超越Spark,大数据集群计算的生产实践(内含福利)
↑ 点击上方蓝字关注我们,和小伙伴一起聊技术!
Spark拥有一个庞大的、不断增长的社区,还有在企业环境中不可或缺的生态系统。这些生态系统提供了不同生产环境案例所需的许多功能。一般来说,Spark应用做的是机器学习算法、日志聚合分析或者商务智能相关的运算,因为它在许多领域都有广泛的应用,包括商务智能、数据仓库、推荐系统、反欺诈等。
本文会介绍Spark核心社区开发的生态系统库,以及ML/MLlib及Spark Streaming的Spark库的具体用法,对于企业的各种用例及框架也进行了说明。
对任何业务来说,数据分析都是一个核心环节。对分析型的应用来说,数据仓库系统就是其核心系统。Spark有众多的框架和生态系统,所以它能作为核心组件为企业环境提供数据仓库功能,如图1所示。
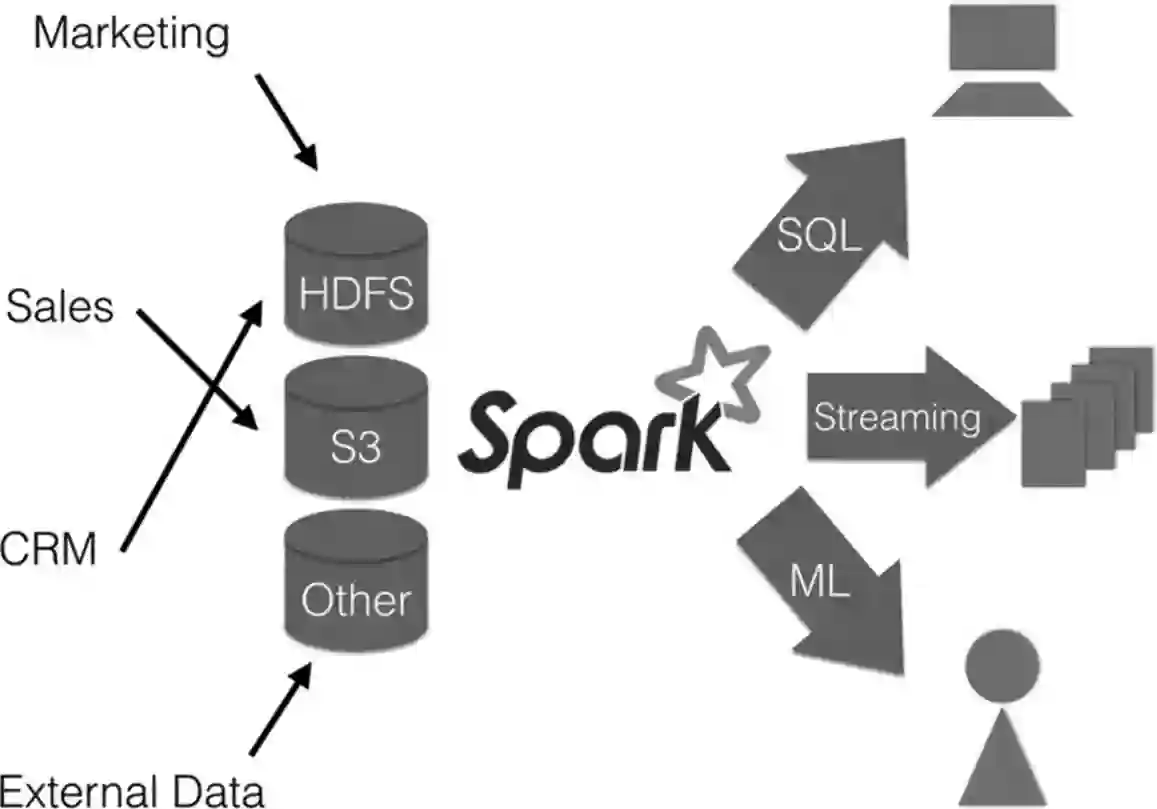
图1 Spark可以用作数据仓库核心组件
当然,与其他现有的工具相比,Spark提供的功能有较大不同。SQL是很多数据分析师、数据科学家和工程师使用的细粒度数据分析方法。Spark也可以用作数据仓库框架,支持SQL处理,名为SparkSQL。
Spark内核已经集成到其他分布式文件系统中,例如HDFS、S3。如果你的业务数据本来就保存在这样的系统中,很容易将现有业务流程转移到Spark环境,因为你只需要在数据存储系统上启动Spark集群即可。针对开发人员,Spark还提供了一个友好的API,可以用数据科学家们喜爱的Python和R来访问它。这个功能存在很长一段时间了。如果你习惯使用这些语言,那么选择Spark作为自己的数据仓库引擎还是很容易的。
你可以使用熟悉的接口在Spark上处理更大的数据集。SparkSQL特有的接口是DataFrame(数据帧),这是受R语言启发而引入的。建议使用这个接口来访问结构化数据。我们将在下一节详细介绍DataFrame。先来看一个纯SQL接口。Spark大致提供了三种类型的DW(数据仓库)功能:SparkSQL、DataFrame及Hive On Spark。如前所述,尽管DataFrame一开始是使用SparkSQL来开发的,但它与机器学习管道的关联度更高。我们将把它与ML / MLlib放到一起介绍。本节介绍SparkSQL和Hive on Spark,重点关注怎样配置集群。在尝试Spark的这些SQL功能之前,需要下载带Hive profile(配置)的预编译包,或者用Hive profile去构建这个包。如果你要自己创建,可以使用如下命令:
$ build/mvn -Pyarn -Phive -Phive-thriftserver \
-PHadoop-2.6.0 -DHadoop.version=2.6.0 \
-DskipTests clean package
一定要安装Zinc,它是一个长时运行的服务器程序,用于sbt的增量编译。如果你用的是OS X系统,可以用命令brew install zinc来安装它。
在运行这条命令后,可以得到一个带有Hive类的Spark二进制包。你或许会发现能用-P配置及-DHadoop.version环境变量轻松选择Hadoop版本。最好依据Hadoop集群及Hive功能选择你所需要的版本。换句话说,如果想在Hadoop 2.7.0上运行Hive 0.13,可以使用如下命令:
$ build/mvn -Pyarn -Phive -Phive-thriftserver \
