作)。这些技术允许基于检索的模型准确和高效的执行,但需要流行的ML 框架和最近邻索引(例如, FAISS [Johnson et al. 2019])不容易支持的功能。
4.5.2 自动优化
系统中的另一个重要挑战是跨算法、模型、软件和硬件的自动化优化。虽然许多优化和并行化策略是互补的,但确定最有效的优化组合具有挑战性,因为联合搜索空间以指数方式增长,并且不同的优化策略以复杂的方式相互作用 [Narayanan et al. 2021b]。基础模型提高了对自动化优化的需求,因为在数千个 GPU 的规模上进行手动实验既昂贵又耗时。
该领域的最新工作集中在以语义保留为目标的优化系统上。值得注意的是,已经提出具有自动挖掘数学等效图替换功能的系统 [Jia et al. 2019a; Wang et al. 2021c],以及通过高级API 和低级编译器促进算子图的分布式执行的系统 [Rasley et al. 2020; Mandeep Baines 2021; Bradbury et al. 2018; Shazeer et al. 2018; Lepikhin et al. 2020],还有自动选择混合分布策略的系统 [Jia et al. 2019b; Santhanam et al. 2021]。这些系统在工业界中帮助部署了许多基础模型 [Fedus et al. 2021; M2M-100 2020; Turing-NLG 2020]。
不幸的是,在组合语义改变优化(§4.5.1: 协同设计)的设置下,自动优化会变得更加困难,因为通常不清楚如何联合建模这些技术的统计学影响(例如,需要多少次训练迭代才能达到特定的精度?)。因此,我们将需要新的软件工具、库和编译器来自动识别针对目标综合指标的优化组合,例如time-to-accuracy [Coleman et al. 2017; Mattson et al. 2020]。构建这样的工具需要系统和机器学习专家之间的紧密合作。
4.5.3 执行和编码模型.
基础模型独特的多任务性质提供了在多个应用程序中分摊训练和推理成本的机会。特别是,诸如适配之类的范式意味着更多模型实例之间的共享。例如,两个从同一预训练模型微调的来的模型能够共享相同的模型主干,降低内存占用(分享的模型主干只需要存储一次),同时还可以跨任务的调整共享模型和进行批处理执行 [Shen et al. 2019; Narayanan et al. 2018]。因此,所使用的特定适配机制将与整个系统优化的过程产生信息交换(§4.3: 适配)。
关于应该使用什么编程接口来实现各种源自同一个预训练模型的适配模型(例如,模型和源自同一个预训练模型)或者两个各个组件共享参数的模型(例如,两个模型和共享相同的主干或层)仍是一个悬而未决的问题。Ludwig [Molino et al. 2019] 和 PyTorch 的 Module 提供了在模型中组合功能的简单方法,但目前没有系统支持跨模型依赖。让用户有机会提供声明将使训练和推理系统能够更有效地优化和编排计算;如果没有这样的声明,系统将无法了解可以跨模型实例共享哪些计算和参数。模型的“适配历史”(该特定模型适配自什么模型)也可用于调试:适配模型在特定类型输入上的错误可能源自其预训练模型,其反映预训练过程而非适配过程中的问题。像 PyTorch 这样的框架,以及用于训练基础模型的软件库,比如HuggingFace Transformers [Wolf et al. 2020],不允许指定整个模型实例的细粒度沿袭信息。
构建和维护由数千个加速器组成的集群也需要付出巨大的努力。新的训练范式,如Learning@Home [Ryabinin and Gusev 2020; Diskin et al. 2021] 探索利用互联网上的志愿者计算来协作训练基础模型。这种全新的执行模式可以降低任何一个实体的培训成本,但需要在许多不同领域开展协作,例如安全性(以确保恶意志愿者无法显著改变培训过程)、分布式系统(以处理容错以及志愿者数量减少的问题)和众包。
4.5.4 基础模型的生产
随着社区持续发展基础模型的各种功能,发挥基础模型的潜力将需要解决在生产中部署这些资源密集型模型带来的挑战。这些挑战包括执行具有严格延迟目标的模型推理,以及确保以自动化方式监控模型和数据。
对于具有严格成本和延迟约束的应用程序,模型压缩技术,如蒸馏 [Hinton et al. 2015; Li et al. 2020d; Sanh et al. 2019], 量化 [Polino et al. 2018; Gholami et al. 2021; Zhou et al. 2018], 剪枝 [LeCun et al. 1990; Gordon et al. 2020; McCarley et al. 2019; Wang et al. 2019c; Sajjad et al. 2020] 和稀疏化 [Gale et al. 2020; Elsen et al. 2020] 可以通过对大模型进行转换来帮助部署获得所需的推理时间属性。这些技术最初用于低内存环境(例如,如移动电话)中的较小模型(例如, BERT-L),但现在对于处理部署在数据中心的规模极端庞大的基础模型而言是十分必要的。传统上用于训练的并行化技术,如张量模型并行性 [Shoeybi et al. 2019],也可能有助于减少推理延迟,并且还能提供跨 GPU 的额外内存容量以适配模型的庞大参数规模。
