干货 | 双11总峰值超8亿OPS 阿里分布式NoSQL如何岿然不动稳如山?
双11已圆满落幕,但技术的探索,仍未止步。
“阿里巴巴数据库技术” 特此推出《赢战2018双11——阿里数据库 & 存储技术揭秘》系列干货文章,为你讲述2135亿这个超级数字背后的故事,敬请关注!
作者:阿里巴巴存储技术事业部高级开发工程师——昭桐
2018是双11的十周年,同时也是Tair的十周年。
Tair是阿里巴巴自研的高速分布式NoSQL数据库,专门设计用于洪峰抗量、数据库offload和超高速数据访问。作为高速存储类产品的一个集合,Tair主要包括四种存储引擎产品,以及fastdump服务、跨域数据服务和扩展的multi-model服务等。
今年双十一天猫交易额达到2135亿,交易创建笔数0点峰值达到49.1w。Tair在今年双十一中,表现依旧亮眼,没有一例业务问题。任它流量风吹雨打,Tair自岿然不动如山。
Tair集群(MDB&LDB&RDB)双11总峰值超8亿OPS,吸收了近两千万OPS的热点峰值流量。其中MDB峰值超5亿OPS;LDB峰值超2亿 OPS;RDB集群最高达6千万OPS,其中部分集群的水位,带磁盘数据读写的情况下达到单机100w OPS。成本方面,MDB在交易增长27%情况下,达成了零CPU Core增长的既定目标,LDB在成本优化上也达成预期。
在前沿技术方面,FPGA,NVM也在双11场景下得到了验证,为今后的大规模线上铺开提供了数据支撑。RDB 2.0新增ExHash、ExString、GIS、Bloomfilter等新数据结构以及分布式锁等,其中GIS在高德和菜鸟业务中得到大量使用,Bloomfilter也在集团内计算平台的首次得到大规模使用,表现稳定。
1、集团双十一
在集团内,Tair为3地多单元1中心的部署架构:
MDB:全单元部署,需要做到业务在单元内封闭,同时需要保证极低的业务访问Tair的RT,因此单元MDB我们每年都会跟随着应用一起进行单元建站。
LDB:LDB是具备单元间数据同步能力的持久化产品,业务选型LDB时,更注重的是持久化以及单元同步的能力,对RT的要求并不像MDB一样追求极致。一般只需要做到2ms以内就好了。LDB采用了三地部署,即每个地域一套LDB。根据业务的需求开通了实例级别的数据同步功能。
弹性LDB:弹性LDB是今年的架构升级,采用了新研发的hybrid storage引擎。由于网络部署架构的变化,今年上海云访问上海非云平均有1~2ms 的时延,对于强依赖 LDB 存储和进行数据计算的业务而言,Latency 翻倍就意味着更多的业务机器部署资源投入。因此我们对部分LDB集群进行了架构升级,使用了云上的计算资源提供了云单元LDB的能力。
RDB:RDB今年在优酷和导购链路有着广泛的应用,类似于LDB,同样采用了3地部署形态。
MDB on AEP & LDB on FPGA:作为前沿技术,在今年双十一中进行了小规模的验证。
① 成本优化
随着双11交易峰值的快速上涨,Tair的MDB及LDB的QPS峰值今年的增幅分别达到61.5%及85.4%。
