优化背后的数学基础
深度学习中的优化是一项极度复杂的任务,本文是一份基础指南,旨在从数学的角度深入解读优化器。

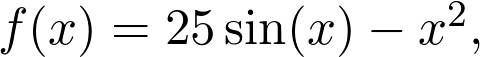
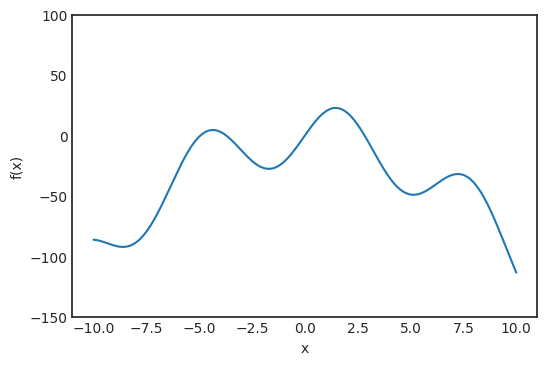
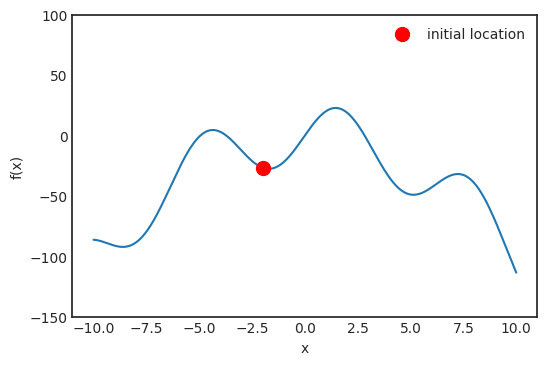
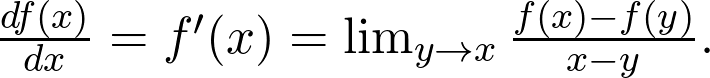
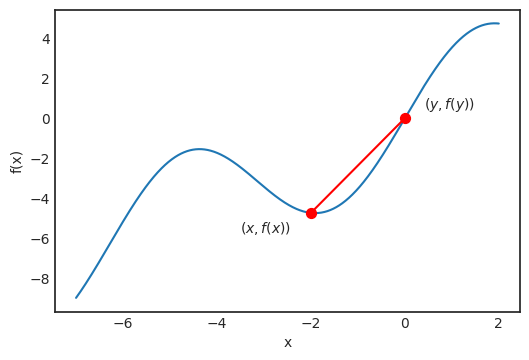
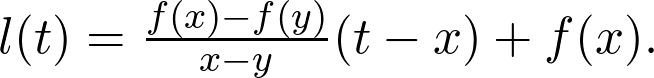
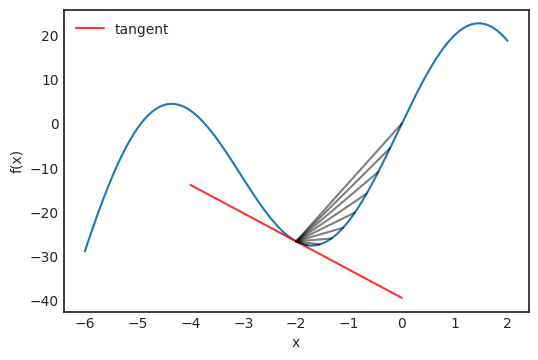
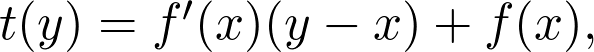
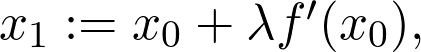
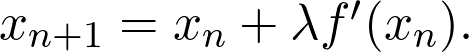
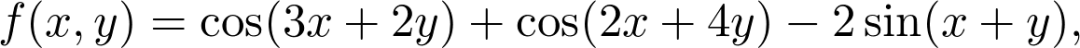

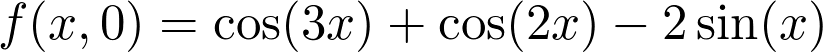
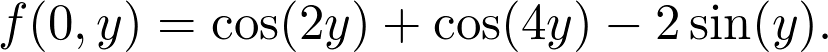
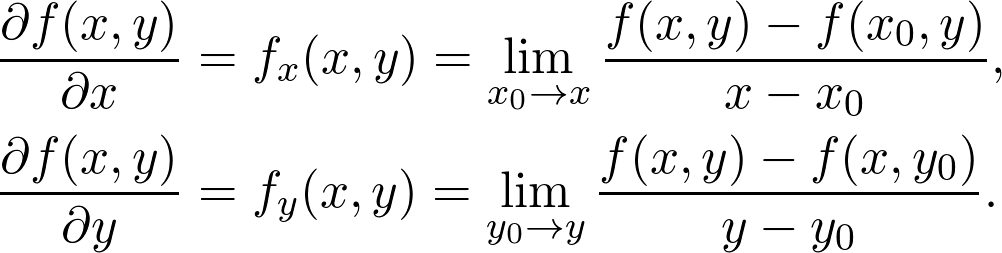
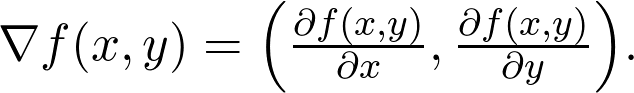
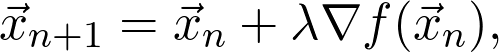
