基于稀疏的超大规模预训练语言模型落地实践

分享嘉宾:谭传奇博士 达摩院 算法专家
出品平台:DataFunTalk
导读:2021年3月,阿里达摩院机器智能实验室AliceMind家族发布了最新训练的270亿参数规模的中文语言理解和生成统一模型--PLUG,但随着预训练模型规模越来越大,如何将大规模的预训练模型在下游任务上微调后直接部署成为了一个亟待解决的难题。因此,达摩院和计算平台PAI团队合作探索了基于稀疏的大规模语言模型落地方案,基于 PLUG 在各个任务上取得了超过同等规模小模型的结果,并在 BERT / Roberta / GPT 上也验证了其有效性。
本文主要包括以下几方面内容:
超大规模语言模型PLUG介绍
相关工作介绍
稀疏训练算法
实验&小结
总结&展望
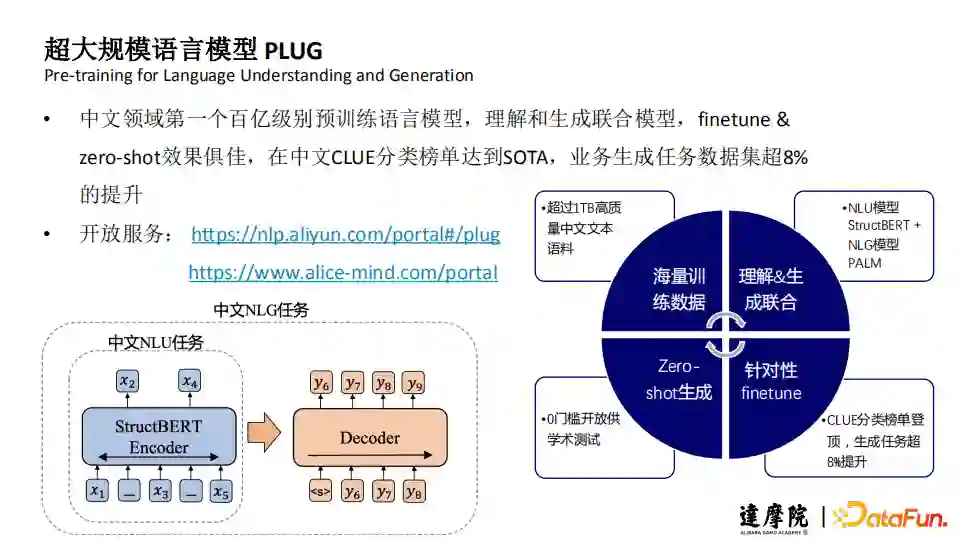
1. PLUG是什么?
PLUG(Pre-training for Language Understanding and Generation),中文领域第一个百亿级别预训练语言模型,理解和生成联合模型,finetune & zero-shot效果俱佳,在中文CLUE分类榜单达到SOTA,业务生成任务数据集超8%的提升。PLUG的开放服务有:
自然语言处理(NLP)平台:
https://nlp.aliyun.com/portal#/plug
AliceMind深度语言模型体系:
https://www.alice-mind.com/portal
2. 大规模语言模型落地面临的挑战
a. 大模型的部署主要面临两个方面的问题:
模型本身大小过大导致占用内存/显存过多;
模型规模过大导致了推理速度缓慢。
b. 解决思路:
基于大规模预训练模型在下游任务上进行推理的时候,实际上并不需要如 此大规模的参数,往往仅需其中的一小部分就可以达到和大规模模型一样的效果;
通过模型压缩算法,如剪枝、量化、低秩分解等,在(尽可能)保持模型效果的基础上,尽可能的减少模型规模。
3. 超大规模模型落地
超大模型落地基于以下两个方面:
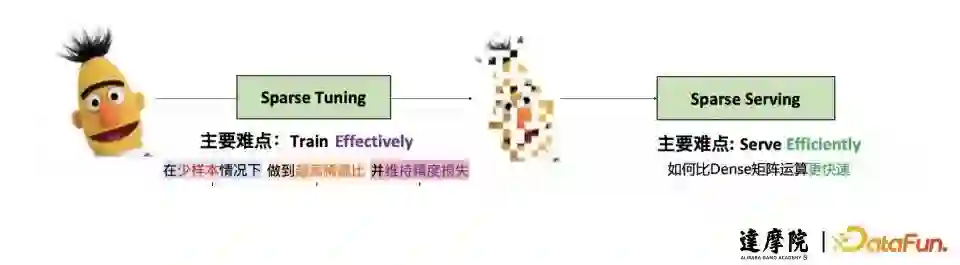
Sparse Tuning:如何在少量训练数据集的情况下,达到快速高效的超大模型的稀疏压缩,并维持最终准确率尽量跟原来直接Fine-tune一个超大模型效果相当;
Sparse Serving:如何打破基于Dense矩阵运算加速库的传统,建立一个新的稀疏模型的高效推理框架。
1. 模型压缩(Model Compression)
下图中列举了很多模型压缩的方式,包括:
参数共享(Weight Sharing)和知识蒸馏 (Knowledge Distillation),这两个方式压缩后的小模型在结构上与大模型基本一致,只是参数量和规模减小了;
低秩分解(Low-Rank Factorization)、模型剪枝(Pruning)和量化(Quantization)这三种方式压缩后的小模型结构会有所改变。
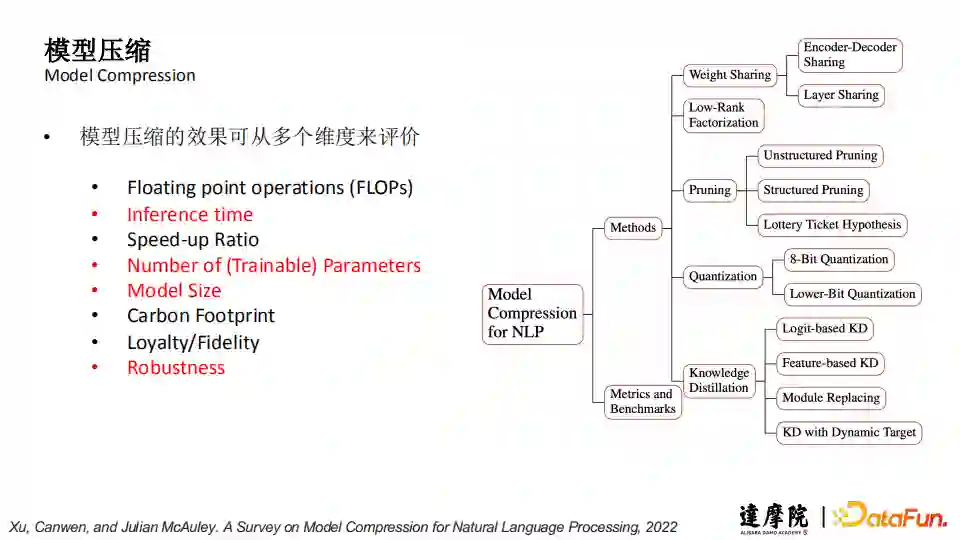
模型压缩的效果可从多个维度来评价:
Floatingpoint operations (FLOPs) 浮点运算数量:数量越少意味着模型在推理优化中所需的操作更少;
Inferencetime:做一条数据推理所需的时间;
Speed-upRatio:加速比;
Numberof (Trainable) Parameters:(可被训练的)参数量要确保尽可能少;
ModelSize:模型尽量小以方便操作;
CarbonFootprint:二氧化碳排放量;
Loyalty/Fidelity:大小模型在参数上的一致性;
Robustness:鲁棒性,在模型压缩的过程中模型效果的稳定性。
2. 模型量化(Model Quantization)
a. 量化方法
量化旨在通过减少模型权重中的位数(即精度),来压缩神经网络,常见做法是将模型从FP32量化为INT8,可将模型大小直接减少75%,推理速度提升可达3倍。