在保障QPS快速增长但业务体验平稳的同时,在今年的成本优化方面:
常规ldb:在QPS增长了85%情况下,成本优化48%。
MDB:在交易笔增长56%背景下,MDB达成了零CORE增长的目标,成本优化56.3%。
② Tair 2.0 RDB
RDB作为Tair团队自主研发的新一代NoSql存储服务,不但支持string、set、zset、hash、list等复杂类型数据结构(兼容Redis4.x api),还新增了多种模型的数据结构,Bloomfilter& Cuckoofilter(更面向海量统计场景的滤波器),ExString(带有Version的String),ExHash(带有子key超时的Hash),ExGis(基于RTree的地理位置存储和复杂查询)等。方便业务在开发中以更少的代码实现业务逻辑。
RDB不止是一个存储引擎,它提供一整套存储解决方案,特别适合于有高QPS、低延时、复杂数据类型、数据容量不是特别大需求的应用接入。RDB后端提供一整套运维体系和高可用方案,包括同城容灾、跨域多活、无感知扩缩容、平滑迁移、无缝升级等特性,为业务的可靠性保驾护航。
RDB自2017年2月上线以来,目前已经有1K+的应用接入RDB,涵盖淘系、菜鸟、优酷、高德、友盟、阿里妈妈、AE、大麦等各个BU。
今年RDB在优酷、猫晚直播、菜鸟、手淘双十一互动,消息、agoo推送服务等场景下表现优异,总集群最高达六千万OPS:
优酷(优酷登录session): 双11晚会开场达到峰值300W+ OPS,在贯穿晚会全场及各个抽奖环节中,始终保持了在极高的稳定性。在多次游戏互动、抽奖中,仍旧保持了平稳的rt输出,引擎响应时间保持在0.3-0.5ms左右。
猫晚直播: 双11期间,最高OPS达500w+
菜鸟:今年的包裹量达到了惊人的10亿+,需要非常巨大的算法计算、物流规划。双十一虽然已经结束,但是菜鸟的高峰才刚刚开始,最近几天菜鸟相关的应用最高已经达到达500w+ OPS(之前模拟计算摸高到900w+ OPS),并将会持续很多天 。
手淘:消息总OPS达200w+。
推送服务:agoo是集团内广泛使用的无线消息推送平台, agoo使用RDB做消息PUSH频控,控制发送给单个用户的发送量&重复内容,使用hash结构,在双十一期间OPS达到300w+。
2、国际化
Lazada六国今年首次参加双十一大促,Tair作为lazada业务的强依赖链路缓存,完美地承载了千万级别的业务访问量。其中mdb承载了2700w+的QPS,ldb承载了10w+的QPS。虽然大促实际请求量超出之前提交的预算需求,Tair依然凭借强悍的高性能,协助业务扛过零点高峰。虽是第一次亮相双11,但Tair海外集群表现非常符合我们的预期。
AE今年大促持续2天时间,共有4国环境同时在同一时间点参加大促。由于前期全链路压测充分,资源准备到位。其中mdb峰值达到了1600w QPS,ldb峰值达到了230wQPS。
作为集团最能抗的系统之一,我们今年在以下方面进行了优化升级:
