滴滴离线索引快速构建FastIndex架构实践

作者丨钟华
策划丨Tina
开源地址:https://github.com/didi/ES-Fastloader
在大数据场景下,业务一般会把 Mysql 中的数据同步到 Hive 表中,然后通过 Hive 脚本对数据进行加工,并将得到的 Hive 数据同步到 ES 中,最终通过 ES 对外提供准实时的查询服务。在 Fastindex 功能上线之前,我们主要通过 DataX 的 Hive2ES 功能将数据从 Hive 导入 ES 中。在数据量较小的时候,DataX 可以快速完成数据迁移的工作。但随着数据量的增加,当业务的 Hive 数据达到 GB 甚至 TB 级别的时候,DataX 的导入方式就会出现一些问题,主要有以下两点:
导入时间过长。使用 DataX 导入大量数据时,一般需要几个小时的时间,如果 Hive 的产生时间偏晚,意味着业务只能在当天晚上甚至第二天才能查询最新数据,这会极大的影响业务数据的及时性。
-
ES 机器负载过高。在 DataX 导入数据的过程中,由于有大量数据写入,ES 的 DataNode 会出现负载很高的情况,进而会影响该节点的查询服务,最终影响 ES 服务的稳定性。由于以上两个问题,使得 DataX 方案在导入大 Hive 表时,导入时间和 ES 查询稳定性很难满足业务的需求,所以我们发起了 FastIndex 项目,希望通过技术手段解决上述问题。
要想解决 DataX 写入过程中的问题,我们必须分析下 DataX 的写入流程,找出产生上述问题的具体原因,然后我们才能根据这些原因确定 FastIndex 项目的总体方案。
DataX 的写入 ES 的流程主要如下所示:
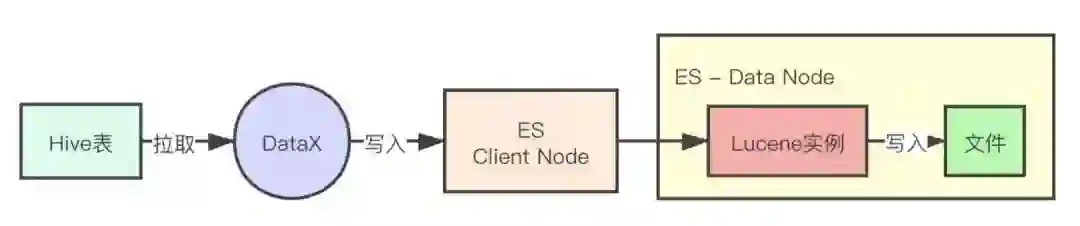
DataX 负责从 Hive 表中把数据拉取出来,然后将数据写入 ES 的 ClientNode 提供的接口中,然后 ClientNode 将数据转发到 DataNode 中。DataNode 负责将获得的数据写入 Lucene 实例,最终 Lucene 实例会将获得的数据通过压缩 / 编码写入底层的 Lucene 文件中。由于需要对数据进行压缩和编码,Lucene 实例产生 Lucene 文件的过程会消耗大量 cpu 资源,从而导致了 DataNode 所在的机器负载偏高,影响 ES 查询服务的稳定性。同时也由于 cpu 资源的紧缺,整体导入过程也需要更长的时间。
