系列教程GNN-algorithms之一:《图卷积网络(GCN)的前世今生》
【导读】图卷积网络(Graph Convolutional Networks)作为最近几年兴起的一种基于图结构的广义神经网络,因为其独特的计算能力,受到了学术界和工业界的关注与研究。传统深度学习模型如 LSTM 和 CNN在欧式空间中表现不俗,却无法直接应用在非欧式数据上。为此,研究者们通过引入图论中抽象意义上的“图”来表示非欧式空间中的结构化数据,并通过图卷积网络来提取(graph)的拓扑结构,以挖掘蕴藏在图结构数据中的深层次信息。本文结合公式推导详细介绍了图卷积网络(GCN)的前世今生,有助于大家深入了解GCN。
系列教程《GNN-algorithms》
本文为系列教程《GNN-algorithms》的内容,该系列教程不仅会深入介绍GNN的理论基础,还结合了TensorFlow GNN框架tf_geometric对各种GNN模型(GCN、GAT、GIN、SAGPool等)的实现进行了详细地介绍。本系列教程作者王有泽(https://github.com/wangyouze)也是tf_geometric框架的贡献者之一。
系列教程《GNN-algorithms》Github链接:
https://github.com/wangyouze/GNN-algorithms
TensorFlow GNN框架tf_geometric的Github链接:
https://github.com/CrawlScript/tf_geometric
前言
Graph Convolutional Networks涉及到两个很重要的概念:graph和Convolution。传统的卷积方式在欧式数据空间中大展神威,但是在非欧式数据空间中却哑火,很重要的一个原因就是传统的卷积方式在非欧式的数据空间上无法保持“平移不变性”。为了能够将卷积推广到Graph等非欧式数据结构的拓扑图上,GCN横空出世。在深入理解GCN:

的来龙去脉之前,我觉着我们有必要提前对以下概念有点印象:
卷积和傅里叶变换本身存在着密不可分的关系。数学上的定义是两个函数的卷积等于各自傅里叶变换后的乘积的逆傅里叶变换。此时卷积与傅里叶变换产生了联系。
传统的傅里叶变换可以通过类比推广到图上的傅里叶变换。此时傅里叶变换又与Graph产生了联系。
由于傅里叶充当了友谊的桥梁,此时卷积和Graph终于搭上了线。
论文链接Semi-supervised Classification with Graph Convolutional Networks
拉普拉斯矩阵与GCN
(1)拉普拉斯矩阵及其变体
给定一个节点数为n的简单图G,D是G的度矩阵,A是G的邻接矩阵,则G的拉普拉斯矩阵可以表示为:

L中的各个元素表示如下:


拉普拉斯矩阵变体:
对称归一化的拉普拉斯矩阵:


随机游走归一化的拉普拉斯矩阵:


(2)拉普拉斯矩阵的优良性质:
拉普拉斯矩阵是半正定对称矩阵
对称矩阵有n个线性无关的特征向量,n是Graph中节点的个数
拉普拉斯矩阵可以特征分解
半正定矩阵的特征值非负
对称矩阵的特征向量构成的矩阵为正交阵


(3)GCN为什么要用拉普拉斯矩阵
拉普拉斯矩阵可以谱分解(特征分解)GCN是从谱域的角度提取拓扑图的空间特征的。
拉普拉斯矩阵只在中心元素和一阶相邻元素处有非零元素,其他位置皆为0.
传统傅里叶变换公式中的基函数是拉普拉斯算子,借助拉普拉斯矩阵,通过类比可以推导出Graph上的傅里叶变换公式。
傅里叶变换与GCN
(1)传统的傅里叶变换:

为离散变量时,对离散变量求积分相当于求内积,即:

这里的

为何这样说呢?是因为从广义的特征方程定义看:

A本身是一种变换,V是特征向量或者特征函数,λ是特征值。我们对基函数

可以看出

通过对比我们可以发现L相当于

从傅里叶变换的基本思想来看,对f(t)进行傅里叶变换的本质就是将f(t)转换为一组正交基下的坐标表示,进行线性变换,而坐标就是傅里叶变换的结果,下图中的

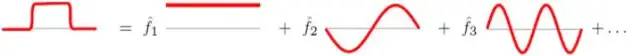
而这跟拉普拉斯矩阵特征分解的本质是一样的。所以我们可以很自然的类比出Graph上的傅里叶变换为,是在这个基的投影分量。
我们通过矩阵乘法将Graph上的傅里叶变换推广到矩阵形式:
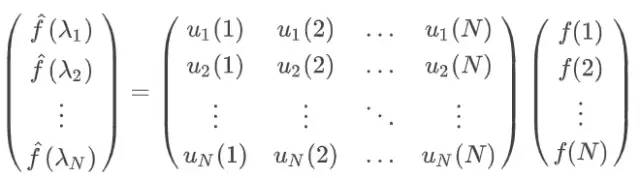
是Graph上第个节点的特征向量,可得Graph上的傅里叶变换形式。
此处的是Graph的拉普拉斯矩阵的特征向量组成的特征矩阵的转置,在拉普拉斯矩阵的优良性质中我们知道拉普拉斯矩阵的特征向量组成的矩阵为正交阵,即满足,所以Graph的逆傅里叶变换形式为,矩阵形式如下:
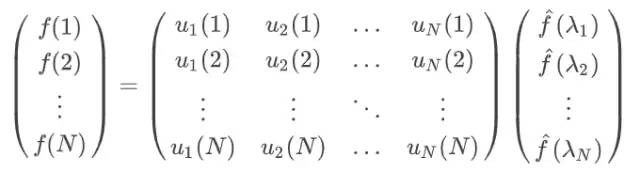
到此为止我们已经通过类比从传统的傅里叶变换推广到了Graph上的傅里叶变换。接下来我们就要借助傅里叶变换这个桥梁使得Convolution与Graph把酒言欢了。
卷积与GCN
在前言中我们了解了大名鼎鼎的卷积定理:函数卷积的傅里叶变换是其傅里叶变换的乘积,即对于f(t)与h(t),两者的卷积是其傅里叶变换的逆变换:

我们把上一节中得到的Graph上的傅里叶变换公式代入得到:

其中 
我们一般将

至此,我们已经推导出来GCN的雏形。
GCN的进阶之路
(1)第一代GCN
卷积操作的核心是由可训练且参数共享的卷积核,所以第一代GCN是直接把上式中的


所以第一代GCN就变成了酱个样子:


第一代GCN的缺点也是显而易见的,主要有以下几点,

需要对拉普拉斯矩阵进行特征分解,每次前向传播的过程中都要计算矩阵乘法,当Graph规模较大时,时间复杂度为
,非常耗时。
卷积核的个数为
,因此当Graph中节点的个数
很大时,节点特征更新缓慢。


(2)第二代GCN
面对第一代GCN参数过多的缺点,第二代GCN进行了针对性的改进。由于Graph上的傅里叶变换是关于特征值的函数


将其代入到

可以得到:


所以第二代GCN是介个样子:

可以看出二代GCN的最终化简结果不需要进行矩阵分解,直接对拉普拉斯矩阵进行变换。参数是


另外我们知道对于一个矩阵的k次方,我们可以得到与中心节点k-hop相连的节点,即
(3)用切比雪夫多项式展开近似图卷积核
在二代GCN的基础上用ChebShev多项式展开对图卷积核进行近似,即令

切比雪夫多项式的递归定义为:

用切比雪夫多项式近似图卷积核有两个好处:
卷积核的参数从原先一代GCN中的n个减少到k个,从原先的全局卷积变为现在的局部卷积,即将距离中心节点k-hop的节点作为邻居节点。
通过切比雪夫多项式的迭代定义降低了计算复杂度。
因此切比雪夫图卷积公式为:

手把手教你构建基于Tensorflow的ChebNet模型教程:
https://github.com/wangyouze/GNN-algorithms
(4)呱呱坠地的GCN
上面啰嗦那么多就是为了等待GCN的呱呱坠地。GCN是在ChebNet的基础上继续化简得到的。
ChebNet的卷积公式为:
令K=1,即只使用一阶切比雪夫多项式。
此时:

由切比雪夫多项式的迭代定义我们知道:

所以:

令:

则:

上式:

又L 是对称归一化的拉普拉斯矩阵,即:

因此上式:




再令


如果我们令:

则:

将其推广到矩阵形式则得到我们耳熟能详的GCN卷积公式:
谱域卷积VS空域卷积
(1)在谱域图卷积中,我们对图的拉普拉斯矩阵进行特征分解。通过在傅里叶空间中进行特征分解有助于我们我们理解潜在的子图结构。ChebNet, GCN是使用谱域卷积的典型深度学习架构。
(2)空域卷积作用在节点的邻域上,我们通过节点的k-hop邻居来聚合得到节点的特征表示。空域卷积相比谱域卷积更加简单和高效。GraphSAGE和GAT 是空域卷积的典型代表。
本教程(属于系列教程《GNN-algorithms》)Github链接:
https://github.com/wangyouze/GNN-algorithms
参考文献
https://www.zhihu.com/question/54504471/answer/332657604
http://xtf615.com/2019/02/24/gcn/
https://blog.csdn.net/yyl424525/article/details/100058264
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GNNWYZ” 可以获取《《图卷积网络(GCN)的前世今生》》专知下载链接索引