1、引擎架构升级-MDB并行引擎
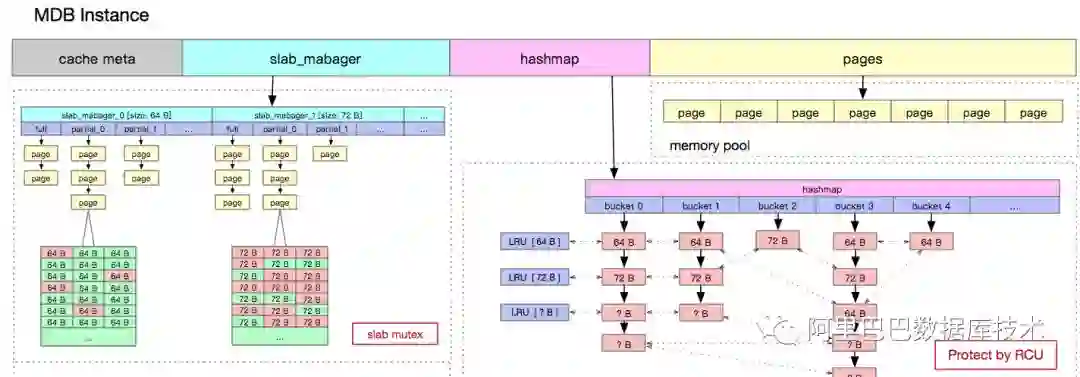
MDB本质上就是个分布式的hashmap,这个hashmap的每个切片存储了一部分的数据。理论上通过增加切片的数量可以增加整体的访问并发度,但是切片的数量也不能无限制的增加,原因:
① 切片过多会导致管理元数据过多
② 切片过多会造成每个切片可以使用的内存相应减少和切片间的内存碎片增多,一旦业务数据有倾斜容易发生淘汰
③ 切片解决不了热点访问的问题
所以在控制合理数据切片数量的情况下,增加每个切片的并发访问能力,就成了提升MDB性能的一个途径。提高一个临界资源(切片)的终极办法就是把它优化为无锁的。这里我们采用RCU(Read-Copy Update),后台异步GC和ThreadLocal的方案实现切片的并发访问,切片的并发访问能力同时也解决了热点key访问的问题。
2、管控升级-MDB集群资源调度
不同的业务在不同的场景需求下,对于QPS能力和存储容量的诉求不同。像菜鸟驿站、会员、商品以及库存,希望尽可能的将线上所有数据都进行缓存,从而提高缓存命中率,降低后端及DB压力,这种模型下,QPS/容量的占比是比较小的。而对于优惠及其他链路,优惠信息不会像商品/会员那样庞大,但对于QPS的需求是极高的。
因此在这两个场景下,诞生出两种截然不同的诉求,即,CPU计算型、内存容量型。同时今年线上全部采用了大规格机型而非以往的标准物理机,给线上运维上带来了很大的调度空间,往年,我们解决QPS和容量瓶颈只有一个办法,就是横向扩容机器。今年我们首先将集群按照业务模型进行了抽象,分为了计算型,通用型,存储型,再对资源进行了抽象,通过调度上充分利用宿主机的资源,最终达到成本最优的目的。
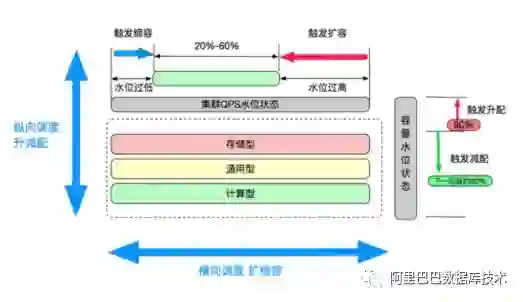
目前,Tair集群大部分已实现了小容器的docker化,配合智能调度功能,可以有效减轻运维的工作,并提升资源的使用效率,优化成本。
3、架构升级-LDB性能优化
① 容器化增强资源利用率
去年Tair LDB大部分机器都是物理机或者单容器,今年LDB实现了全容器化。容器化既带来了部署上的灵活方便外,还进一步提升了LDB的单机性能,这是一个额外收获。
今年LDB容器化方式经过综合考虑,我们选择的是单物理机上两个容器,即一虚二。
容器化后的性能提升方面:LDB是持久化型存储,不能丢数据,因此数据都要先写WAL(Write-ahead LOG),读写性能和RT会受到写SSD响应时间较大影响。在物理机或单容器运行时,LDB机器的CPU和内存还有不少富余,SSD的带宽也还可以进一步充分利用。且SSD的并发性其实较高,多个实例没有完全在同一时间写SSD的话,配置更多实例可以提升单机总的性能。
在一台机器上部署两个容器后,单个Tair进程的CPU、内存、实例(磁盘使用)更加均衡,由于单容器总的数据量减半,因此compaction带来的写放大也变少了,可以承受更高的QPS。容器化后,在不需要Tair软件适配的情况下,通过容器化的配置,性能达到30%的提升。