上图公式中,定点Q表示目标范围,浮点R表示原始数据范围,通过R的最大值/最小值,和Q的期望达到的最大值/最小值,可以计算出最小表示刻度S以及量化定点值Z,再利用这四个数,将量化的原始值和期望值对齐。上图右侧是一个量化方案展示。
b. 模型量化存在的问题:
量化方案虽然在Transformer中已经有初步的实现,但对于模型的训练过程以及模型整体的推理过程,需要做一些特定的操作,在操作过程中会存在一定的困难;
模型的量化一定会减少模型的精度。
3. 稀疏/剪枝(Model Pruning)
a. 稀疏/剪枝的常见方式
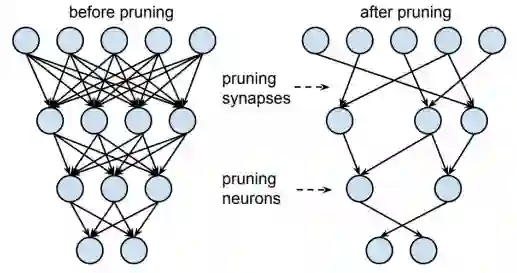
非结构化稀疏(unstructured pruning)
通过将相应的权重设置为0,移除神经网络中的“不重要”连接(见下图),如果一个点的连接线都被移除,则点也被移除;
结构化稀疏(structured pruning)
从模型中移除row、column、attention heads、layers,进而设置稀疏化算法,将参数加速比转化为时间加速比;
迭代稀疏
逐步达到设置的稀疏率(见下图),以免由于大规模的裁剪造成模型崩溃;
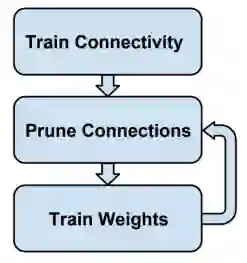
Han, Song, et al. Learning both weights and connections for efficient neural network. 2015
b. 示例:以非结构化稀疏为例
非结构化稀疏需要建模重要性得分函数,将得分“低”的部分裁剪,其中得分函数往往需要与模型同等(同级别)的参数量。