除了这些实际限制之外,基础模型和用于训练它们的数据集的大小和复杂性的增加对模型和数据集生命周期的管理提出了新的挑战。由于具有大量参数的模型很难由人工手动检查,因此我们需要更先进的系统来进行自动数据集管理 (§4.6: 数据) 和模型质量保证。行为测试 [Ribeiro et al. 2020] 和模型断言 [Kang et al. 2020] 等技术通过为部署在终端应用中的模型提供单元测试,运行时监控(通过测试时断言的形式),以及持续模型改进(当新的输入进入时)等功能简化了模型在生产时的维护工作。这些工具可以帮助解决公平和偏见问题(§5.1: 不平等和公平),并减少模型错误预测。
4.6 数据
Authors: Laurel Orr, Simran Arora, Karan Goel, Avanika Narayan, Michael Zhang, Christopher Ré
基础模型标志着范式的转变,即越来越多的大规模数据被“喂”给这些模型从而提高其适配性能 [Devlin et al. 2019; Radford et al. 2021; Tolstikhin et al. 2021],其中总体的经验法则是“数据越多越好(the more data the better)”[Kaplan et al. 2020]。正如前面章节中所谈到的,这种对于数据整理的关注引起了围绕基础模型数据的生命周期的关注,其中包括:(1) 管理大规模的数据(§1: 引言),(2)跨新模态整合数据(§2.3: 机器人学, §3.1: 医疗保健和生 物医学),(3)在许可和治理条例的允许范围内进行推理——尤其考虑到在训练基础模型时使用了大量的爬取自互联网的数据(§3.1: 医疗保健和生物医学, §5.4: 合法性),以及(4)理解数据的质量(§4.4: 评价)。
虽然基础模型为上述的这些挑战引入了全新且困难的方面,我们可以发现这些问题与社区中的核心挑战存在相似之处,比如数据管理、数据分析以及工业的机器学习流水线。例如,数据管理长期以来一直研究可以用于数据分析、版本控制、数据溯源和数据集成的可扩展的声明式系统,来应对挑战(1)和(2)[Zaharia et al. 2012; Cudré-Mauroux et al. 2009;Stonebraker and Weisberg 2013; Stonebraker and Ilyas 2018; Hellerstein and Stonebraker 2005]。工业界借助流水线来应对挑战(3),从而管理各种各样的的数据许可并减少数据违规问题。目前还有一个完整的用于研究的生态系统,该系统可以解决挑战(4)来支持交互式的数据分析和可视化 [Hohman et al. 2020]。96尽管这些解决方案不一定能够直接应用于基础模型,我们相信更好的管理基础模型数据生命周期的方案应当从这些现有系统中汲取灵感。
96 VIS, CHI, SIGGRAPH 是一些研究交互式数据分析方法和系统的社区。诸如 Pandas,Matplotlib,Seaborn 这样的软件或库同样帮助用户交互式的探索数据。
在这一节中,我们强调对基础模型数据的生命周期进行管理。我们首先概述了其中的四大需求,包括:大规模数据管理、对于异构数据源的支持、数据管控以及数据质量监控。然后我们设想通过一个被称为数据中心的整体数据管理解决方案来满足这些需求。数据中心是一个简单的数据管理工具,它可以被私有和公共部门使用以支持对基础模型数据生命周期更好的交互式管理。
4.6.1 数据管理需求
目前在基础模型的开发的整个生命周期中,从数据整理、数据文档到模型监测、模型修补 [Gebru et al. 2018; Bandy and Vincent 2021; Bender and Friedman 2018] 都是临时的。数据管理社区的研究表明:定义明确的数据管理平台可以通过数据获取、数据版本控制、数据溯源、有效的分析和模型监控来促进机器学习模型的开发 [Hellerstein and Stonebraker 2005; Agrawal et al. 2019; Vartak et al. 2016; Ikeda and Widom 2010]。97受到数据管理社区的启发,我们考虑了在为基础模型构建整体数据管理平台时的核心需求。
97 像 Michelangelo 这样的典型的代码库同样支持端到端的机器学习模型构建https://eng.uber.com/michelangelo- machine- learning- platform/.