②软件性能层面的优化
今年提升Tair LDB能力的第二个手段是去除RT中的毛刺。为什么毛刺问题对集群性能影响这么大? 举个例子,假设同样是20W的QPS,一个的超时率是千分之一,另一个的超时率是万分之一,则为了保持Tair客户总体的错误率,前者需要降低单机承受的总QPS量,以达到万分之一的超时率,因此不得不委屈QPS,设置一个稳妥的单机目标QPS值,以保证一个稳定的RT。反过来,如果我们能够降低RT毛刺,则可以保持一个较高的单机QPS值,不必扩容去降低单机流量来稳定RT。
在软件优化层面,我们采用了去掉锁争用、优化读写路径、增强compaction能力。
——去掉锁争用
第一个优化是去除锁争用过多的LDB内嵌MDB缓存。之前LDB的实现为了提升读性能,在LDB中结合了一个MDB来对持久化存储的频繁读取的数据做一个缓存。方向很好,但在运维上内嵌的MDB需要较多容量鉴权等方面的配置,运维上的麻烦导致实际上内嵌的MDB一直并没有充分利用。
通过trace来分析,内嵌MDB却带来了较高的锁方面的性能开销(LDB里内嵌的MDB是还没进行RCU并行优化前的版本),RT的抖动一大半是这个锁带来的。由于MDB配额过少,并没有充分发挥缓存的作用。在关闭内嵌的MDB后,在QPS没有变化的情况下,去除了缓存的锁开销,RT的毛刺有了明显的降低。
——优化读写路径
第二个优化是通过Tair内建trace功能观测到在数据的读写路径上,memtable(数据在批量顺序写入磁盘前的内存缓存)的使用是用ref做的引用计数,最后一个使用者去删除不再需要的memtable,而memtable由于几十M以上,删除比较耗费时间,经测试,这里带来毛刺时能达到十几毫秒以上。
假设恰好最后一个使用memtable的调用者属于读写路径,则会给读写路径带来较高的RT延迟,这也会降低该IO线程的QPS处理能力。为此我们做了一个优化,让不属于读写路径上的调用者(也就是异步的compaction),在处理完后多等待一小段时间,例如几毫秒,再做unref,也就是尽量将最后一个unref和memtable的清理工作交给非读写路径上的异步任务去做。
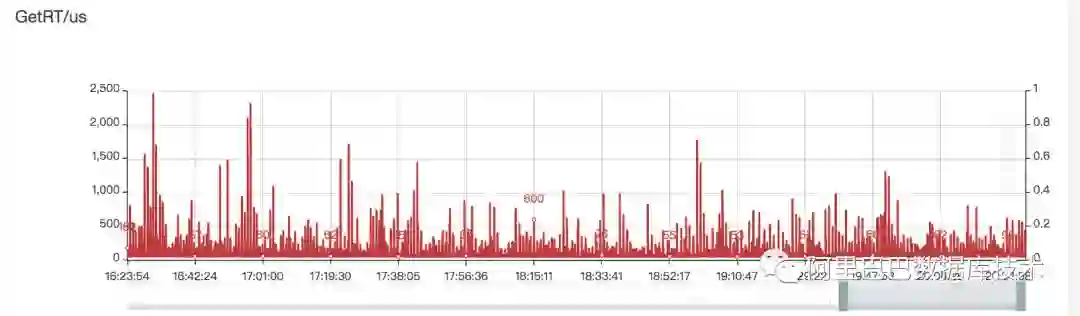
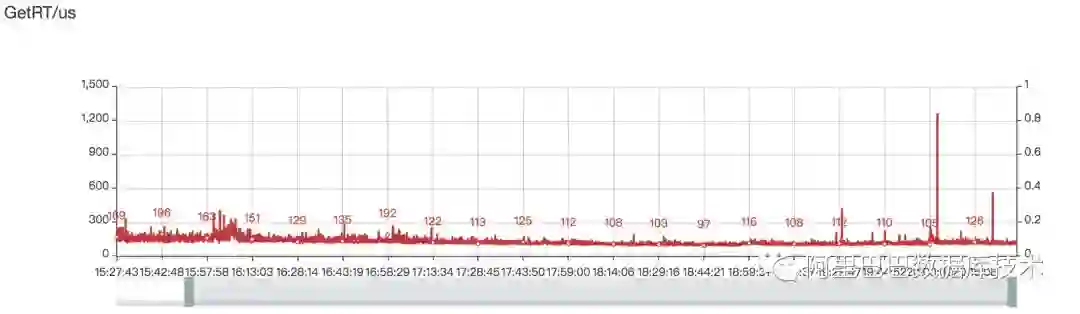
经过以上两个主要优化,RT的稳定性有了明显的提升,见下图。这也意味着我们可以在保持客户感知超时率的情况下,将单机QPS的目标值拉得更高(即使用更少的机器承接预期的总QPS)。
RT毛刺优化前:
RT毛刺优化后:
——增强compaction能力
过去的单机能力不强,为了避免L0堆积(Level 0,L0的每个数据文件由memtable dump到磁盘生成),LDB优先对L0做compaction。但这在高输入流量时可能造成L1数据堆积(Level 1,L1的每个文件由多个L0数据文件与原有的L1文件compaction而成),且由于L1越堆越多,L0往L1的compaction每次产生的写入放大也会越来越大,反而造成L0越堆越多的恶性循环。