4. 彩票假设(Lottery Ticket Hypothesis)
彩票假设验证了稀疏方式的可行性。
彩票假设是指在密集的、随机初始化的神经网络里面,存在着那么一些子网络,在从头、独立训练时可以在相似的迭代次数内达到与原始网络相当的测试精度。
先训练一个网络,剪掉一部分,剩下的没剪掉的连接或者权重构成winning tickets,再按照这个初始化值训练子网络。

5. 少参数学习(Parameter-efficient Transfer Learning)
a. Adapters (Houlsby et al., 2019)
通过在Transformer层之间插入小模块( Adapters )来适配各下游任务。由于插入的Adapters会改变原始Transformer的计算形式,在下游应用上也要做同等的改变,同时也会产生很大的计算量;
b. Prefix Tuning (Li & Liang, 2021)
前置可训练的前缀向量或词、或后置模版来适配下游任务。这种方式也是会改变模型的结构,从而造成部署上的一些难度;
c. LoRA (Hu et al., 2021)
通过将可训练的低秩矩阵注入Transformer ,以使用少量参数近似权重更新。
这种方式不会改变原模型的结构,因此在部署上会相对简单,是以上三种方式中最为推荐的一种。

1. 背景
a. 模型稀疏
确定要从模型中删除的原子单元,即要执行稀疏的权重W(Attention Query Layer、Attention Output Layer、FFN Input Layer、FFN Output Layer);
重要性得分是做出修剪决策的标准,重要性函数S负责计算权重重要性,从而决定哪些权重应该被稀疏,最终得到与权重W同样大小的二分类矩阵M。
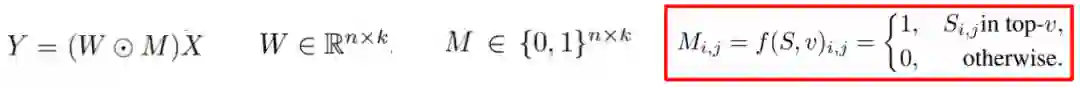
b. 迭代稀疏 (Zhu and Gupta, 2018)

2. 重要性得分函数
结合0-order (magnitude pruning) 和 1-order(movement pruning),提出新的重要性得分函数:

其中α是平衡0/1阶函数的超参数,0阶由于没有任何参数,因此是高效的。
如何让1阶也变得高效呢?
3. 低秩分解 - 重要性得分(Low Rank Impotantane Score)
使用低秩方式(Low Rank)首先要确保低秩:
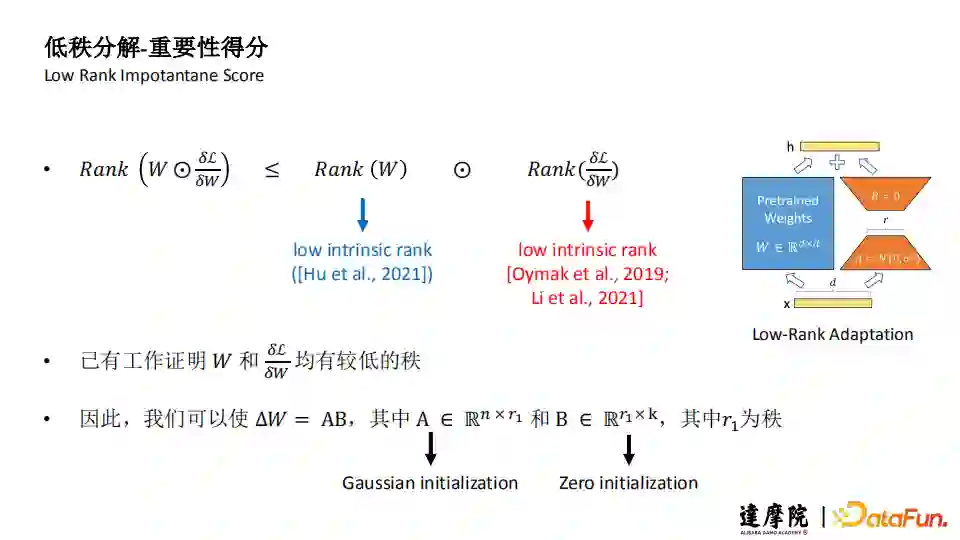
在初始化时将A做高斯初始化(Gaussian initialization),B做0初始化(Zero initialization)。
上图中蓝色部分,是预训练参数,可以不用训练,橙色的A和B是要训练的,训练后可以直接将参数加到W上,新模型与原模型结构一致,可以方便进行部署。
4. 结构化稀疏
相较于非结构化稀疏,结构化稀疏更适配底层硬件优化,实现真正的模型加速。
我们发现,稀疏矩阵存在明显的结构信息(见下图),很多rows所有的权重均被去除,很多columns所有的权重均被去除,因此,我们认为在row/columns上存在结构化的稀疏策略。