(1) 可扩展性 基础模型训练使用的数据规模越来越大 [Kaplan et al. 2020],例如悟道 2.0 模型在 4.9TB 的多模态数据上训练。98由于近期的大多数模型在面向公众的数据集上进行训练,预计数据规模还会继续上升。公开数据相比起每天收集并在工业基础模型管道中使用的 PB 级别商业和个人数据 [Marr 2017] 来说只占很小的一部分。因此,对于能够处理多模态基础模型数据集的高度可扩展技术的需求日益增长。
98 https://www.scmp.com/tech/tech- war/article/3135764/us- china- tech- war- beijing- funded- ai- researchers- surpass- google- and
(2) 数据集成 近期使用基础模型的工作表明:利用集成的结构化和非结构化数据有助于推广到稀有概念 [Orr et al. 2020] 并提高事实知识的召回 [Orr et al. 2020; Logeswaran et al. 2019; Zhang et al. 2019a; Peters et al. 2019; Poerner et al. 2020]。尽管取得了这些近期的成功,为基础模型集成数据集仍然是一个挑战。许多工作使用无结构的文本数据以及结构化的实体知识或图像数据 [Antol et al. 2015]。跨诸如:文本、视频、眼球轨迹 [Hollenstein et al. 2020]、机器人模拟 [Lynch and Sermanet 2021](见§2.3: 机器人学) 多个模态集成数据集的需求逐渐增长。我们需要一种工业规模的能够应用于多个模态和多个领域(如:政府、商业、科学)的数据集成方案。
(3) 隐私与治理 控制基础模型所使用的训练数据存在侵犯数据主体隐私的风险。主体的数据可能未经他们的同意 [Jo and Gebru 2020] 或超出了同意的范围而被披露、收集和使用。关于同意和使用的问题与基础模型尤其相关,因为我们无法总是预见使用基础模型的下游应用。就像在 §5.4: 合法性 中交代的那样,这些问题与基础模型训练中使用网络爬取数据的流行相混合。关于如何管理和保护网络爬取数据的法律问题仍然存在,99 在公共和私有部门使用网络数据的后果对于基础模型提供者来说仍是不明确的。我们需要工具来帮助基础模型提供者适配新兴的规定和指导方针,从而确保安全且负责任的数据管理。
99 最近,关于 Copilot 的 Codex 工具使用 GitHub 数据来帮助开发人员编码的争议,这些问题变得更加重要https://www.pwvconsultants.com/blog/questions- around- bias- legalities- in- githubs- copilot/
(4) 理解数据质量 数据质量会影响模型的表现 [Lee et al. 2021]。然而,能够系统且可扩展地理解训练数据及相关数据子集的方法或工具仍然是不成熟的。数据创建过程可能是十分混乱的,数据可能包含不同类型的偏差 [Blodgett et al. 2020; Bender et al. 2021](见§5.1: 公平性) 并且包含污染、错误或重复的信息 [Chang et al. 2020; Carlini and Terzis 2021; Buchanan et al. 2021; Lee et al. 2021]。数据也在不断地更新与完善 [Kiela et al. 2021],可能会包含涌现的实体 [Fetahu et al. 2015],发生分布变化 [Chen et al. 2021a] 和概念意义的转变 [Kenter et al. 2015; Lazaridou et al. 2021]。更进一步的,基础模型一旦被部署,可能会在关键且细粒度的数据亚群上表现出不良行为,基础模型提供者需要检测并缓解这种行为 [Goel et al. 2021; Hohman et al. 2018; Ré et al. 2019; Oakden-Rayner et al. 2019]。我们需要一个能够检测并有可能缓解不同类型的不良数据的工具包,从而以一种交互和迭代的方式提高模型的表现。该工具包还需要适配训练数据的动态性质。
4.6.2 数据中心解决方案
汲取数据管理、数据科学和数据分析的多年工作中的经验,我们设想了一个基础模型生命周期数据管理解决方案,我们称之为数据中心(datahub)。尽管目前已经存在一些专注于机器学习的数据中心100和更加传统的数据管理系统,101然而它们要么 1)没有将数据集成作为一级原语;要么 2)不原生支持包含模型预测在内的端到端生命周期;要么 3)不允许交互驱动的数据整理与数据改善(即基础模型提供者可以通过探索和更新可能的数据集主体来访问控制指南)。接下来,我们讨论数据中心如何解决§4.6.1: 数据管理需求中的四个数据管理需求。