通过分析 DataX 的写入流程,我们可以知道瓶颈点主要是 Lucene 实例产生 Lucene 文件的过程。我们很难通过优化 Lucene 代码的方式,降低产生 Lucene 文件需要的 CPU 资源。所以我们采用了另外一种方式,其实我们主要的目的是不让导入数据过程占用 DataNoda 上的 CPU 资源,那我们可不可以将产生 Lucene 的过程直接搬到别的地方执行,然后将最终得到的 Lucene 文件直接拷贝回 DataNode 的机器上呢?答案是肯定的。以下是 FastIndex 方案的流程图:
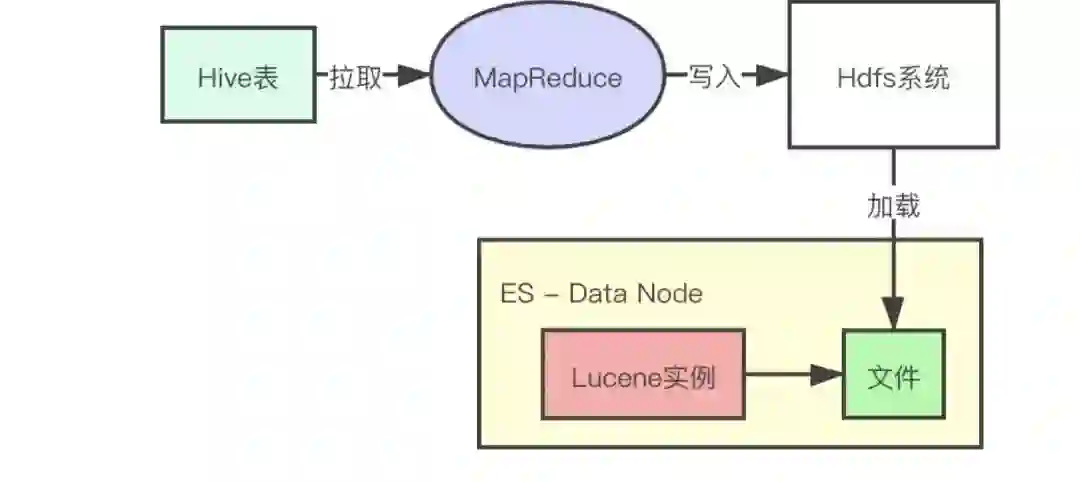
我们使用了 MapReducer 任务将 Hive 数据转化成 Lucene 文件,并在 MapReducer 任务结束的时候将 Lucene 文件保存在 Hdfs 文件系统中,然后我们再将 Lucene 文件拉取到 DataNode 上,并导入到 ES 实例中。这样就可以将 Hive 数据导入到 ES 中了,这个方案可以有效解决 DataX 如下的两个问题。
1. 导入时间过长问题
导入时间过长,主要是由于 CPU 紧缺,但是我使用的是 MapReducer 任务,可以通过调整并发度获得 Hdfs 上大量的 CPU 资源。所以只需要配置足够的并发度,我们可以在很短的时间内将数据导入到 ES 中。
2. ES 机器负载过高问题
由于 DataNode 没有参与到构建 Lucene 文件的过程,所以在导入过程中 ES 机器不会出现 CPU 紧缺的情况,从而保证了 ES 服务的稳定性。
根据上述的方案,我们最先需要解决的问题是如何将 Hive 数据转化成 Lucene 文件。由于 ES 的单个索引可以分成多个 Shard,而单个 Shard 就对应着一个 Lucene 文件,所以我们不能简单的将单个 Hive 表的数据导入到单个 Lucene 文件。我们需要先把数据按照算法拆分成多份数据,然后再将各份数据转化成 Lucene 文件。因此 Hive 数据转化成 Lucene 文件的过程主要分成以下两部分,他们分别对应 MapReduce 任务的 Mapper 和 Reduce。
3.1.1 Mapper 任务
Mapper 主要负责将 Hive 表数据按照 Reducer 任务个数重新分配,主要流程如下所示:
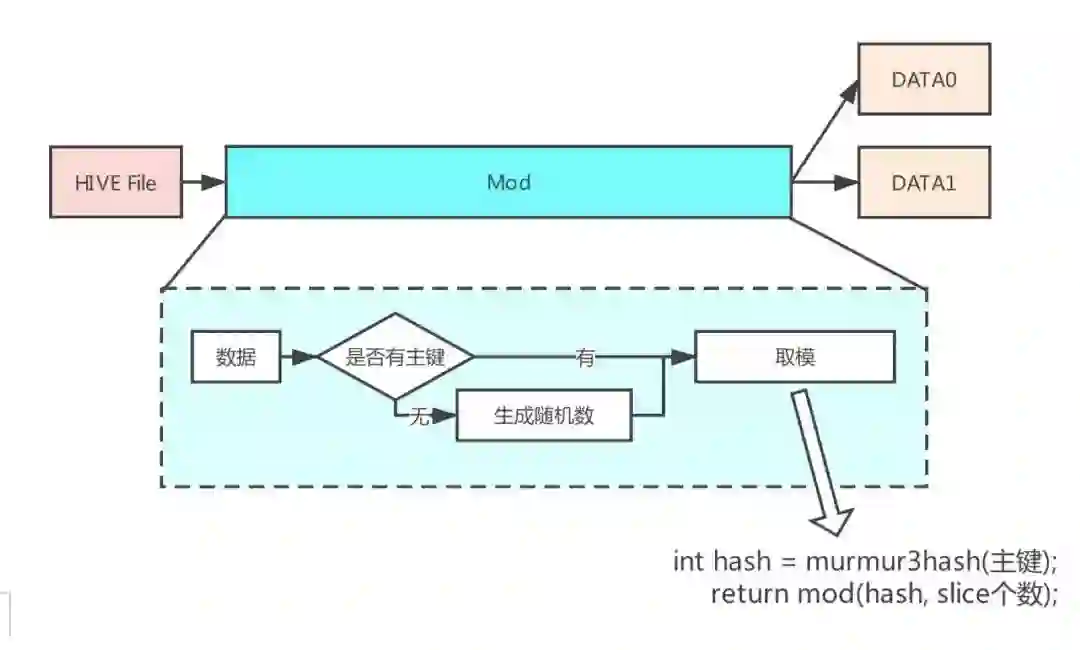
在处理 Hive 数据的过程中,Mapper 会判断 Hive 数据是否有主键,如果有主键,则根据主键的值确定单行 Hive 数据属于哪个 Reducer 任务。如果没有主键,则产生一个随机数取模,保证各个 Reducer 任务处理的数据量是大致相同的。