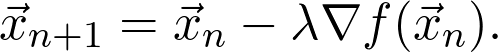
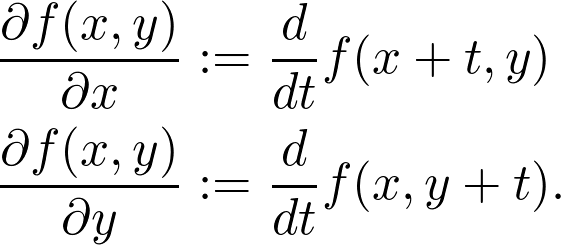
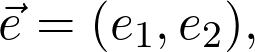
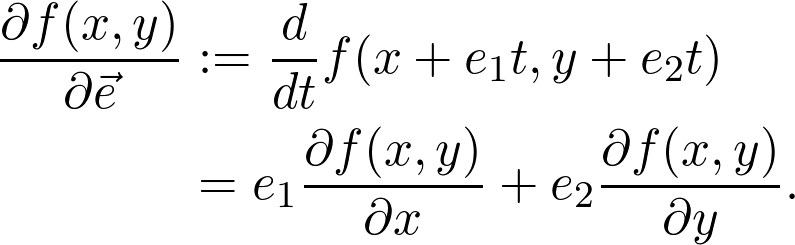
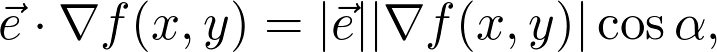
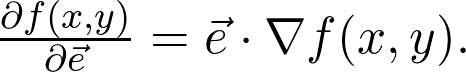
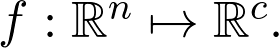
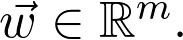
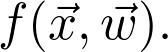
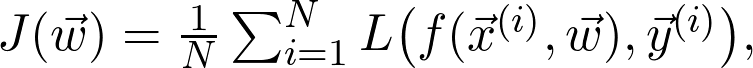
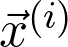 是观测值为
是观测值为
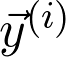 的第 i 个数据点
的第 i 个数据点
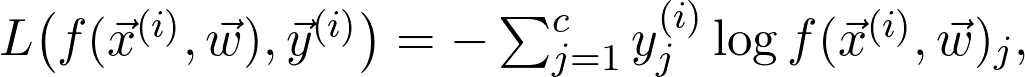
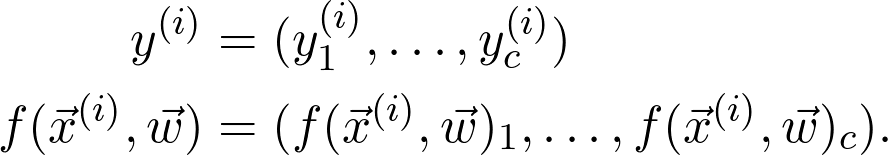
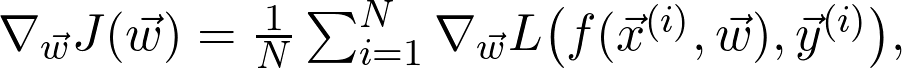
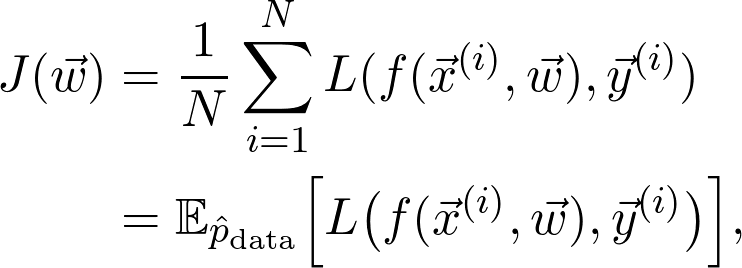