在现在的CPU和SSD的性能条件下,单个的memtable数据compaction和较为平衡的不同Level间数据合并不再是高耗时的任务,因此适当放宽L0文件个数的容忍度,在其它层数据很多时优先对其他层做一下compaction,可以降低整体的写入放大,降低SSD磁盘带宽的开销(因而也提升了SSD的使用寿命),反而提升了整体的compaction性能。经测试,修改compaction策略后,单机的compaction处理能力最多可提升至2倍。
与此同时,我们还对系统配置进行优化降低错误率,包括:增大vm.min_free_kbytes、关闭透明大页、对Tair有中断均衡问题的机器进行了告警检查,对有问题的机器重新进行了中断均衡。通过系统配置层面的优化,大幅度地降低了系统层面对应用的干扰,增强了服务层面的稳定性,不会在高QPS时RT抖得厉害,因此也就大幅减少了在较高水位QPS时需要的集群扩容
后续Tair LDB还将会有众多优化,例如将内嵌MDB切换成使用RCU优化的高性能MDB,同时简化运维配置,以充分发挥内置缓存的作用,预计对读性能会有较大提升;冷热分离集群的使用,预计对成本和性能都会有较大的提升;存储计算分离,降低大促成本。
4、前沿技术-LDB在FPGA上的试用
Tair LDB使用了近几年很流行的LSMtree(log-structured merge-tree)做数据存储格式。总所周知LSM由于是连续写,对磁盘性能友好,但避免不了的是compaction,即把不同版本的数据合并成一份,去掉过期数据。LSM compaction是计算密集型和磁盘IO密集型。
Tair LDB通过使用和数据库事业部硬件加速团队合作的FPGA加速compaction,纯compaction计算部分加速比为50~80倍,加上读写磁盘后的端到端compaction速度提升2~4倍(受SSD带宽影响),随着SSD速度的提升,FPGA相比CPU带来的优势会更加明显。
在750字节大小的KV put情况下,使用FPGA后QPS的提升可达56%。由于FPGAcompaction速度比CPU快几倍,因此QPS进一步提升的优化空间也大幅提升了。
此外,FPGA compaction卸载的CPU可以用来混布例如MDB等其他服务,或用来增加读写数据的线程以进一步提升QPS。
今年Tair使用了FPGA机器搭建线上的备集群,主要是QPS高的集群以充分发挥FPGA的作用。FPGA机器相比CPU机器性价比提升是1:1.5,省了30%的成本。其中还有不少成本是增加的SSD存储的成本,如果纯算FPGA带来的性价比提升则会更高。
5、架构升级-LDB弹性上云
Tair LDB 集群存储的是持久化数据,和 DB 的部署方式类似。即每个地域部署一套,该地域若干机房均访问这个集群,而不像 MDB那样随着机房/单元级别弹性创建。