-PHadoop-2.7.0 -DHadoop.version=2.7.0 \
-DskipTests clean package
Hive on Spark
Hive是用于管理分布式存储(例如HDFS)中的大型数据集的数据仓库软件。Hive一开始被开发来作为生成Hadoop MapReduce数据处理任务的简单接口。Hive有很长的历史,差不多跟Hadoop一样悠久。之后,一个更灵活、可靠的框架Tez被引入进来,它曾试图取代MapReduce框架。Apache Tez是一个比MapReduce更复杂的通用执行引擎。由于Tez旨在成为通用的执行引擎,如果正确地创建了执行计划,我们就能用它作为SQL执行引擎。从Hive 1.1开始,Hive也支持将Spark作为查询执行引擎。这意味着Hive目前支持三个执行引擎:Hadoop MapReduce、Tez和Spark。虽然Hive还没有全部完成,仍然在开发过程中(详情及进度可以查看Hive-7292),但是现在Hive能充分利用Spark的速度及可靠性。下面是在本地机器上使用Hive on Spark的步骤。
首先,需要启动Spark集群。请注意,你必须下载不包含Hive JAR包的Spark版本。为了从Spark二进制包中排除Hive JAR包,输入下面的命令:
$ ./make-distribution.sh --name Hadoop2-without-hive \
--tgz -Pyarn -PHadoop-2.6 \
-Pparquet-provided
用这个命令可以编译你自己的不含Hive JAR的Spark二进制包。但是在YARN上启动Spark集群最简单的方法是使用Spark目录下的ec2脚本:
$ ./ec2/spark-ec2 -key-pair=<your key pair name> \
-identity-file=<your key pair path> \
--region=us-east-1 --zone=us-east-1a \
-hadoop-major-version=yarn \
launch hive-on-spark-cluster
关于如何使用spark-ec2脚本,可参考Spark官方文档(https://Spark. apache.org/docs/latest/ec2-scripts.html)。这个脚本是为了在EC2实例上更容易地启动Spark集群而写的。要使用它的话,需要有AWS账户,以及从AWS控制台获得AWS密钥对。详情请阅读上述官方文档。
几分钟后,你就有一个运行在YARN上的Spark集群了。这个集群默认不含Hive。你需要在此Spark集群上安装Hive包。可以将Hive下载到Spark master服务器上,然后通过Hive CLI(命令行接口)来启动:
wget http://ftp.yz.yamagata-u.ac.jp/pub/network/apache/hive/hive-1.1.1/
apache-hive-1.1.1-bin.tar.gz
$ tar zxvf apache-hive-1.1.1-bin-tar.gz
$ cd apache-hive-1.1.1-bin.tar.gz
$ bin/hive
hive> set Spark.home=/location/to/SparkHome;
hive> set hive.execution.engine=Spark;
