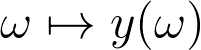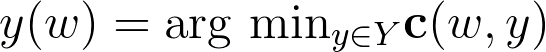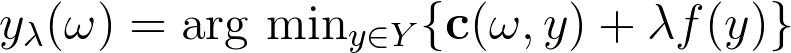选自TowadsDataScience
作者:Marin Vlastelica Pogančić
机器之心编译
参与:郭元晨、魔王
如何将组合求解器无缝融入深度神经网络?
ICLR 2020 spotlight 论文《Differentiation of Blackbox Combinatorial Solvers》探讨了这一难题,论文一作 Marin Vlastelica 撰文介绍了其主要思想。
论文链接:https://arxiv.org/abs/1912.02175
GitHub 链接:https://github.com/martius-lab/blackbox-backprop
机器学习研究现状表明,基于深度学习的现代方法和传统的人工智能方法并不一样。深度学习被证实可在多个领域中作为特征提取的强有力工具,如计算机视觉、强化学习、最优控制、自然语言处理等。不幸的是,深度学习有一个致命弱点,即它不能处理需要组合泛化能力(combinatorial generalization)的问题。例如,将地图作为图像输入,学习预测 Google Maps 上的最快路线,这是最短路径问题的一个实例。这样的问题还有很多,如 (Min,Max)-Cut 问题、最小损失完美匹配问题(Min-Cost Perfect Matching)、旅行商问题、图匹配问题等。
如果只是要孤立地解决此类组合问题,我们有很棒的求解器工具箱可以使用,从高效的 C 语言实现的算法,到更通用的 MIP(mixed integer programming)求解器,如 Gurobi。求解器需要定义明确的结构化输入,因此求解器面临的主要问题是输入空间的表示形式。
尽管组合问题是机器学习研究领域的课题之一,但对于解决此类问题的关注却一直有所不足。这并不意味着社区未把组合泛化问题视为通往智能系统路上的关键挑战。理想情况下,人们能够以端对端、没有任何妥协的方式,通过强大的函数逼近器(如神经网络)将丰富的特征提取与高效的组合求解器结合起来。这正是我们在论文《Differentiation of Blackbox Combinatorial Solvers》中所实现的目标,我们因此获得了很高的评审分数,并将在 ICLR 2020 会议上做 spotlight 演讲。
读者在阅读下文时需要注意,我们并不是在尝试改进求解器,而是要将函数逼近和现有求解器协同使用。
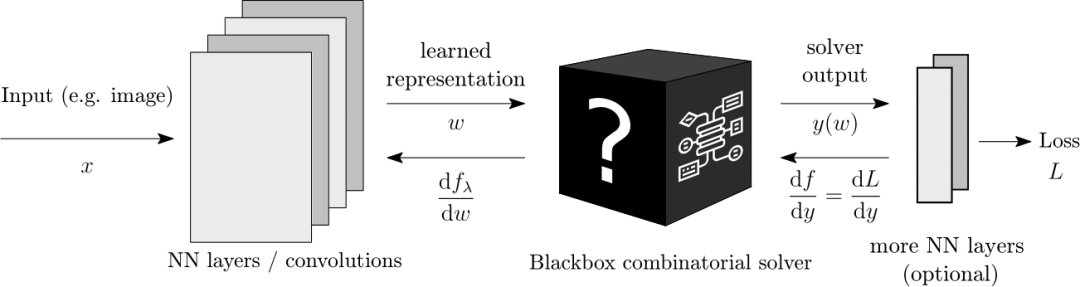
假设黑盒求解器(blackbox solver)是一个可以轻松插入深度学习的结构模块。