100 一些公开的数据中心包括: https://data.world/, https://dataverse.harvard.edu/dataverse/harvard, https:// datacommons.org/, https://www.data.gov/, https://www.kaggle.com/, https://huggingface.co/datasets, https://www.ldc. upenn.edu/
101 一些用于基础模型的传统数据管理系统包括: https://aws.amazon.com/big-data/datalakes-and-analytics/, https: //eng.uber.com/michelangelo-machine-learning-platform/, https://kafka.apache.org/
数据规模 为了应对管理大规模数据的挑战,数据中心需要标准的数据管理解决方案 [Arm- brust et al. 2009],例如能够存储和维护随时间改变的大规模数据集的基础设施以及用于查询、选择和过滤数据集的可扩展接口。数据中心还应支持异构计算和云基础设施,从而可以在不同的环境中提供可扩展的解决方案。
数据集成 数据集成功能应当作为一等公民被数据中心包含。这将会需要先进的数据集成技术 [Stonebraker and Ilyas 2018; Abiteboul 1997; Dong et al. 2020; Rekatsinas et al. 2017a]102来允许跨模态和领域合并结构化与非结构化的知识。此外,这也意味着数据中心需要支持对异构的数据集和数据源的存储与查询。
访问控制 现在考虑数据中心的访问控制,数据中心需要支持多种文档(例如:数据集表 (dataset sheets)[Gebru et al. 2018] 或数据声明(data statements)[Bender and Friedman 2018]),从而允许数据管理者反映他们的操作,并使得数据集的预期用例、潜在偏差和局限性保持
透明。数据中心需要决定哪些文档对于数据上传是必须的(例如:数据来源和数据描述),哪些信息是被推荐的(例如:数据可以被用于哪些任务)。此外,随着数据集的变化,新的文档可能需要被上传 [Goel et al. 2021]。
数据来源通常与许可相关,数据中心需要为不同的数据源整合不同的法律问题和条件 [Masur 2018]。103此外,特定的数据集具有法律指南来保护数据主体的隐私。数据中心将会需要通过一定手段来确保数据集不会泄露个人身份信息(personally identifiable information, PII),104例如匿名或去标识化的数据不会泄露 PII,且需要数据主体同意对自身数据的散播。105
103 https://content.next.westlaw.com/4- 532- 4243
104 https://www.justice.gov/opcl/privacy- act- 1974
105 https://www.dhs.gov/sites/default/files/publications/privacy- policy- guidance- memorandum- 2008- 01.pdf
受数据集成的启发 [Rekatsinas et al. 2017b],数据中心应当支持有效的、安全的维护和对数据源的共享。特别是某些特定公共数据集(例如:互联网转储)的合法性尚未确定 (§5.4: 合法性),数据中心急需工具来识别违规行为并减轻任何违规行为带来的影响。由于某些违规行为很可能关系到模型的行为,我们需要系统支持对模型行为更好的理解,我们将在接下来进行讨论。
数据质量工具 借鉴数据分析与探索领域,随着用户选择、过滤和完善用于训练和适配的数据,数据中心将需要工具来快速地理解用户当前的数据集及其对模型行为的影响 [Hohman et al. 2020]。106此外,这些系统应当允许端到端的模型监控,通过近期的切片(亚群)发 现 [Chung et al. 2019]、相关子集上的模型验证 [Goel et al. 2021; Ribeiro et al. 2020]、数据评价 [Ghorbani and Zou 2019] 等方法来显示模型的性能。近期的工作同样提出了使用模型来检测哪些数据亚群对于给定输出贡献最大的方法,从而进一步帮助模型调试 [Keskar et al. 2019]。
106 以数据为中心的交互式工具的例子包括:https://www.tableau.com/ and https://www.paxata.com/.