当你试着按照上述过程使用Hive on Spark的时候,可能会遇到麻烦。因为有一些情况下,当你自己启动Hadoop集群的时候,Hadoop和Hive的版本之间会发生冲突。所以,应该考虑使用CDH及HDP这样的发行版,它们包含Spark和Hive,而且所有组件之间的兼容性与功能都是经过测试的,这是最便捷的途径。但是这些系统还在不断发展,并且组件间会有比较复杂的依赖关系,因此有必要了解组件间的依赖关系。
在大数据领域的下一代数据处理技术中,机器学习扮演了重要角色。当收集大量的数据时,对系统性能会有显著影响。这意味着,收集大量的关于处理能力的数据,可以使一个机器学习模型更加出色。通过提供一种简单而通用的分布式框架,Hadoop及其生态系统实现了基本的环境(用大数据做机器学习)。Spark进一步推动了这种趋势。所以,在本章中我们要关注的是,对机器学习算法的使用和创建流程的一些具体工作。当然,对机器学习而言,Spark还有很多地方有待完善。但它的内存处理(on-memory processing)体系结构很适合解决机器学习问题。本节我们的下一个案例将重点看一看Spark中的ML(机器学习)。对开发者来说,机器学习本身需要一定的数学背景及复杂的理论知识,乍一看并不是那么容易。只有具备一些知识和先决条件,才能在Spark上高效地运行机器学习算法。
一些主要的机器学习概念包括:
DataFrame框架:它使创建及操作现实中的结构化数据更简单。这个框架提供了一个先进的接口,有了它,我们就不用关心每一种机器学习算法及其优化机制之间的差异。由于这种固定的数据模式(data schema),DataFrame能根据数据优化自己的工作负载。
MLlib和ML:集成到Spark内的核心机器学习框架。这些框架从本质上来说是Spark外部的框架,但是由于它们由Spark的核心提交者(committer)团队所维护,它们是完全兼容的,并且可以经由Spark内核无缝使用。
其他可用于Spark的外部机器学习框架:包括Mahout及Hivemall。它们都支持目前的Spark引擎。在一些MLlib及ML无法满足的情况下,可以选择这些外部库。
Spark社区提供了大量的框架和库。其规模及数量都还在不断增加。在本节中,我们将介绍不包含在Spark 核心源代码库的各种外部框架。Spark试图解决的问题涵盖的面很广,跨越了很多不同领域,使用这些框架能帮助降低初始开发成本,充分利用开发人员已有的知识。
Spark Package:要使用Spark库,你首先必须了解的东西是Spark package。它有点像Spark的包管理器。当你给Spark集群提交job时,你可以到存放Spark package的网站下载任何package。所有package都存放在这个站点。
XGBoost:XGBoost是一个专用于分布式框架的优化库。这个框架由DMLC(Distributed Machine Learning Community,分布式机器学习社区)开发。顾名思义,在DMLC项目下有许多机器学习库,它们在Hadoop和Spark等已有资源上具有高扩展性。XGBoost是基于Gradient Boosting(梯度提升)算法的。
spark-jobserver:提交job的流程需要改进,因为对于非工程师来说,这项工作有点难。你需要理解如何用命令行或者其他UNIX命令去提交Spark job。Spark项目现在是使用CLI来提交job的。spark-jobserver提供了一个RESTful API来管理提交到Spark集群的job。因此,这意味着可以在企业内部环境中将Spark作为一个服务启动。