我们依据从连续输入(如图中的边权重)到离散输出(如最短路径、选中的图中的边)之间的映射来考虑组合优化器,定义如下:
求解器最小化某种损失函数 c(ω,y),如路径的长度。更具体地,求解器求解如下优化问题:
现在,假设 ω 是神经网络的输出,即我们要学习的某种表示。直观上,ω 表示什么?ω 旨在定义组合问题的实例。例如,ω 可以是用来定义图中边权重的向量。在这种情况下,求解器可以解决最短路径问题、旅行商问题,或者其他指定边损失的问题。我们想实现的是通过 ω 来作出正确的问题描述。
自然地,我们想优化该表示,使它最小化损失,即关于求解器输出的函数 L(y)。我们马上要面临的问题是损失函数是分段恒定的,这意味着对于表示 ω,该函数的梯度几乎处处为 0,并且在损失函数的跳跃处梯度未被定义。说白了,这样的梯度对于最小化损失函数没有用。
到目前为止,已经出现一些依赖于求解器松弛(solver relaxation)的方法,但它们不得不在最优性上作出一定牺牲。而我们提出了一种
不影响求解器最优性的方法
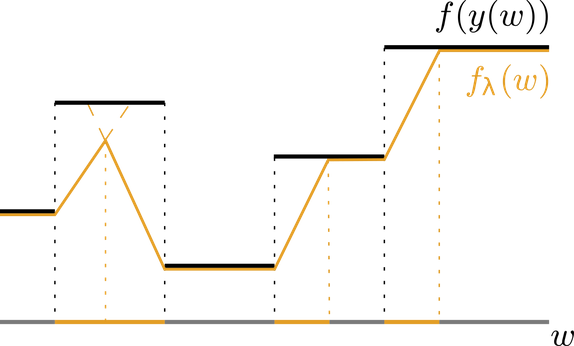
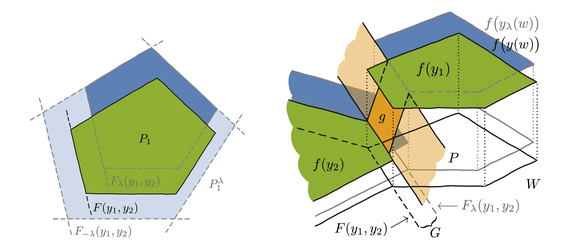
。我们通过定义原始目标函数的分段仿射插值来实现这一目的,其中插值本身由超参数 λ 控制,如下图所示:
如图,f(黑色)是分段恒定的。插值(橙色)以合理的方式连接恒定区域。例如,我们可以注意到最小值并没有变化。
当然,f 的域是多维的。这样,我们可以观察到 f 取相同值时输入 ω 的集合是一个多面体。自然地,在 f 的域中有许多这样的多面体。超参数 λ 有效地通过扰动求解器输入 ω 来使多面体偏移。定义了分段仿射目标的插值器 g 将多面体的偏移边界与原始边界相连。
下图描述了这种情况,取值 f(y2) 的多面体边界偏移至了取值 f(y1) 处。这也直观地解释了为什么更倾向使用较大的 λ。偏移量必须足够大才能获得提供有用梯度的内插器 g。(详细证明过程参见原论文。)
首先,我们定义该扰动优化问题的解,其中扰动由超参数 λ 控制:
如果我们假设损失函数 c(ω,y) 是 y 和 ω 之间的点积,则我们可将插值目标定义为:
请注意,损失函数的线性度并不像乍一看那样有限制性。所有涉及边选择的问题都属于此类别,这类问题中损失是边权重之和。最短路径问题(SPP)和旅行商问题(TSP)都属于此类问题。
![]()
在这个动画中,我们可以看到插值随 λ 增加的变化情况。
使用该方法,我们可以通过简单地通过修改反向传播来计算梯度,从而消除经典组合求解器和深度学习之间的断裂。
def forward(ctx, w_): """ ctx: Context for backward pass w_: Estimated problem weights """ y_ = solver(w_) # Save context for backward pass ctx.w_ = w_ ctx.y_ = y_ return y_