一旦用户可以监测模型的表现——尤其是在那些稀少却至关重要的子群上,数据中心就应当通过纠正模型的错误来为用户维护模型提供方法和指引。尽管“模型修补 (model patching)”[Goel et al. 2020a] 仍然是一个开放问题,[Orr et al. 2020] 的工作首次描述了使用数据工程来维护一个生产式自监督系统,该系统通过修改数据而非模型来纠正不良行为。我们认为数据中心需要为用户提供接口,来为支持为模型维护的针对性的数据修改。
我们也认为数据整理和探索并不是独立进行的,并且数据中心应当支持一个围绕分享有用指标和分析流程的社区。受到像 Huggacing Face 的 ModelHub107和 Tableau Public 的visualization sharing platform108这样类似的社区分享平台的启发,我们希望用户分享其关于基础模型训练数据的见解。
107 https://huggingface.co/models
108 https://public.tableau.com/en- us/s/about
开放问题 尽管我们描述的数据中心受现有的工具和解决方案的启发,但我们不认为它们能够直接应对基础模型的挑战。特别是一些关于数据中心设计的开放问题:
我们应该如何支持数据版本控制,从而使数据集在更新的同时维护旧版本以支持可复现性 [Agrawal et al. 2019]?一旦模型被部署并确定了错误桶,数据集可能需要被更新从而包含更多的来自错误桶的样例。我们应当如何收集这些新的、有针对性的样例?
如§4.2: 训练中所描述的那样,我们认为越来越少的模型会从头开始训练,更多的模型将会使用微调的形式。我们如何在维持数据主体隐私的同时提供出处信息,从而了解原始数据的来源 [Chen et al. 2015a]?
在公共部门,数据中心可能会通过由数据管理者和基础模型提供者组成的个人开源社区的形式组织和运营。在这一背景下,诸如“谁负责数据的存储?”、“谁来支付计算产生的费用?”、“谁来为许可违规负责?”等问题的答案仍然是模糊不清的。数据中心如何提供正确的工具,使得一旦这些问题得到解决,后续工作就可以轻松推进?
应当对数据进行怎样程度的统计以获得适当的文档,同时避免开销过高或难度过大的问题?
数据中心如何支持诸如数据增强 [Ma 2019; Shorten and Khoshgoftaar 2019]、数据编程 [Ratner et al. 2017] 这样有针对的数据修改?
面对动态变化的评测数据,我们的检测工具如何更好的检测出基础模型的不佳表现,从而确定基础模型需要被更新?