你可能对使用Spark服务比较感兴趣。Spark已经提供了很多功能,例如SQL执行、流处理以及机器学习。Spark也有一个好用的界面,而且背后有强大的社区,开发者十分活跃,这也是人们对Spark寄予厚望的原因。下面我们将介绍一些当前正在进行中的Spark项目。
Spark目前使用的主要数据结构是RDD和DataFrame。RDD是一个原创的概念,而DataFrame是后来引入的。RDD相对灵活。你可以在RDD结构上运行许多类型的转换与计算。然而,因为它太灵活了,所以很难对其执行进行优化。另一方面,DataFrame有一定的固定结构,能利用它来优化DataFrame数据集上的执行。但是,它不具备RDD的优点,主要是没有RDD的灵活性。RDD与DataFrame的主要区别如表2所示。

表2 RDD与DataFrame的区别
与参数服务器集成
在介绍参数服务器的实现之前,有必要厘清分布式机器学习的相关概念,例如并行。参数服务器的目标与已有数据库是不同的,它们为大规模机器学习而开发。在大规模机器学习中有两种并行类型:数据并行(data parallelism)及模型并行(model parallelism)。
数据并行
数据并行侧重于把数据分发到集群不同的计算资源上。通常,用于机器学习的训练数据量非常庞大,仅仅单台节点机器在内存中是无法保存所有数据的,甚至在磁盘上也无法保存全部的数据。这是一种SIMD(单指令多数据流)处理类型。包括Spark MLlib及ML在内的大多数分布式机器学习框架都实现了数据并行。虽然数据并行很简单且易于实现,但是数据并行的收集任务(在前面的例子中,就是指计算平均值)会导致性能瓶颈,因为这个任务必须等待分布在集群中的其他并行任务完成后才能执行。
模型并行
模型并行与数据并行差别很大。不同的机器用相同的数据训练。然而,一个模型分布在多台机器上。深度学习的模型往往很大,因为许多参数常常不是在一台机器上的。模型并行就是将单个模型分为多个分片。一个节点维护一个模型分片。另一方面,每个训练进程能异步更新模型。框架必须对此进行管理以便于保持模型的一致性。实现这个过程的框架,特别是在机器学习领域,叫作“参数服务器”(parameter server)。深度学习尤其要求实现模型并行,因为深度学习需要用到更多数据,而这意味着最终需要更多参数。
参数服务器与Spark
如前所述,原始的参数服务器是为模型并行处理而开发出来的。Spark MLlib的大部分算法当前在处理数据时仅仅是数据并行,而不是模型并行。为了以一种通用的方式实现模型并行,人们研究和开发出更高效的参数服务器架构。参数服务器是在RAM(随机访问存储)上存放以及更新分布式集群中的模型的。而模型更新常常是分布式机器学习过程的瓶颈所在。SPARK-6932是一个用于研究参数服务器潜在能力的ticket,也是对各种实现的比较。此外,Spark项目在尝试基于这项研究去实现它自己的“参数服务器”。已经有人提供了Spark上的参数服务器,参见 https://github.com/chouqin/spark/tree/ps-on-Spark-1.3。
深度学习
深度学习因其高准确率及通用性,成为机器学习中最受关注的领域。这种算法在2011—2012年期间出现,并超过了很多竞争对手。最开始,深度学习在音频及图像识别方面取得了成功。此外,像机器翻译之类的自然语言处理或者画图也能使用深度学习算法来完成。深度学习是自1980年以来就开始被使用的一种神经网络。神经网络被看作能进行普适近似(universal approximation)的一种机器。换句话说,这种网络能模仿任何其他函数。深度学习可以看作是组合了许多神经网络的一种深度结构。