5. 模型优化

6. 稀疏+低秩分解+结构化

在上图的表格中可以看到,对比MaP和MvP的方式,MaP不需要训练参数和数据,因此效果会差一些,PST所需要的训练参数量只有MvP的1%-2%。
1. 数据集、模型、基线
a. 数据集
NLU:GLUE Benchmark
NLG:E2E, DART, WebNLG
b. 模型
NLU:BERT [Devlin et al., 2019], RoBERTa [Liu et al., 2019]
NLG:GPT-2 [Radford et al., 2019]
c. 基线算法
magnitude pruning (MaP)
movement pruning (MvP)
L0 regularization
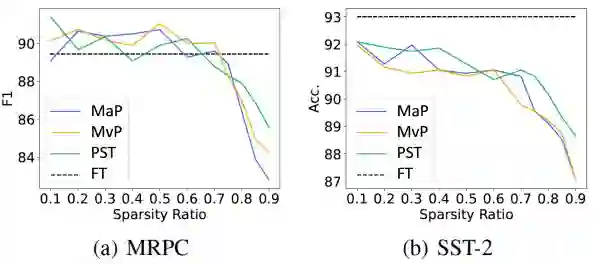
2. NLU实验结果
a. PST在减少约99%的训练参数的情况下,在50%和90%稀疏比上达到甚至超过了MaP、MvP、L0等基线算法的结果;

b. 随着稀疏率的增大,PST较MaP、MvP体现出越来越明显的优势。
3. NLG实验结果
a. 90%稀疏率:在三个数据集上均优于基线方法;
b. 在E2E、WebNLG上更是优于原始Fine-tuning方案;

4. 对比实验(重要性得分函数)
a. 我们调整r1和r2使得所有方案有同样的参数量;
b. 结果表明,我们的方案优于各种其他方案;
c. 结构化项( Structuredness )的作用大于低秩项(Low-rank)。

5. 对比实验(秩)
a. 当秩较小时(如r1或r2 = 4),提升对应项的秩(r2或r1)会带来结果提升;
b. 而当秩足够大时,(如r1或r2 = 16),对应项的秩的提升不一定带来结果提升,最优结果均为( r1 = 16, r2 = 8 );
c. 在下游任务上搜索 r1 或 r2 可进一步提升结果。