我们有关数据中心的见解还不够完整或详细。然而,我们提出了对于数据挑战的初步想法,以及关于如何改进基础模型生命周期的数据管理的解决方案,从而鼓励其他人的思考。
4.7 安全与隐私
Authors: Florian Tramèr*, Rohith Kuditipudi*, Xuechen Li*
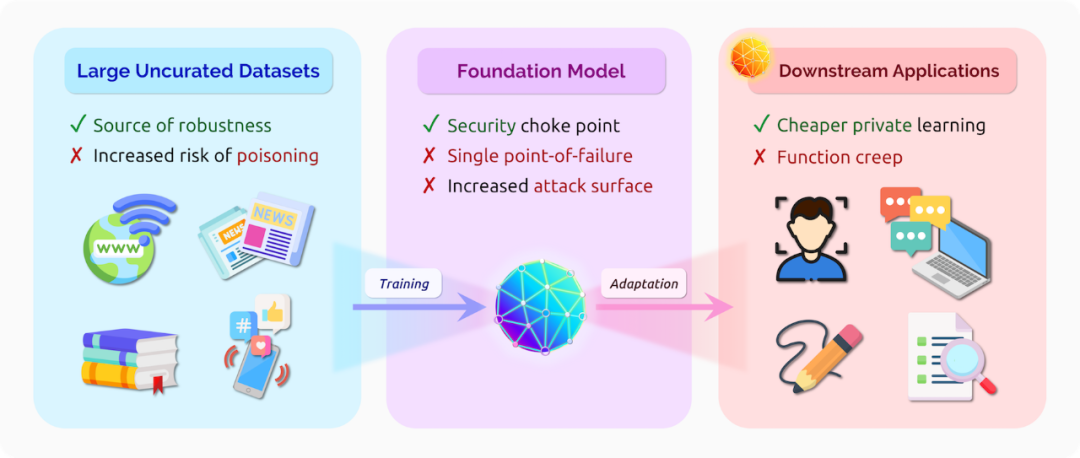
作为关键的数据驱动决策系统的核心组件,机器学习模型必须解决安全和隐私相关的各种威胁。109这些威胁可以通过传统的计算机安全中的“CIA三元组”表征。机器学习系统应当保护用户数据机密性,从而使其免受推理和重构攻击 [Fredrikson et al. 2015; Shokri et al. 2017; Carlini et al. 2019, 2021]。此外,训练得到模型的保密性可能受到模型窃取攻击的威胁 [Tramèr et al. 2016; Papernot et al. 2017]。机器学习系统的完整性可能会被对抗样本 [Biggio et al. 2013; Szegedy et al. 2014] 和数据投毒攻击 [Biggio et al. 2012; Chen et al. 2017] 危害。最后,资源耗尽攻击 [Shumailov et al. 2020; Hong et al. 2020] 可以威胁机器学习系统的可用性。
109 在这一节中,我们关注基础模型的安全性,而用于安全的基础模型 (例如:有害内容检测) 的一些应用在 §5.2: 滥用 中被讨论。
对于上述这些威胁,我们认为基础模型在未来机器学习系统中所扮演的安全角色将与操作系统在传统的软件系统中所扮演的角色一致。由于基础模型的一般性和普遍性,其可能会成为一个单点故障,并因此成为那些使用基础模型的应用的被攻击的主要目标。反过来,具有强大安全性和隐私属性的基础模型又可以成为设计各种安全、可靠机器学习应用的支柱。当然,这些应用可能需要通过额外设计来获得特定安全和隐私的保证(就像软件设计师不能仅仅依赖于操作系统来应对所有安全风险一样)。
4.7.1 风险
单点故障 一个基础模型被适配到多种应用意味着这些应用面临单点故障问题。例如,针对基础模型的数据投毒攻击:敌对者将恶意的样例插入基础模型的训练数据中,可能会影响该基础模型适配的所有应用。同样地,针对基础模型的对抗样例(即:导致模型输出特征发生较大变化的小输入扰动)可以很容易地转移到适配应用中。Wallace et al. [2019] 甚至发现:将单个对抗触发器添加到任意输入中都可以使得像 GPT-2 这样的语言模型输出预定义的文本片段。基础模型也可能成为数据隐私的单点故障。如果基础模型在公司的私有数据上预训练并记住了部分训练数据,那么所有的下游应用都面临着泄露这些数据的风险 [Carlini et al. 2021]。基础模型提供者可能也是应用数据隐私的单一信任点。例如,目前 GPT-3 的 API 要求将所有用于微调和推理的数据(可能是敏感的)上传到 OpenAI 的服务器。设计一种能够避免这种信任集中的基础模型服务是一个有趣的问题。
110 https://github.com/openai/CLIP/blob/main/model- card.md
本期责任编辑:赵森栋
理解语言,认知社会
以中文技术,助民族复兴