如前面提到的参数服务器,与其他已有的机器学习算法相比,深度学习需要大量参数及训练数据。这也是我们介绍能在Spark上运行的深度学习框架的原因。要想在企业环境中稳定地进行深度学习的训练,必须要有一个可靠而快速的分布式引擎。Spark被视为目前最适合运行深度学习算法的平台,是因为:
基于内存的处理架构对于使用机器学习的迭代计算,特别是深度学习,十分适合。
Spark的几个生态系统如MLlib及Tachyon对于开发深度学习模型很有用。
下面是一些Spark能用的深度学习框架。这些框架和深度学习一样,都是比较新的库。
H2O:H2O是用h2o.ai开发的具有可扩展性的机器学习框架,它不限于深度学习。H2O支持许多API(例如,R、Python、Scala和Java)。当然它是开源软件,所以要研究它的代码及算法也很容易。H2O框架支持所有常见的数据库及文件类型,可以轻松将模型导出为各种类型的存储。
deeplearning4j:deeplearning4j是由Skymind开发的,Skymind是一家致力于为企业进行商业化深度学习的公司。deeplearning4j框架是创建来在Hadoop及Spark上运行的。这个设计用于商业环境而不是许多深度学习框架及库目前所大量应用的研究领域。
SparkNet:这是本文介绍的最新的库。SparkNet由加州大学伯克利分校AMP实验室于2015年11月发布。而Spark最早就是由AMP实验室开发的。因此,说SparkNet 是“运行在Spark上的官方机器学习库”一点儿也不为过。此库提供了读取RDD的接口,以及兼容深度学习框架Caffe(http://caffe.berkeleyvision.org/)的接口。SparkNet通过采用随机梯度下降(Stochastic Gradient Descent)获得了简单的并行模式。SparkNet job能通过Spark-submit提交。
在最后,我们想聊一聊遇到的一些企业实际用例。虽然有些内容属于公司机密不便公开,但是我们想解释清楚Spark能做什么以及怎样才能充分利用Spark。以下都是我们公司的实际用例。
用Spark及Kafka收集用户活动日志
收集用户活动日志能帮助提高推荐的准确性以及将公司策略的效果以可视化形式呈现。Hadoop和Hive主要就用在这个领域。Hadoop是唯一能处理像活动日志这样的海量数据的平台。借助Hive接口,我们能交互式做一些分析。但是这个架构有三个缺点:
Hive做分析很耗时。
实时收集日志有难度。
需要对每个服务日志分别进行烦琐的分析。
为了解决这些问题,这家公司考虑引进Apache Kafka及Spark。Kafka是用于大数据传送的队列系统(见图3)。Kafka自己不处理或转换数据,它使大量的数据从一个数据中心可靠地传送到另一个数据中心成为可能。因此,它是构建大规模管道架构不可或缺的平台。
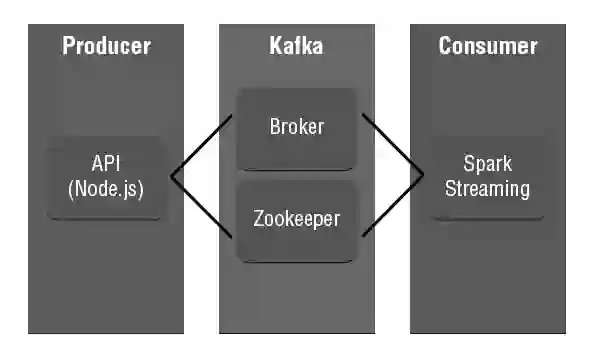
图3 Kafka和Spark Steaming的体系结构概览
