中小型研发团队架构实践之ZooKeeper

文末有 demo 下载
Apache ZooKeeper 由 Apache Hadoop 的子项目发展而来,于 2010 年 11 月正式成为了 Apache 的顶级项目。
ZooKeeper 是一个开放源代码的分布式协调服务。它具有高性能、高可用的特点,同时也具有严格的顺序访问控制能力(主要是写操作的严格顺序性)。基于对 ZAB 协议(ZooKeeper Atomic Broadcast,ZooKeeper 原子消息广播协议)的实现,它能够很好地保证分布式环境中数据的一致性。也正是基于这样的特性,使得 ZooKeeper 成为了解决分布式数据一致性问题的利器。
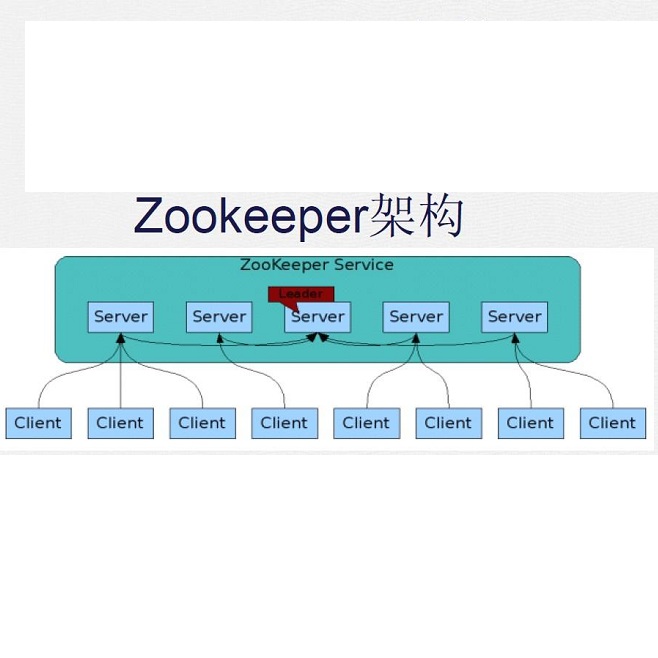
2.1、ZooKeeper 架构
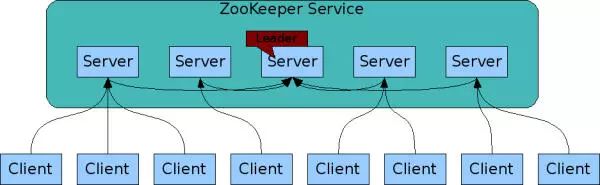
ZooKeeper 整体架构
ZooKeeper 由两部分组成:ZooKeeper 服务端和客户端。
ZooKeeper 服务器采用集群的形式。值得一提的是,只要集群中存在超过一半的、处于正常工作状态的服务器,那么整个集群就能够正常对外服务。组成 ZooKeeper 集群的每台服务器都会在内存中维护当前的 ZooKeeeper 服务状态,并且每台服务器之间都互相保持着通信。
客户端在连接 ZooKeeper 服务集群时,会按照一定的随机算法选择集群中的某台服务器,然后和它共同创建一个 TCP 连接,使客户端连上到那台服务器。而当那台服务器失效时,客户端自动会重新选择另一台服务器进行连接,从而保证服务的连续性。
当其中一个客户端修改数据时,ZooKeeper 会将修改同步到集群中所有的服务器上,从而使连接到集群中其它服务器上的客户端也能立即看到修改后的数据,很好地保证了分布式环境中数据的一致性。
2.2、ZooKeeper 数据模型
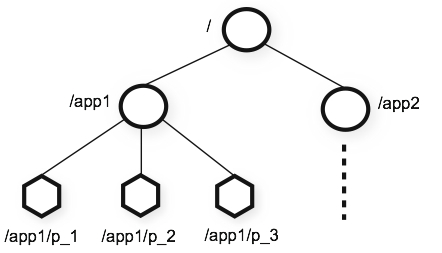
ZooKeeper 数据模型
ZooKeeper 的数据模型采用类似于文件系统的树结构。树上的每个节点称为 ZNode,而每个节点都可能有一个或者多个子节点。ZNode 的节点路径标识方式是由一系列使用斜杠"/"进行分割的路径表示。
可以向 ZNode 节点写入、修改、读取数据,也可以创建、删除 ZNode 节点或 ZNode 节点下的子节点。值得注意的是,ZooKeeper 的设计目标不是传统的数据库存储或者大数据对象存储,而是协同数据的存储,因此在实现时 ZNode 存储的数据大小不应超过 1MB。
另外,每一个节点都有个 ACL(Access Control List,访问控制列表),据此控制该节点的访问权限。
ZNode 数据节点是有生命周期的,其生命周期的长短取决于数据节点的节点类型。节点类型共有 4 种:持久节点(PERSISTENT)、持久顺序节点(PERSISTENT_SEQUENTIAL)、临时节点(EPHEMERAL)、临时顺序节点(EPHEMERAL_SEQUENTIAL)。
2.3、Watcher——ZNode 数据变化通知
ZooKeeper 的 Watcher 机制,概括为三个过程:客户端注册 Watcher 成为订阅者、服务端处理 Watcher 以及客户端回调 Watcher。
客户端在自己需要关注的位于 ZooKeeper 服务器里的 ZNode 节点上注册一个 Watcher 监听后,一旦这个 ZNode 节点发生变化,则在该节点上注册过 Watcher 监听的所有客户端会收到 ZNode 节点变化通知。在收到通知时,客户端通过回调 Watcher 做相应的处理,从而实现特定的功能。
通过对 ZooKeeper 中丰富的数据节点类型进行交叉使用,配合 Watcher 事件通知机制,可以非常方便地构建分布式应用中都会涉及的核心功能,如:数据发布 / 订阅(即配置中心)、负载均衡、命名服务、分布式协调 / 通知、集群管理、Master 选举、分布式锁和分布式队列等。
3.1、配置服务:ConfigServiceDemo
文末 Demo 中的【ConfigServiceDemo(配置服务 Demo)】适用于 ZooKeeper 的配置中心应用场景:
应用中用到的一些常用配置信息放到 ZooKeeper 的一系列 ZNode 节点上,供应用获取配置数据;同时,如果某应用在需要关注的配置项节点上注册了个 Watcher,则以后每次被关注的配置项有更新的时候,都会实时通知到该应用,从而达到获取最新配置信息的目的。
3.1.1、为公司解决什么问题?