3.1.2 Reducer 任务
Reducer 负责将 Hive 数据转化成 Lucene 文件。将 Hive 数据转化成 Lucene 文件主要有以下三种方法 :
在 Reducer 程序中启动一个 Lucene 实例,然后按照 ES 的数据格式写入数据。这种方法需要我们非常了解 ES 的内部实现,并且每次 ES 版本升级都需要兼容高版本 ES 的数据格式。
在 Reducer 程序中启动一个 ES 实例,然后调用 ES 的函数写入数据。这种方法在 2.3 版本的 ES 可以直接实现,但是 6.x 版本的 ES 已经不支持这种启动方式。
-
在 Reducer 所在的机器上启动一个本地的 ES 进程,然后通过 ES 的 http 接口写入数据。这种方式由于需要经过 http 接口写入数据,性能会比前两种方式略低。但是这种方式可以很方便的支持 ES 版本升级,只需要替换 ES 的相关 Jar 包就可以了。
我们采用了第 3 种方法。在数据写入完成之后,我们可以直接获得本地 ES 实例底层的 Lucene 文件,最终产生的 Lucene 文件会保存在 Hdfs 上。整个流程主要如下所示:
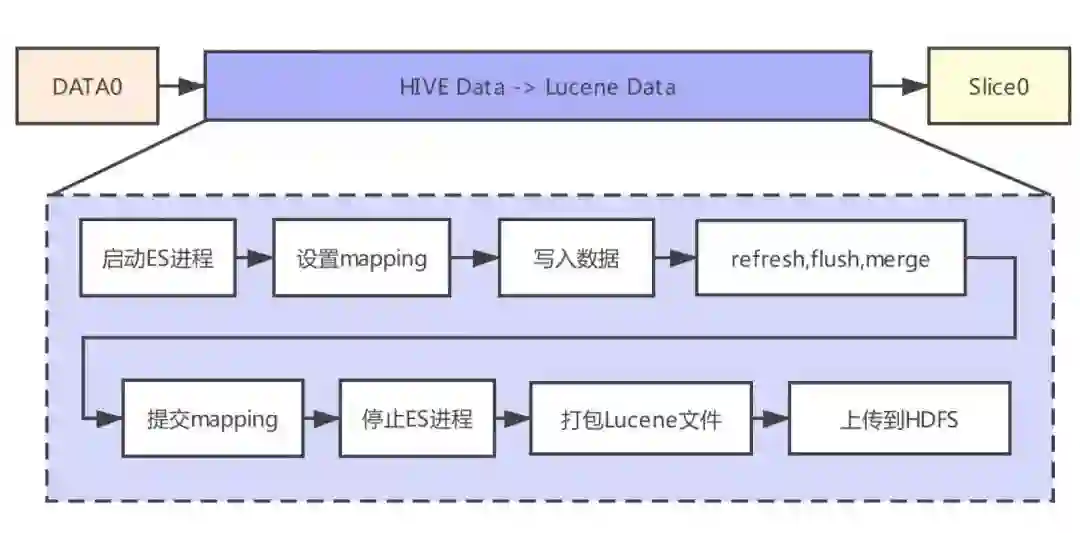
整体流程的具体说明如下:
在 Reducer 启动 local ES 实例
使用业务索引的配置在 local ES 中创建一个索引,索引名为 A
通过调用 local ES 的接口写入 Hive 数据到索引 A 中
写入完成之后,调用 refresh,flush,merge 接口,主要目的是将内存中的数据同步到磁盘上,同时 lucene 文件中只有一个 segment,提高索引的查询性能
获得索引 A 的 mapping,Hive 表中可能有新字段,我们需要将新增字段的类型添加到业务索引中停止 local ES 实例
将 local ES 实例底层的 lucene 文件打包
-
将打包文件上传到 hdfs 上
在 MapReducer 任务产生 Lucene 文件之后,我们可以通过 Hadoop 工具将 Lucene 文件从 Hdfs 上拉取到 DataNode 的机器上。现在我们需要将 Lucene 文件加载到 ES 程序中,让 ES 程序能够使用 Lucene 文件对外提供查询服务。
使用 ES 现有的功能,我们可以通过关闭 / 打开索引的方式将 Lucene 文件加载到运行的 ES 进程中,具体过程如下:
调用 close 接口关闭索引
删除索引对应目录下的文件
将 Lucene 文件拷贝到索引对应的目录下
调用 open 接口打开索引
-
等待索引状态变成 Green,对外提供查询服务
虽然按照上述过程我们可以将 Lucene 文件加载到 ES 中,但是由于在加载过程中,需要将索引关闭,这段时间索引是不能提供查询服务的。而且这种方法也不能支持索引原先就有数据的情况,老的数据会被删除,而不是和新生成的 Lucene 文件融合。基于上述原因,我们没有采用关闭 / 打开索引的方式导入 Lucene 文件。
最终我们的导入过程主要基于 Lucene 的 IndexWriter.addIndexs() 接口实现。addIndexs 接口允许我们将外部 Lucene 文件加载到当前 ES 正在使用的 Lucene 实例中,从而实现 Lucene 文件的导入。而且在导入过程中,相关索引是可以持续提供查询服务的。我们开发了 ES 插件(AppendLucene)来实现上述功能,该插件的执行流程如下:
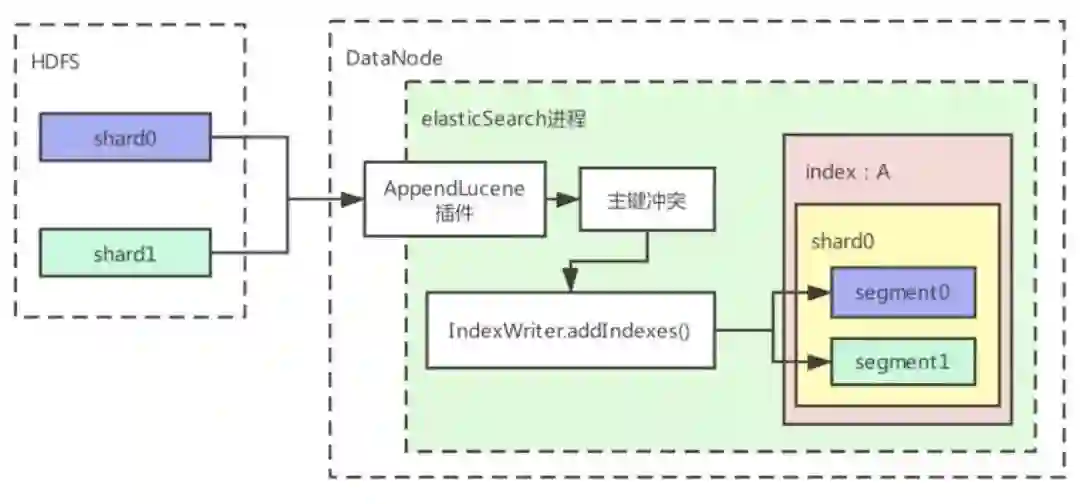
整体流程的具体说明如下:
1、新生成的 Lucene 文件被拉取到 DataNode 本地磁盘;
2、当文件都下载到本地之后,会调用 AppendLucen 提供的 Http 接口,参数主要是索引名,shard id 以及新生成 Lucene 文件的路径;
3、Shard 合并插件会做以下操作;
使用新 Lucene 文件中的主键去查询当前索引中的数据,如果主键存在,则需要在当前索引数据中删除这个主键的数据
-
调用 addIndexes,将新 Lucene 文件的数据加载到当前索引中
4、Shard 合并功能完成
3.2.1 shard ID 映射
到目前为止,我们已经可以将数据加载到 ES 中了,基本功能可以跑通了。但是在实际运行过程中,ES 索引的 Shard 个数不能配置太多,在特大查询的场景下,太多 Shard 会产生过多请求的副本,进而会将 clientNode 的网卡打满。而到目前为止,我们的 Reducer 任务个数必须和 Shard 个数相同,如果降低 Shard 个数,意味着降低 Reducer 任务数据,整个数据导入时间就会变长。为了降低 shard 个数,我们需要将 Shard 个数和 Reducer 任务个数脱钩。我们采用的方案是将 Reducer 个数配置成 Shard 整数倍,然后在 Lucene 文件导入的过程中,将多个 Reducer 产生的 Lucene 文件导入到一个 Shard 中。