LDB部署在中心、上海非云、深圳非云环境,上海云和深圳云环境的业务访问各自非云环境的 LDB 集群。但是今年不同往年,由于网络部署架构的缘故,上海云访问上海非云平均有1~2 ms 的时延。对 DB 调用来说,每次多这么一点 RT影响也没有多大。
但是对 LDB 来说,业务要求的Latency 就是要小于 1ms 的,从云访问非云的 LDB等于 Latency 多了好几倍。大部分业务一次调用中访问LDB 次数不是特别多,整个调用链多个十来ms问题也不是很大。但是对于强依赖 LDB 存储和进行数据计算的业务而言,Latency 翻倍就意味着更多的业务机器部署资源投入。
怎么解决这个问题呢?在云单元也搭建一套 LDB 集群,然后配置数据同步吗?这样能解决,但是成本问题马上就是当头一棒。即使业务愿意承担多出来一套集群的成本,持久化的 LDB 集群新建和搬迁数据也是个大工程。最终和业务沟通后,决定还是在云单元部署集群。但是沟通了云单元的情况后才得知,只有计算机型,只有计算机型,只有计算机型。
LDB 是磁盘的存储引擎,需要 SSD 本地磁盘才能满足 Latency 要求,而计算机型用的大容量的磁盘都是云盘,压根满足不了我们的Latency 要求。留给我们的时间并不多了,需要尽快的拿出应对策略。云单元可以提供给我们大容量内存的计算机型,有接近300G的可用内存。
于是我们提出来能否把数据都放在内存里,云盘做数据备份,LDB 默认是双份数据的存储模式,内存的数据也会实时的写两份,单点故障也不会丢失数据。时间很紧迫,这个系统改造也必须足够简洁和可靠,可没有多余的时间留给我们反复验证。最终 LDB 的内部存储模型如下:
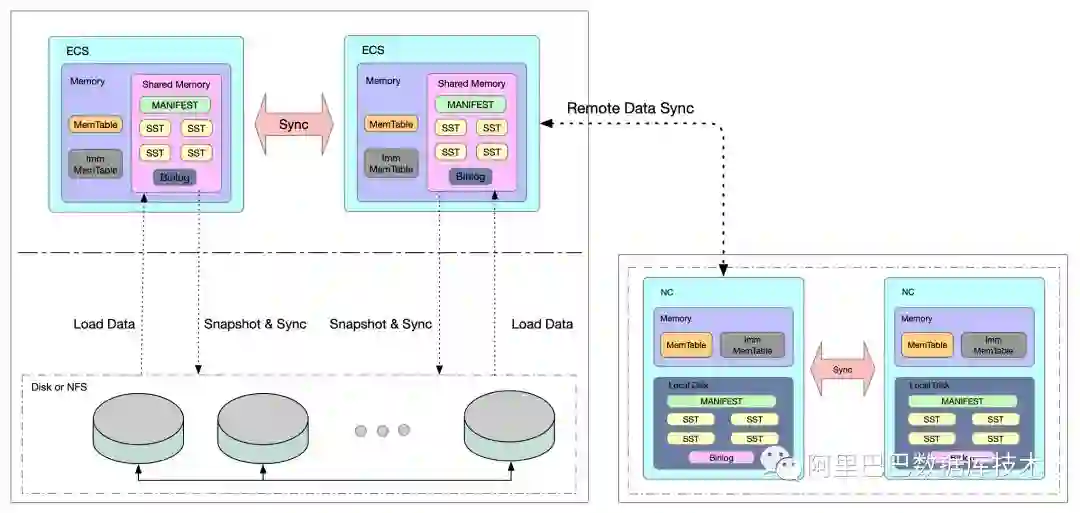
普通模式下,LDB 内部的 LevelDB 存储引擎只有 MemTable/Imm-MemTable 是存储在内存中的,其他的诸如WAL(Write-Ahead Log)文件、 SST 数据文件以及元数据 MAINIFEST 文件都是存储在持久化介质上的。新的模式将 WAL、MAINIFEST 以及部分的 SST 文件放置在共享内存中。
为什么是部分 SST ?我们知道 LevelDB 的数据存储是分层的,这样只要指定第一层的大小,以及共享内存放置前多少层的 SST 数据文件,那么其占用的内存就可以计算出来,同时高层的 SST 数据文件可以配置写到云盘中,这样有云盘兜底,内存使用超出预定的阈值后也不会有问题。
共享内存中的数据会定时的创建出 SnapShot,异步同步到云盘中进行存储,每次 SnapShot 的同步均会计算两次 SnapShot 之间的差异,只进行增量同步操作。其他的诸如后台加速合并的层级限制,SSTMove 的层数判断等细节均不细表。
这个设计的可靠性如何?首先数据是实时写双份的,如果单点宕机不可恢复,依赖Tair 本身的多副本分片均衡算法,可以做到数据完全不丢失。如果是进程重启,因为WAL(Write-Ahead Log)文件、 SST 数据文件以及元数据 MAINIFEST 文件都是放置在共享内存中的,所以也能做到数据不丢失。