在前向传播中,我们只需给嵌入求解器提供 ω,然后将解向前传递。此外,我们保存了 ω 和在前向传播中计算得到的解 y_。
def backward(ctx, grad): """ ctx: Context from forward pass """ w = ctx.w_ + lmda*grad # Calculate perturbed weights y_lmda = solver(w) return -(ctx.y_ - y_lmda)da
至于反向传播,我们只需使用缩放系数为 λ 的反向传播梯度来扰动 ω,并取先前解与扰动问题解之差即可。
计算插值梯度的计算开销取决于求解器,额外的开销出现在前向传播和反向传播中,每个过程均调用了一次求解器。
我们使用包含一定组合复杂度的综合任务来验证该方法的有效性。在以下任务中,我们证明了该方法对于组合泛化的必要性,因为简单的监督学习方法无法泛化至没有见过的数据。同样,其目标是学习到正确的组合问题描述。
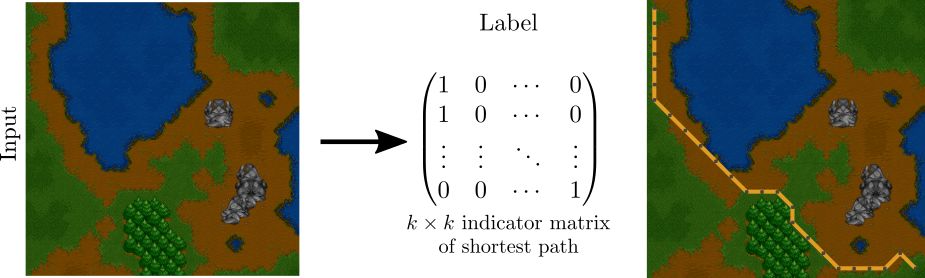
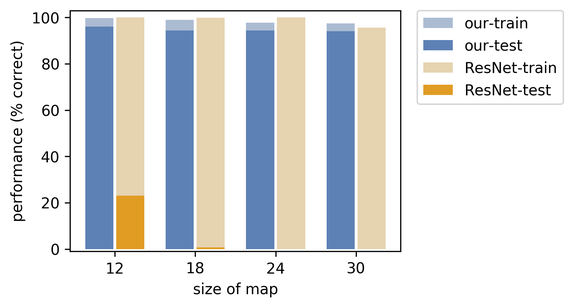
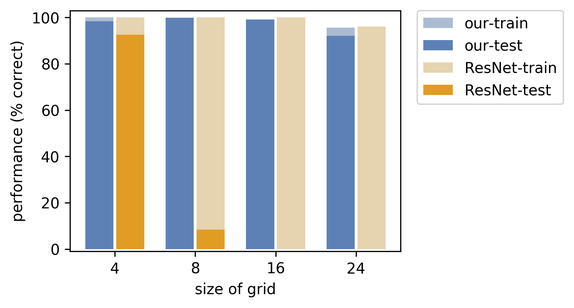
对于魔兽争霸最短路径问题,训练集包含《魔兽争霸 II》地图和地图对应的最短路径作为目标。测试集包含没有见过的《魔兽争霸 II》地图。地图本身编码了 k × k 网格。地图被输入卷积神经网络,网络输出地图顶点的损失,然后将该损失送入求解器。最后,求解器(Dijkstra 最短路径算法)以指示矩阵的形式在地图上输出最短路径。
自然地,在训练开始时,网络不知道如何为地图块分配正确的损失,但是使用该新方法后,我们能够学习到正确的地图块损失,从而获得正确的最短路径。下列直方图表明,相比于 ResNet 的传统监督训练方法,我们的方法泛化能力明显更好。
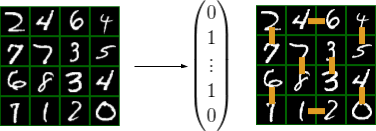
MNIST 最小损失完美匹配问题的目标是,输出 MNIST 数字组成网格的最小损失完美匹配。具体而言,在最小损失完美匹配问题中,我们应该选择一些边,使得所有顶点都恰好被包含一次,并且边损失之和最小。网格中的每个单元都包含一个 MNIST 数字,该数字是图中具备垂直和水平方向邻近点的一个节点。垂直向下或水平向右读取两位数字,即可确定边损失。
对于这个问题,卷积神经网络(CNN)接受 MNIST 网格图像作为输入,并输出被转换为边损失的顶点损失网格。接着将边损失提供给 Blossom V 完美匹配求解器。
求解器输出匹配中所选边的指示向量。右侧的匹配损失为 348(水平为 46 + 12,垂直为 27 + 45 + 40 + 67 + 78 + 33)。