Kafka有一个叫作主题(topic)的单元,带有偏移量及复制管理功能。通过topic及一组名为ConsumerGroup的读取器,我们就能获得不同类型的日志单元。为了做实时处理,我们采用Spark的流处理模块Spark Streaming。严格来说,Spark Streaming是一个微批量框架。微批量框架将流分为小数据集,对这些小集合运行批量处理进程。因此就处理算法而言,批处理跟微批量处理没有什么不同。这是我们采用Spark Streaming而不是Storm或者Samza之类的其他流式处理平台的一个主要原因。我们能方便地把当前的逻辑转换为Spark Streaming。由于引入了这个架构,我们能获得如下结果:
用Kafka管理数据的终结。Kafka自动删除过期的不需要的数据。我们无须处理这些事情。
使数据保存到存储(HBase)上的时间缩到最短。我们可以把这个时间从2小时缩短到10~20秒。
由于将一些过程转换为Spark Streaming,所以减少了可视化的时间。我们能使这个时间从2小时缩减到5秒。
Spark Streaming很好用,因为它的API基本与Spark相同。因此,熟悉Scala的用户会很习惯Spark Streaming,而且Spark Streaming也能非常容易地无缝用在Hadoop平台(YARN)上,不到1个小时就能创建一个做Spark Streaming 的集群。但需要注意的是,Spark Streaming与普通Spark job不一样,它会长期占用CPU及内存。为了在固定时间里可靠地完成数据处理,做一些调优是必要的。如果用Spark Streaming不能非常快地做流式处理(秒级以下的处理),我们推荐你考虑其他流式处理平台,比如Storm和Samza。
用Spark做实时推荐
机器学习需求最旺盛的领域就是推荐。你可以看到许多推荐案例,比如电子商务、广告、在线预约服务等。我们用Spark Streaming和GraphX做了一个售卖商品的推荐系统。GraphX是用于分布式图处理的库。这个库是在一个Spark项目下开发的。我们可以用一种称为弹性分布式属性图(resilient distributed property graph)的RDD来扩展原始RDD。GraphX提供了对这个图的基本操作,以及类似Pregel的API。
我们的推荐系统如下。首先从Twitter收集每个用户的推文(tweet)数据。接着,用Spark Streaming做接下来的微批量处理,每5秒收集一次推文并进行处理。由于推文是用自然语言写的(在本例中为日语),所以需要用形态分析(morphological analysis)把每个单词分离开。在第二阶段,我们用Kuromoji去做这个分离。为了与我们的商品数据库建立关系,需要为Kuromoji创建用户定义字典。这是获取有意义的推荐最重要的一点(见图4)。
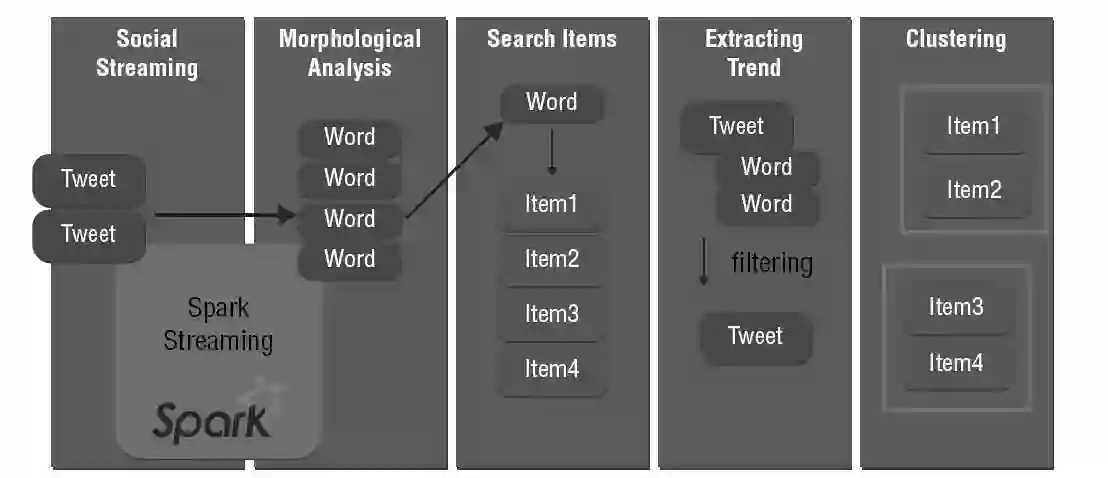
图4 Spark Streaming
在第三阶段,我们根据每个单词与商品的关系计算出一个分值。我们还必须调整用户定义字典,使单词与商品之间的相关性更好。特别地,我们删除了非字母字符,并且增加特别的相关词汇。在这个阶段之后,我们就获得一个从每条推文中收集到的词的集合。但是这个集合中还有与我们的商品不相关的词。因此在第四阶段,我们用SVM过滤出与商品相关的词语,以有监督学习方式(supervised learning)训练SVM:标签0表示不相关的推文;标签1表示相关的推文。创建了有监督学习的数据后,就开始训练模型。接着我们从原始数据提取出相关的推文。最后一步就是分析商品条目与单词的相关度。如果聚类成功,就能推荐相同聚类中的另一个商品给用户(见图5)。