最后,如果多台机器被重启呢?此时完全丢失了本地的所有数据,需要从云盘的 SnapShot 中加载数据到共享内存中,但是 SnapShot 是有备份的间隔的,所以最坏的可能就是丢失了一个备份间隔的数据。
为了解决这个问题,我们配置了从云集群到非云集群的实时数据同步,这样如果真遇到了云单元多台机器被重启的情况,我们会立即切换访问到非云机房,并且在机器恢复后迅速从非云机房补全一个 SnapShot 备份间隔的数据过去(这段时间里,业务因为从云访问非云,短时间的 RT会受到影响)。
实际上由于业务的特殊性,丢失短时间的数据没有太大的问题,补全了最好,无法补全也不会有很大影响。这个方案迅速拍定、修改和测试后上线压测, 总体成本节省了近百台机器。
2018年双11的云单元部署后表现满足预期,业务访问的 Latency 保证了1ms 以内,满足了双十一大促的需求。
6、前沿技术-NVM
Tair MDB在QPS能力不断突破,内存容量逐渐成为了集群成本继续优化的瓶颈。使用密度更高(单条DIMM容量目前最高512G)、延时和DRAM在一个级别的NVM是突破这一瓶颈的有效手段(Intel Optane DC persistentmemory是目前使用的NVM产品之一)。从今年618开始,Tair MDB在线上灰度部署了使用NVM的版本,经历了多次压测,表现非常稳定。
详细实现细节和NVM相关的更多介绍参见文章 →
非易失性内存在阿里生产环境的首次应用:Tair NVM最佳实践总结
双11的备战过程中,经过服务器同学的努力,确定了NVM的标准机型,并且在全链路压测之前顺利交付。相对于618使用的机型,双11使用的标准机型中,CPU和NVM的硬件稳定性都有了更高的保证。
在双11之前的压测过程中,通过Tiddo的集群性能评测系统,将多台节点的流量引入到一台NVM节点进行压测,验证了在使用大容量场景下(终态部署情况下单个NVM节点使用的容量会在420G左右)的性能表现。在选定的集群中,NVM节点的占比从之前的7%上升到了23%,为下个财年更大规模的部署打下了很好的基础。
NVM的硬件特性给Tair MDB服务带来了一些挑战,在双11之前已经通过无锁实现、分离元数据存储等手段进行了一些优化,后面还会在资源调度、后台任务优化等方面继续着力,将NVM带来的成本收益最大化。
7、管控升级-效率提升
今年,Tair的管控系统Tiddo全面升级。集群版本的升级,集群的扩缩容,集群的部署,数据迁移等功能,配置管理功能,全线接入Tiddo管控平台。今年新增实例组2860条,在双11的准备过程中,自9月份起,管控系统共进行集群生命周期相关操作数千条,包含集群的创建,销毁,升级操作。
通过配置管理功能,共计推送配置1w+条。这些平台性的操作,极大的解放了运营运维的工作,同时在线上稳定性上提升明显。
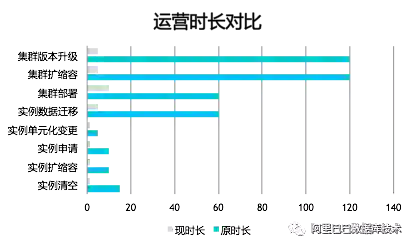
通过管控系统的升级,实现了效率的百倍提升,运营可靠性的提升。
8、RDB的进化之路
在过去的一段时间,RDB新增或升级了诸多新特性,主要有:
新数据结构:RDB2.0新增exhash、exstring、gis、bloomfilter等新数据结构,其中gis在高德和菜鸟业务中得到大量使用,bloomfilter也在集团内计算平台的首次得到大规模使用,表现稳定。
新协议栈和异步SDK:跨越两个版本,集团内全面支持二进制协议栈和dualstack,已经有14%的应用使用了新协议,及异步sdk;双11后会面向优酷、高德等大范围推广。
热点上线:HKAR从方案设计到开发落地,经过线下的反复测试,并最终在线上两个集群上线进行小范围验证。双十一后HKAR也将大规模上线使用,解决业务的读热点问题。
Docker化支持:RDB目前已经实现ragent、rserver、patroller、hkd组件的docker化,并已经采用docker方式部署、上线了technetium容灾集群,在今年的双十一中得到首次验证,表现稳定。
anywhere部署支持:RDB目前提供经典部署、vip部署和dip部署三种部署模式,其中vip的部署模式已经成功的在高德集群下线diamond中得到首次使用和验证,anywhere的支持给RDB的发展带来很多的灵活性。
支持逻辑id: 通过逻辑id,可以透明切换后端实例到RDB或PDB,也为后续RDB的水平扩缩容提供基础支持能力。
优化资源调度、提供超卖能力:支持新调度算法,均衡集群实例分布和调度,提供超卖能力,减少成本、提升资源使用率。
提升运维能力、丰富巡检信息:新增更多运维接口、自动化运维脚本,巡检上支持对HKAR、部署模式等信息的巡检和上报。
十年双11,Tair一路走来。我们追求产品性能的极致,也时刻不忘系统的稳定。TAIR始终聚焦发展最先进的超大规模缓存和超高速online NoSQL数据库产品,以及相关的最新技术、前沿学科,并积极推进标准化和理论创新,服务好用户的需求。
最后,欢迎大家加入存储事业部Tair团队!分布式在线存储系统Tair 专注于承担超大流量下的在线访问加速,阿里巴巴集团大规模使用,在每秒数亿次访问请求的背后,提供着超低延时的响应。场景包括各类在线缓存,内存数据库,高性能持久化NoSQL数据库等,在高并发,快速响应和高可用上追求极致。
在这里,你会遇到亿级别访问的尖峰时刻,不同类型业务错综复杂的场景需求,万台规模服务器集群的运营支撑,业务全球化等各类技术挑战。简历投递方式:zongdai@alibaba-inc.com。

想了解8.5亿流量洪峰背后,Tair还有哪些“黑科技”吗?
12月16日,阿里巴巴双11数据库技术峰会邀您共话10年数据库技术的升级与蜕变,届时来自阿里存储技术事业部的高级技术专家百润,将为您详细揭秘Tair技术。
我们还将分享双11数据库最新的设计与实战经验,解读超大规模高并发场景下数据库体系的挑战与思考,与业界大牛面对面畅聊企业级数据库解决方案和最佳实践。
倒计时4天,干货满满,报名从速!
更多会议详情,请猛戳 → 十年沉淀 阿里双11数据库技术峰会北京站邀您同行
12月16日 约会帝都
领略创新的无尽魅力