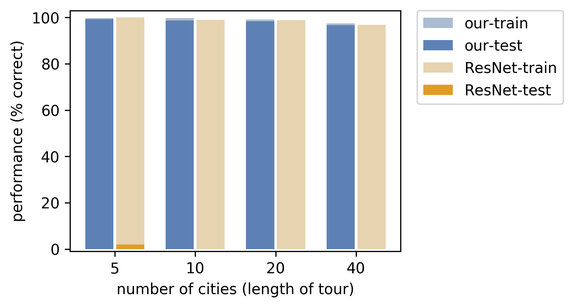
同样,在以下性能对比图中,我们注意到在神经网络中嵌入真正的完美匹配求解器带来了明显的优势。
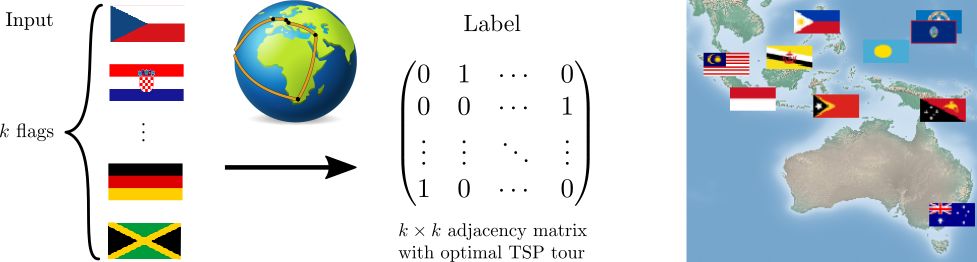
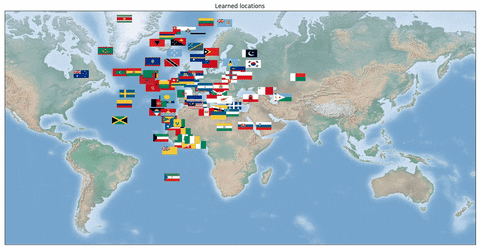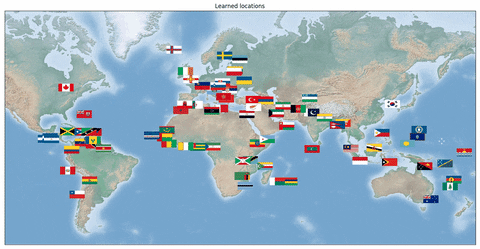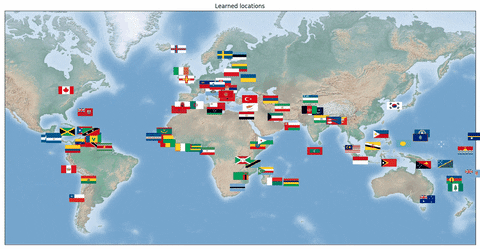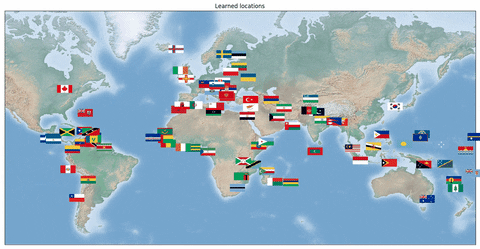
我们还研究了一个旅行商问题,其中网络应该输出各个国家首都的最佳 TSP 旅行线路。对于该问题,重要的是学习正确的首都位置隐表示。我们的数据集由国旗(即原始表示)和对应首都的最优旅行线路组成。一个训练示例包含 k 个国家。在这种情况下,将各个国家的国旗输入卷积神经网络,然后网络输出最优旅行线路。
在下面的动画中,我们可以看到训练期间学习到的各个国家首都在地球上的位置。最初,位置是随机分散的,但是在训练后,神经网络不仅学习输出了正确的 TSP 线路,还学习到了正确的表示,即各个首都正确的三维坐标。值得注意的是,这仅仅是通过在监督训练过程中使用 Hamming 距离损失,以及对网络输出使用 Gurobi 中的 MIP 实现的。
![]()
实验证明,事实上,在某些关于求解器损失函数的假设下,可以通过黑盒组合求解器传播梯度。这使得我们获得基于传统有监督方法的标准神经网络架构无法实现的组合泛化能力。
我们正在尝试说明,该方法在解决需要组合推理能力的现实问题中有着广泛的应用。我们已经给出了一种针对排名度量优化的应用 [2]。然而,问题在于(无论从理论还是实践上)我们可以沿着求解器损失的线性假设这一方向走多远。未来工作的另一个问题是,我们能否学习到组合问题的底层约束,例如 MIP 组合问题。
[1] Vlastelica, Marin, et al.「Differentiation of Blackbox Combinatorial Solvers arXiv preprint arXiv:1912.02175 (2019).
[2]Rolínek, Michal, et al.「Optimizing Rank-based Metrics with Blackbox Differentiation.」arXiv preprint arXiv:1912.03500 (2019).
https://towardsdatascience.com/the-fusion-of-deep-learning-and-combinatorics-4d0112a74fa7
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com