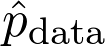 是训练数据给出的(经验)概率分布。
可以将序列写成:
是训练数据给出的(经验)概率分布。
可以将序列写成:
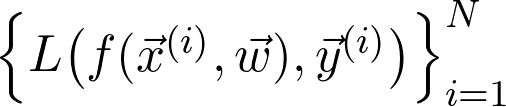
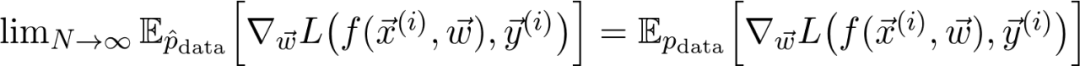
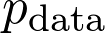 是真正的总体分布(这是未知的)。
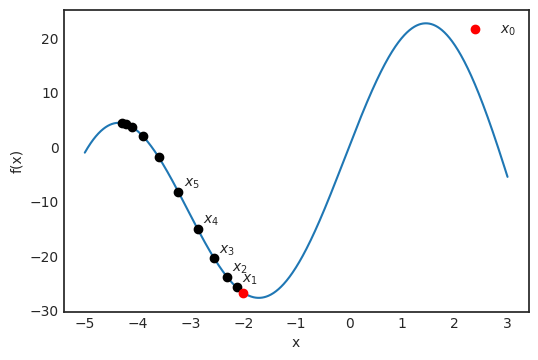
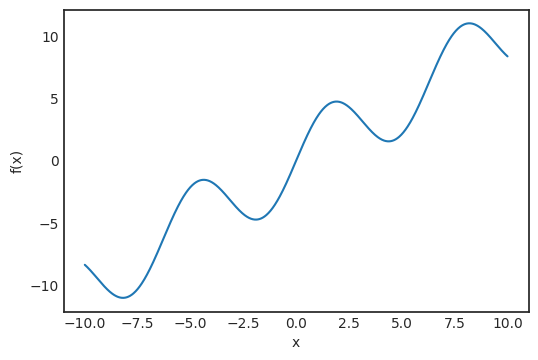
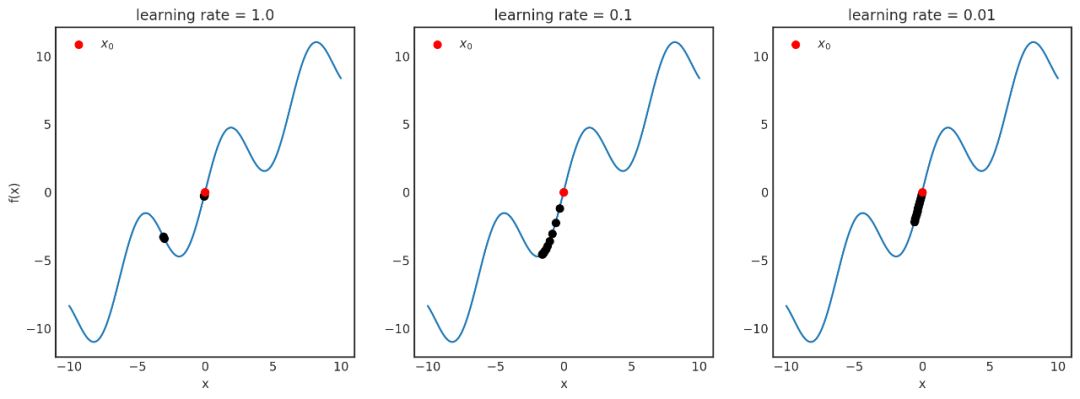
再详细点说,因为增加了训练数据,损失函数收敛到真实损失。
因此,如果对数据二次采样,并计算梯度:
是真正的总体分布(这是未知的)。
再详细点说,因为增加了训练数据,损失函数收敛到真实损失。
因此,如果对数据二次采样,并计算梯度:
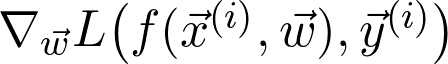
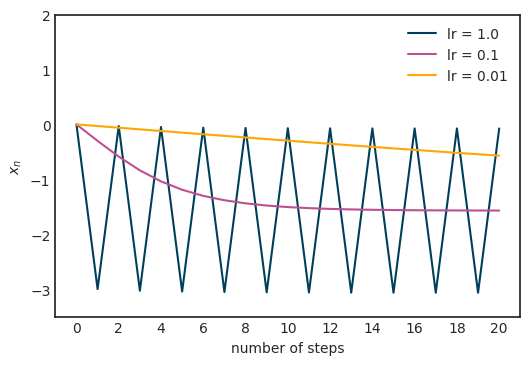
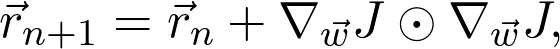
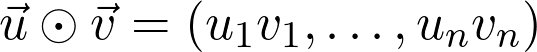
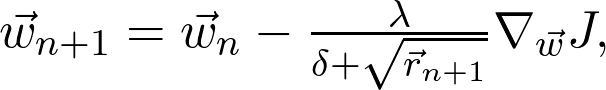

登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文