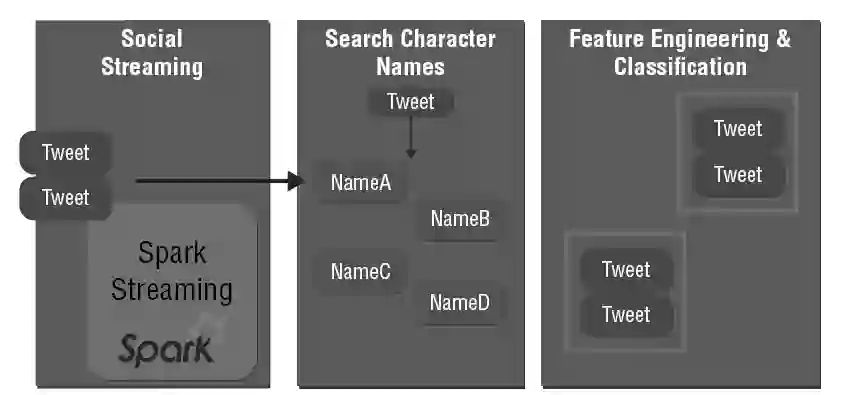
图5 Spark Steaming分析单词的相关性
虽然主要的麻烦之处在于创建用户定义字典,但是关于Spark Streaming也有一些地方需要注意:
Map#filterKeys和Map#mapValues不可序列化——在Scala 2.10中不能使用这些transformation。由于Spark 1.1依赖于Scala 2.10,所以我们不能用这些函数。这个问题在Scala 2.11中已经解决。
DStream的输出操作受限制——在目前的DStream.print、saveAsText Files、saveAasObjectFiles、saveAsHadoopFiles与foreachRDD中没有太多的输出操作。在其他方法中,什么操作都会有副作用。例如,println在map函数上就没有效果。这为调试带来了困难。
无法在StreamContext中创建新的RDD——DStream是RDD的连续序列。我们能轻松分离或者转换这个初始的RDD,但是在StreamContext中创建一个全新的RDD则很难。
在这个系统中,我们使用了Spark Streaming、GraphX及Spark MLlib。虽然也能用Solr作为搜索引擎,但是Spark库几乎提供了所有功能。这是Spark最强的特性之一,其他框架则达不到同样的效果。
Twitter Bots的实时分类
这可能是一种关于兴趣爱好的项目。我们已经分析了游戏角色的Twitter聊天机器人(Twitter Bot),并且可视化了Bot账户之间的关系。与前面例子类似,我们用Spark Streaming收集推文数据。游戏角色的名字可能有不同的拼写形式。因此我们用搜索引擎Solr转换推文中独特的名字。在这个例子中我们觉得Spark Streaming的主要优点是,它已经实现了机器学习算法(MLlib)及图算法(GraphX)。因此我们能立即分析推文,不用准备其他库或编写算法。但是我们缺少数据去显示有意义的可视化结果。除此之外,从每个推文内容中提取出有意义的特征也不容易。这可能是由于当前我们手动搜索Twitter账户,推文数据不足而导致的。具体来说,Spark Streaming是一个可扩展的系统,能处理海量数据集。我们认为应该利用好Spark的可扩展能力。
本文解释了Spark 核心社区开发的生态系统库,介绍了ML/MLlib及Spark Streaming的Spark 库的具体用法,对于企业的各种用例及框架也进行了介绍。希望对你的开发或日常的业务决策能有所帮助。Spark拥有灵活的架构,其社区也提供了大量生态系统框架,这一切使得Spark有广泛的应用场景。我们能从spark-packages上注册的包数量中看到Spark社区的活跃度。截至2017年2月3日,注册的包的数量已达到319个。
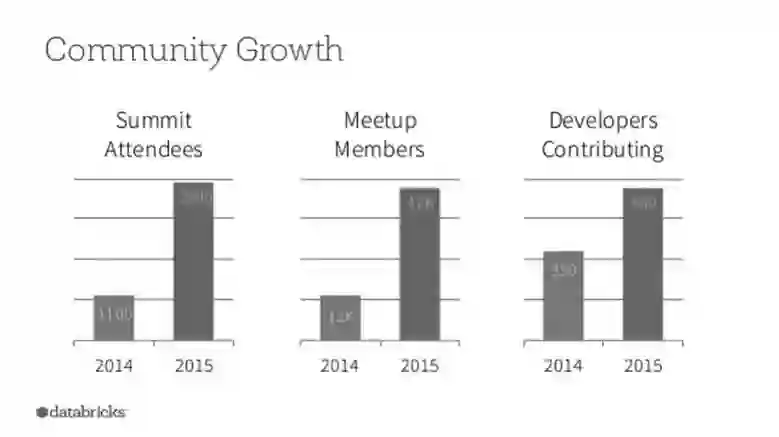
图6 发展中的Spark
Spark社区是一个欣欣向荣的开源社区,Spark社区在不远的未来肯定会发生变化。

本文节选并整理自《Spark:大数据集群计算的生产实践》一书,Ilya Ganelin(伊利亚·甘列林)等著,李刚译,周志湖审校。点击阅读原文了解图书详情。

福利来啦!感谢小伙伴们长期以来的关注和支持,特申请五本《Spark:大数据集群计算的生产实践》赠送大家。赠送规则:截止明天中午12:00(9月16日),在本文下留言你想获赠的原因,点赞排名前五名者即可获赠。