上面介绍的 AppendLucene 插件可以支持将多个 Lucene 文件导入到一个 Shard,但是我们还需要解决一个问题,就是 Reducer 产生的 Lucene 文件和 Shard 的映射关系。即我们如何决定某一个 reducer 任务产生的 lucene 文件需要合并到 ES 哪个 Shard 中。其中的算法如下所示:

左边是 reducer 文件的编号,右边是 ES 中的 shard 编号,按照上述公式,我们就可以根据 lucene 文件编号得出对应的 ES 的 Shard 编号。
经过上面的业务背景和技术探讨,我们最终完成了如下图的系统架构。
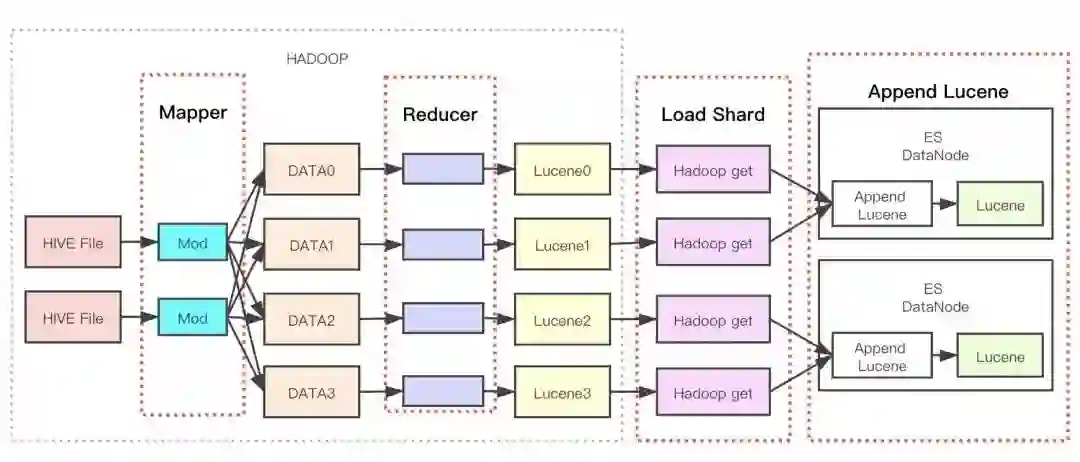
整个架构主要分钟 3 部分,运行在 HADOOP 中的 MapReducer 任务,Load Shard 过程,以及 AppendLucene 插件部分。
MapReducer 任务主要负责将 Hive 表数据转化成 Lucene 文件。
LoadShard 任务主要负责将 Lucene 文件搬迁到 ES 中,并调用 AppendLucene 提供的接口。
AppendLucene 插件 负责将新增的 Lucene 文件合并到 ES 实例中。
目前已经有 500+ 个业务使用 FastIndex 导入 HIve 数据,在上线 FastIndex 功能之后,我们取得了以下收益:
效率提升:数据导入时间普遍从几小时降到了几十分钟,其中滴滴标签系统的乘客宽表数据,总数据量为 30TB,切换到 FastIndex 之后,导入时间从原先的 8 小时降到到 1.5 个小时。
成本下降:滴滴标签系统乘客宽表数据切换到 FastIndez 之后,相比以前的导入方式,节省了 7w+ 每月的成本,而由于索引的生成直接复用了标签系统 hive 表原有的队列,因此 hadoop 这块成本基本没有上升。
稳定性提升:在大批量离线数据导入过程中,由于索引的生成没有消耗 ES 节点的 cpu 资源,因此业务查询的也没有受到影响。
钟华,资深研发工程师 滴滴ElasticSearch引擎核心研发人员,目前在负责FastIndex、ES查询优化方向的工作,喜欢研究开源大数据技术
InfoQ 读者交流群上线啦!各位小伙伴可以扫描下方二维码,添加 InfoQ 小助手,回复关键字“进群”申请入群。大家可以和 InfoQ 读者一起畅所欲言,和编辑们零距离接触,超值的技术礼包等你领取,还有超值活动等你参加,快来加入我们吧!


点个在看少个 bug 👇