6. 分析实验(权重分布)
a. PST在weight和score上更平滑;
b. 同时表现出MaP和MvP的特点;
c. 结合了MaP和MvP 的优势。

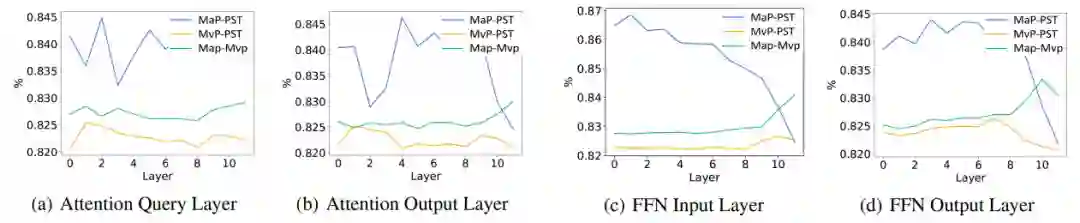
7. 分析实验(稀疏矩阵)
a. PST的稀疏矩阵更接近MaP;
b. 随着深度增加,PST与MaP的区别逐渐增大;
c. 随着深度增加,PST与MvP在Input层更相似,但在Output层更不同。
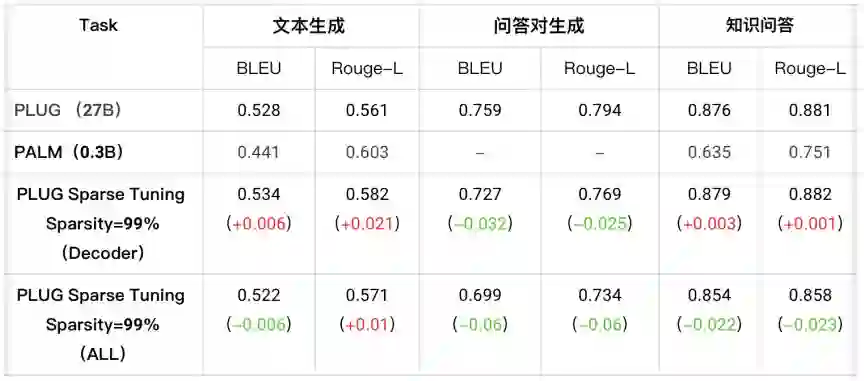
8. PLUG模型结果
a. 实验设置:CLUE Benchmark :CSL 、 OCNLI、 CMNLI ,Few-shot :2K或3K数据(每个类别1K标注数据);
实验结果:
在90%稀疏率时,三个数据集的平均精度损失仅在0.67;
在OCNLI数据集上,90%稀疏的PLUG模型的精度/效果提升了+0.27%(66.00 vs 65.73)。

b. 实验设置:三个业务数据集 (约1k条训练数据);Decoder参数稀疏率99% & Encoder + Decoder参数稀疏率99%;
实验结果:
多个数据集均达到精度无损甚至结果提升。
1. PST:Parameter-efficient Sparsity Training
针对超大规模语言模型,提出基于稀疏的解决方案;
PST算法结合结构化稀疏、非结构化稀疏、低秩分解等优势,在基本保证下游任务结果的基础上,实现90%甚至99%的模型稀疏,使大规模语言模型训练和测试落地成为可能。
2. Future Work
考虑训练速度,探索稳定的大比例稀疏算法;
不考虑训练速度,得到同等(小)规模的最优模型;
融合稀疏和其他模型(蒸馏、量化)压缩算法;
协同硬件加速算法,提升同等规模模型的Inference速度。
Q:剪枝、量化和低秩分解很难用到Fast Transformer或其它模型上,使用蒸馏会更简单可行吗?
A:是的。蒸馏的方式不改变原模型结构,可以快速使用无需适配。
Q:实际部署到业务的模型最大有多大?
A:模型的大小取决于任务的类型,在平台上通过稀疏的方案进行训练的模型最大可以部署270亿模型。
Q:模型压缩方案中哪种在工业界落地更广泛?
A:目前Distillation(蒸馏)落地更广泛,它是比较成熟的方案,可直接使用无需适配。在Distillation的基础上进行Pruning是我们在探索的项目。
Q:非结构化稀疏的模型如何导出应用?
A:这也就是为什么我们要用Low-Rank的方式,它的改变量是低秩的,在部署的时候提前加到W上,这个计算不需要在部署后的模型上再去做了,所以就不需要额外的空间做存储了。
Q:PST方案是否已经上线?
A:PST已经在AliceMind平台上线供大家使用了。
Q:大模型稀疏99%后带来哪些效果提升?
A:可以说稀疏后效果不会有太多下降,提升的话可能是一些初始化、误差等等,或者小模型更少的冗余对某些特定的任务反应比较好等。
Q:模型参数的稀疏率如何设定?
A:稀疏率要看项目的目标是什么,要看能够load起来的代码参数量有多少,如果一个单卡的机器可能就是亿级别的参数,结合原始的参数计算下稀疏的比例。比如原来的参数是10亿级别,最终要部署的是亿级别的,那大概的要做90%的稀疏。
Q:GPU在稀疏性计算上的性能是否比较差?
A:这需要和工程人员去配合。如果是完全非结构化的稀疏,它的加速比是无法达到参数的减少比例的,比如参数量减少10倍,其提升的速度不会有10倍,如果结构化好一些或稀疏算子实现的好一些的话,这个比例会更接近。GPU在稀疏性计算上已经有一些工作在实现了,比如A100已经支持一定程度上的稀疏了。
Q:结构化剪枝与非结构化剪枝哪个更有优势?
A:结构化剪枝从工程实现上会更容易,而非结构化剪枝在算法上的空间更大,因此,工程和算法需要更好的配合。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“预训练” 就可以获取《预训练语言模型专知资料合集》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~