减少我们的运维工作人员的工作量:当公司的应用程序以集群环境模式被部署的时候,若第 1 次部署应用程序或遇到需要配置新增 / 修改 / 删除的情况,我们的运维工作人员不得不为集群中的每台服务器进行一台一台地修改。而利用了 ZooKeeper 后,他们只需要修改一次,就能为集群中的所有服务器完成配置新增 / 修改 / 删除。
使任意客户端能够看到即时生效的被改后的配置数据:目前现状:由于运维工作人员需要为集群中的每台服务器进行一台一台地配置修改,而导致出现了配置延时问题,使得集群中的每台服务器的配置数据不一致。也就是说,客户端(如应用程序)可能会无法立即读取到最新的配置值,需要过段时间后才能读取到。当运维工作人员利用 ZooKeeper 修改配置数据后,新的配置数据会立即被同步到集群中的所有服务器,从而保证集群中的所有服务器的配置数据对于任意客户端而言每时每刻都是准确无误的(可选加 Watcher)。
3.1.2、ConfigService 管理
下图显示的是 ZooKeeper 配置服务页面。
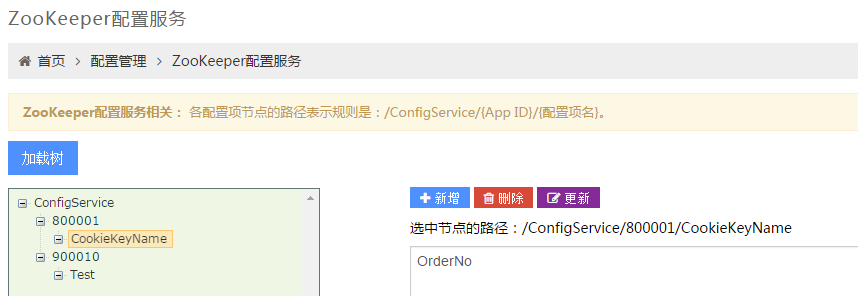
ZooKeeper 配置服务页面
3.2、Master 选举:MasterElectionDemo
3.2.1、为公司解决什么问题?
我们都知道,集群中的服务器一般只有 1 台是 Master 角色。一旦这台具有 Master 角色的服务器出现宕机情况,就出现了服务器单点问题。并且,我们并不知道这台具有 Master 角色的服务器是从什么时候开始处于宕机状态。
利用 ZooKeeper 的“对在 ZooKeeper 上创建的临时顺序节点(EPHEMERAL_SEQUENTIAL),一旦创建它的客户端与 ZooKeeper 服务集群之间的会话失效,那么该临时节点也就被自动清除”这一特性,再加上 Watcher 事件通知机制的使用,就能够解决这种服务器单点问题——一旦当前 Master 角色的服务器宕机了,它创建的临时顺序节点(EPHEMERAL_SEQUENTIAL)会马上消失;紧接着集群中注册过 Watcher 的所有服务器会马上收到当前 Master 服务器已宕机的通知,然后将重新进行 Master 选举。
ZooKeeperDemo 下载地址:
https://github.com/das2017/ZooKeeperDemo
ZooKeeper(v3.4.10) 官网:
http://zookeeper.apache.org/doc/r3.4.10/
ZooKeeper 客户端下载地址:
https://github.com/ewhauser/zookeeper
本系列文章涉及内容清单如下,其中有感兴趣的,欢迎关注:
缓存 Redis:Redis快速入门及应用
消息队列 RabbitMQ:如何用好消息队列RabbitMQ?
集中式日志 ELK:中小型研发团队架构实践之集中式日志ELK
任务调度 Job:中小型研发团队架构实践之任务调度Job
应用监控 Metrics:应用监控怎么做?
微服务框架 MSA:这是你心心念念的.NET栈的微服务架构实践
搜索利器 Solr
分布式协调器 ZooKeeper
小工具:
Dapper.NET/EmitMapper/AutoMapper/Autofac/NuGet
发布工具 Jenkins
总体架构设计:电商如何做企业总体架构?
单个项目架构设计
统一应用分层:如何规范公司所有应用分层?
调试工具 WinDbg
单点登录
企业支付网关
结篇
杨丽,拥有多年互联网应用系统研发经验,曾就职于古大集团,现任职中青易游的系统架构师,主要负责公司研发中心业务系统的架构设计以及新技术积累和培训。现阶段主要关注开源软件、软件架构、微服务以及大数据。
张辉清,10 多年的 IT 老兵,先后担任携程架构师、古大集团首席架构、中青易游 CTO 等职务,主导过两家公司的技术架构升级改造工作。现关注架构与工程效率,技术与业务的匹配与融合,技术价值与创新。